The Importance of Feature Engineering and Selection

In machine learning your model is only ever as good as the data you train it on. As such a significant proportion of your effort should be focused on creating a dataset that is optimised to maximise the information density of your data. Feature engineering and selection are the methods used for achieving this goal.
In this context, the definition of a feature will be a column or attribute of the data.
Feature engineering is a broad term that covers a number of manipulations that may be carried out on your dataset. There are therefore many processes that could be considered part of feature engineering. In this post I introduce some of the high-level activities carried out as a part of feature engineering, as well as, some of the most common methods of feature selection, but this is by no means an exhaustive list.
Engineering Features
Feature engineering is the process by which knowledge of data is used to construct explanatory variables, features, that can be used to train a predictive model. Engineering and selecting the correct features for a model will not only significantly improve its predictive power, but will also offer the flexibility to use less complex models that are faster to run and more easily understood.
At the start of every machine learning project the raw data will be inevitably messy and unsuitable for training a model. The first step is always data exploration and cleaning, which involves changing data types and removing or imputing missing values. With an understanding of the data gained through exploration, it can be prepared in such a way that it is useful for the model. This may include removing outliers or specific features you don’t want the model to learn; as well as creating features from the data that better represent the underlying problem, facilitating the machine learning process and resulting in improved model accuracy.
Unprocessed data will likely contain features with the following problems:
| Issue | Solution |
|---|---|
| Missing values | Imputed in data cleaning |
| Does not belong to the same dimension | Normalisation/standardisation |
| Information redundancy | Filtered out in feature selection |
Decomposing or Splitting Features
One form of feature engineering is to decompose raw attributes into features that will be easier to interpret patterns from. For example, decomposing dates or timestamp variables into a variety of constituent parts may allow models to discover and exploit relationships. Common time frames for which trends occur include: absolute time, day of the year, day of the week, month, hour of the day, minute of the hour, year, etc. Breaking dates up into new features such as this will help a model better represent structures or seasonality in the data. For example, if you were investigating ice cream sales, and created a “Season of Sale” feature, the model would recognise a peak in the summer season. However, an “Hour of Sale” feature would reveal an entirely different trend, possibly peaking in the middle of each day.
Your data can also be binned into buckets and converted into factors (numerical categories) or flattened into a column per category with flags. Which of these will work best for your data depends on a number of factors including how many categorical values you have, and their frequency. (A similar process can be utilised for natural language processing or textual prediction see bag of words.)
Data Enrichment
Data enrichment is the process of creating new features by introducing data from external sources. Externally collated data is invaluable in prediction success, there is a plethora of publicly accessible datasets that will in most situations create impactful features.
Third party datasets could include attributes that are challenging or costly to collect directly; or are possibly more accurately available online.
It is important when enriching a dataset to consider the relevance of sources, as irrelevant features will unnecessarily complicate the model adding to the noise and increasing the chance of overfitting. For example, when working with dates it is generally insightful to introduce data on national holidays. In the case of our ice cream sales example, you may want to include national holidays, temperature and weather features, as these would be expected to influence sales. However, adding temperature or weather data from another country or other areas will definitely not be relevant and will in the best case have no relation to the data, but in the worst case have a spurious correlation and mislead the model when training.
Feature Transformations
Feature transformations can include aggregating or combining attributes to create new features. Useful and relevant features will depend on the problem at hand but averages, sums and ratios over different groupings can better expose trends to a model.
Multiplying or aggregating features to create new combined features can help with this. Categorical features can be combined into a single feature containing all combination of the two categories. This can easily be overdone and it is necessary to be careful as to not overfit due to misleading combined features.
It is possible to identify higher order interactions via a simple decision tree, the initial branches can be used to identify which features to combine.
A general requirement for some machine learning algorithms is standardisation/normalisation. This rescales the features so they represent a standard normal distribution (centred around 0 with a standard deviation of 1). The benefits of standardisation are that you do not emphasise variables with larger magnitudes and when comparing measurements with different units.
Automated Feature Engineering
Engineering features manually as described above can be very time consuming and requires a good understanding of the underlying data, structures in the data, the problem you are trying to solve and how best to represent the data to have the desired effect. Manual feature engineering is problem specific and cannot be applied to another dataset or problem.
There has been some progress made in the automation of feature engineering. FeatureTools for example is a python framework for transforming datasets into feature matrices. In my opinion there are positives and negatives to such an approach Feature engineering is time-consuming and any automation of this process would be beneficial. However, creating many useless features will lead to overfitting and automatically created features can result in loss of interpretability and understanding.
Feature Selection
Of the features now available in your data set, some will be more influential than others on the model accuracy. Feature selection aims to reduce the dimensionality of the problem by removing redundant or irrelevant features. A feature may be redundant if it is highly correlated with another feature, but does so because it is based on the same underlying information. These types of features can be removed from the data set without any loss of information. In our ice cream example, sales may be correlated with temperature and suncream usage, but the relationship with suncream is a result of this also being correlated with the confounding variable temperature.
