OAC 18.3.3: New Features

I believe there is a hidden strategy behind Oracle's product release schedule: every time I'm either on holidays or in a business trip full of appointments a new version of Oracle Analytics Cloud is published with a huge set of new features!

OAC 18.3.3 went live last week and contains a big set of enhancements, some of which were already described at Kscope18 during the Sunday Symposium. New features are appearing in almost all the areas covered by OAC, from Data Preparation to the main Data Flows, new Visualization types, new security and configuration options and BIP and Essbase enhancements. Let's have a look at what's there!
Data Preparation
A recurring theme in Europe since last year is GDPR, the General Data Protection Regulation which aims at protecting data and privacy of all European citizens. This is very important in our landscape since we "play" with data on daily basis and we should be aware of what data we can use and how.
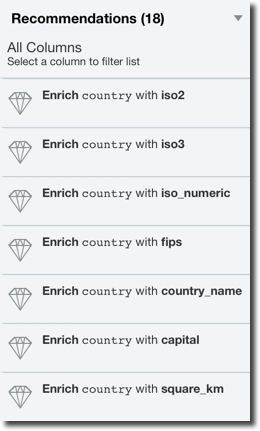
Luckily for us now OAC helps to address GDPR with the Data Preparation Recommendations step: every time a dataset is added, each column is profiled and a list of recommended transformations is suggested to the user. Please note that Data Preparation Recommendations is only suggesting changes to the dataset, thus can't be considered the global solution to GDPR compliance.
The suggestion may include:
- Complete or partial obfuscation of the data: useful when dealing with security/user sensitive data
- Data Enrichment based on the column data can include:
- Demographical information based on names
- Geographical information based on locations, zip codes
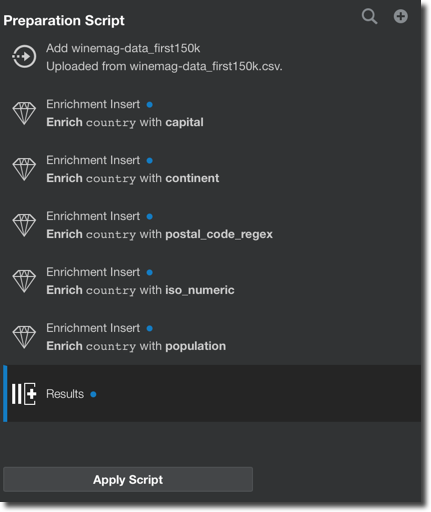
Each of the suggestion applied to the dataset is stored in a data preparation script that can easily be reapplied if the data is updated.
Data Flows
Data Flows is the "mini-ETL" component within OAC which allows transformations, joins, aggregations, filtering, binning, machine learning model training and storing the artifacts either locally or in a database or Essbase cube.
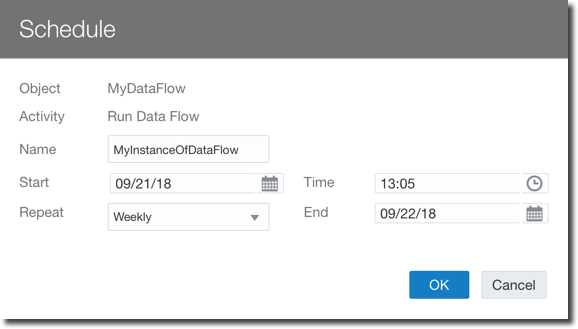
The dataflows however had some limitations, the first one was that they had to be run manually by the user. With OAC 18.3.3 now there is the option to schedule Data Flows more or less like we were used to when scheduling Agents back in OBIEE.
Another limitation was related to the creation of a unique Data-set per Data Flow which has been solved with the introduction of the Branch node which allows a single Data Flow to produce multiple data-sets, very useful when the same set of source data and transformations needs to be used to produce various data-sets.
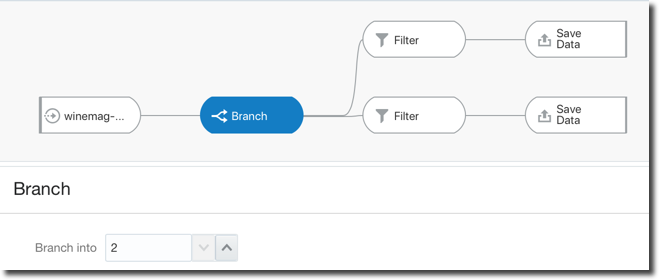
Two other new features have been introduced to make data-flows more reusable: Parametrized Sources and Outputs and Incremental Processing.
The Parametrized Sources and Outputs allows to select the data-flow source or target during runtime, allowing, for example, to create a specific and different dataset for today's load.
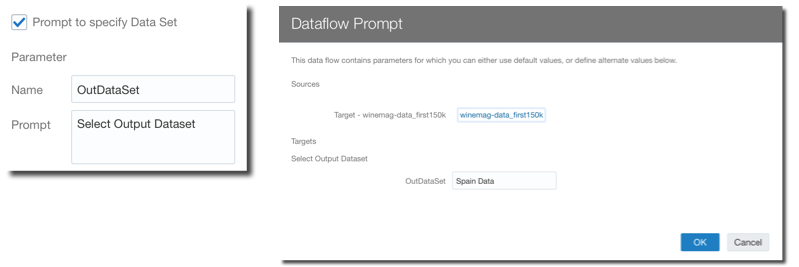
The Incremental Processing, as the name says, is a way to run Data Flows only on top of the data added since the last run (Incremental loads in ETL terms). In order to have a data flow working with incremental loads we need to:
- Define in the source dataset which is the key column that can be used to indicate new data (e.g.
CUSTOMER_KEYorORDER_DATE) since the last run - When including the dataset in a Data Flow enable the execution of the Data Flow with only the new data
- In the target dataset define if the Incremental Processing replaces existing data or appends data.
Please note that the Incremental Load is available only when using Database Sources.
Another important improvement is the Function Shipping when Data Flows are used with Big Data Cloud: If the source datasets are coming from BDC and the results are stored in BDC, all the transformations like joining, adding calculation columns and filtering are shipped to BDC as well, meaning there is no additional load happening on OAC for the Data Flow.
Lastly there is a new Properties Inspector feature in Data Flow allowing to check the properties like name and description as well as accessing and modifying the scheduling of the related flow.
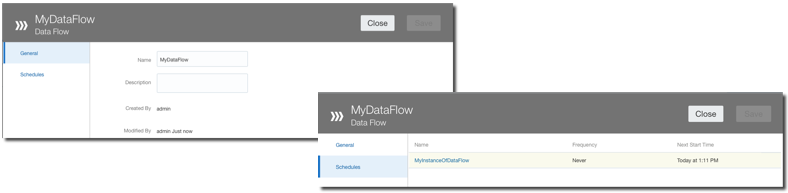
Data Replication
Now is possible to use OAC to replicate data from a source system like Oracle's Fusion Apps, Talend or Eloqua directly into Big Data Cloud, Database Cloud or Data Warehouse Cloud. This function is extremely useful since allows decoupling the queries generated by the analytical tools from the source systems.
As expected the user can select which objects to replicate, the filters to apply, the destination tables and columns, and the load type between Full or Incremental.
Project Creation
New visualization capabilities have been added which include:
- Grid HeatMap
- Correlation Matrix
- Discrete Shapes
- 100% Stacked Bars and Area Charts
In the Map views, Multiple Map Layers can now be added as well as Density and Metric based HeatMaps, all on top of new background maps including Baidu and Google.
Tooltips are now supported in all visualizations, allowing the end user to add measure columns which will be shown when over a section of any graph.
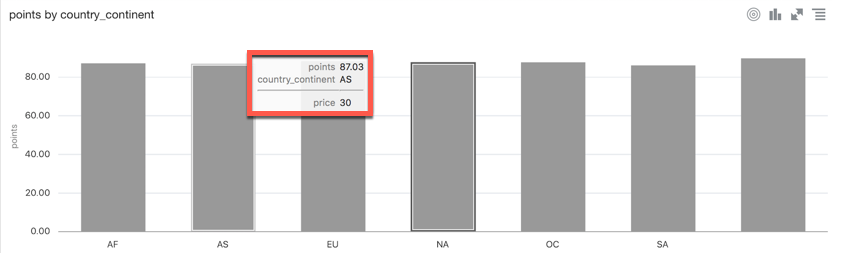
The Explain feature is now available on metrics and not only on attributes and has been enhanced: a new anomaly detection algorithm identifies anomalies in combinations of columns working in the background in asynchronous mode, allowing the anomalies to be pushed as soon as they are found.
A new feature that many developers will appreciate is the AutoSave: we are all used to autosave when using google docs, the same applies to OAC, a project is saved automatically at every change. Of course this feature can be turn off if necessary.
Another very interesting addition is the Copy Data to Clipboard: with a right click on any graph, an option to save the underline data to clipboard is available. The data can then natively be pasted in Excel.
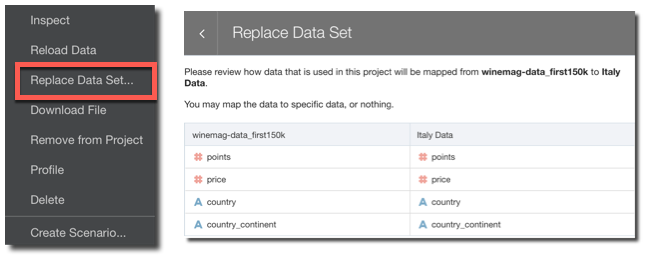
Did you create a new dataset and you want to repoint your existing project to it? Now with Dataset replacement it's just few clicks away: you need only to select the new dataset and re-map all the columns used in your current project!
Data Management
The datasets/dataflows/project methodology is typical of what Gartner defined as Mode 2 analytics: analysis done by a business user whitout any involvement from the IT. The step sometimes missing or hard to be performed in self-service tools is the publishing: once a certain dataset is consistent and ready to be shared, it's rather difficult to open it to a larger audience within the same toolset.
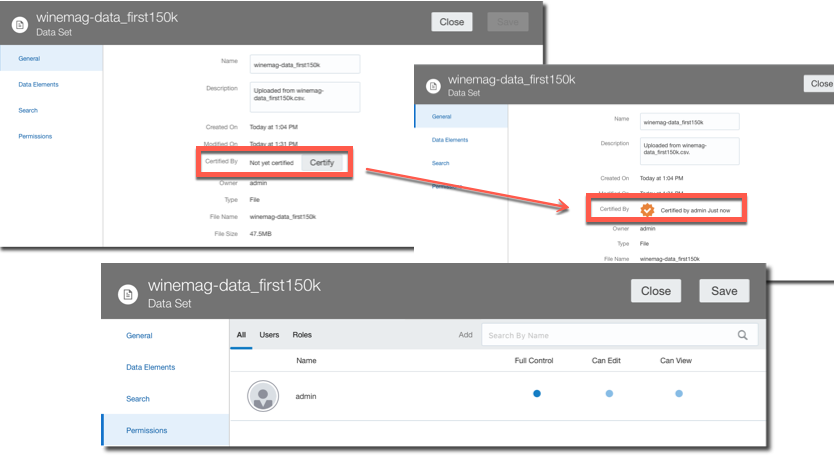
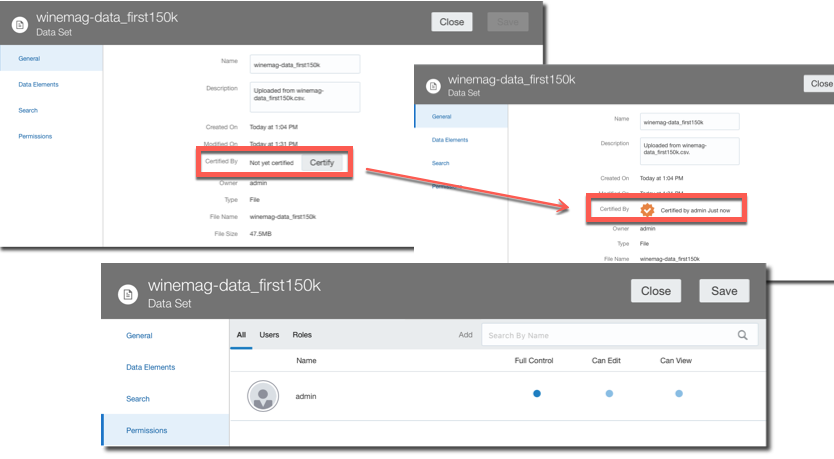
New OAC administrative options have been addressing this problem: a dataset Certification by an administrator allows a certain dataset to be queried via Ask and DayByDay by other users. There is also a dataset Permissions tab allowing the definition of Full Control, Edit or Read Only access at user or role level. This is the way of bringing the self service dataset back to corporate visibility.
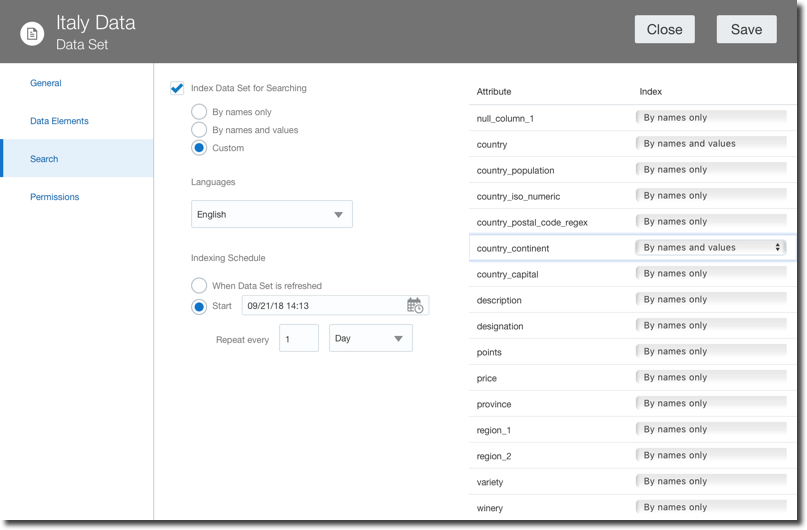
A Search tab allows a fine control over the indexing of a certain dataset used by Ask and DayByDay. There are now options to select when then indexing is executed as well as which columns to index and how (by column name and value or by column name only).
BIP and Essbase
BI Publisher was added to OAC in the previous version, now includes new features like a tighter integration with the datasets which can be used as datasources or features like email delivery read receipt notification and compressed output and password protection that were already available on the on-premises version.
There is also a new set of features for Essbase including new UI, REST APIs, and, very important security wise, all the external communications (like Smartview) are now over HTTPS.
For a detailed list of new features check this link
Conclusion
OAC 18.3.3 includes an incredible amount of new features which enable the whole analytics story: from self-service data discovery to corporate dashboarding and pixel-perfect formatting, all within the same tool and shared security settings. Options like the parametrized and incremental Data Flows allows content reusability and enhance the overall platform performances reducing the load on source systems.
If you are looking into OAC and want to know more don't hesitate to contact us