Reducing the number of features through feature selection ensures training the model will require less memory and computational power, leading to shorter training times and will also help to reduce the chance of overfitting. Simplification of the training data will also make the model easier to interpret, which can be important when justifying real-world decision making as a result of model outputs.
Feature Selection Methods
Feature selection algorithms rank or score features based on a number of methods so that the least significant features can be removed. In general, the features are chosen from two perspectives; feature divergence and correlations between features and the dependent variable (the value being predicted). Some models have built-in feature selections, that aim to reduce or discount features as part of the model building process, for example LASSO Regression.
Methods that can be used to reduce features include:
Correlation
A feature that is strongly correlated with the dependent variable may be important to the model. The correlation coefficients produced are univariate and therefore only correspond to each individual feature’s relationship to the dependent variable, as opposed to combinations of features.
Near Zero Variance
Depending on the problem you are dealing with you may want to remove constant and almost constant features across samples. There are functions that will remove these automatically such as nzv() in R. They can be tuned from removing only features which have a single unique value across all samples or those that have a few unique values across the set, to those with a large ratio of the most common value to the second most common.
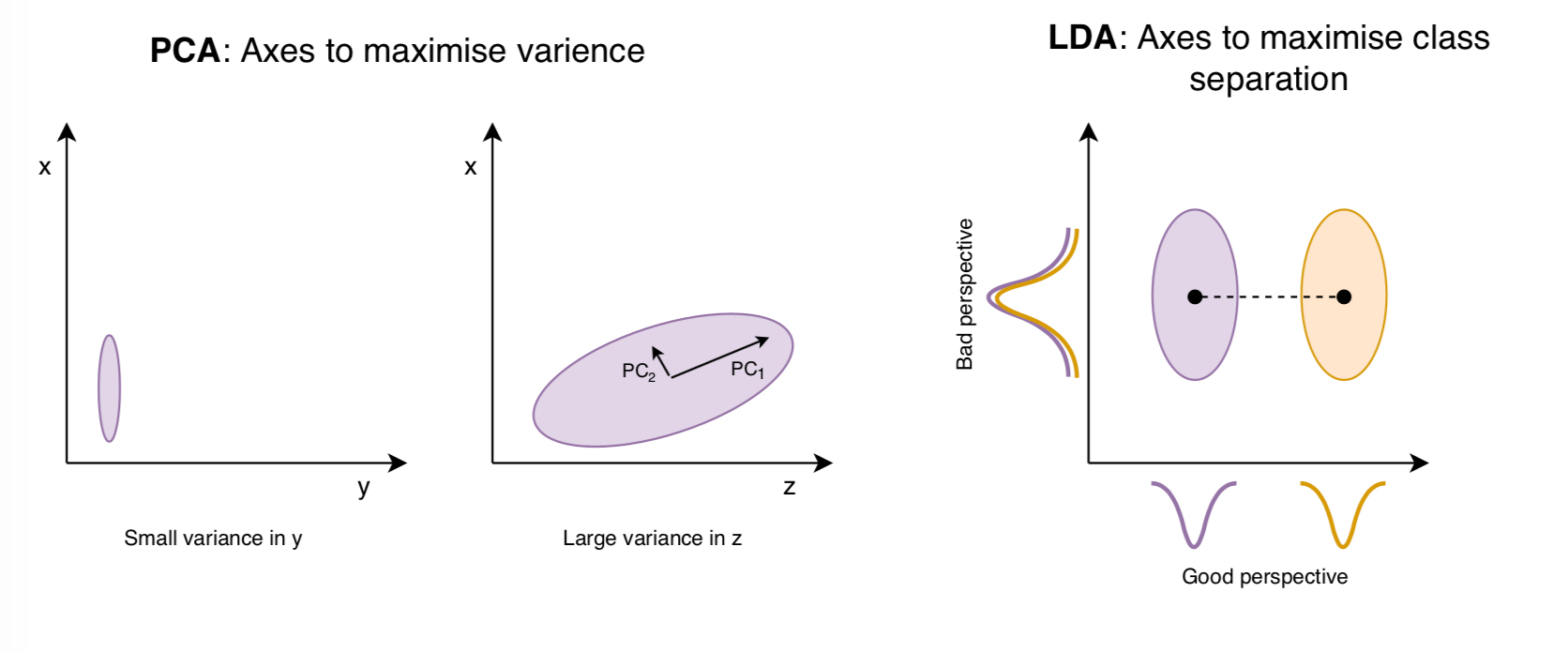
Principal component analysis (PCA)
PCA is an unsupervised dimensionality reduction method, its purpose is to find the directions (the so-called principal components) in feature space that maximise the variance in the dataset. You are essentially finding the axes of feature space that are intuitive to the shape of the data, where there is the greatest variation, and therefore the most information. A very simple example would be a 3D feature space of x, y, z. If you look at the data through the x,y axis and all of your points were tightly clustered together this would not be a very good axis to view your data structure though. However, if you viewed it in the x, z plane and your data was spread out, this would be much more useful as you are able to observe a trend in the data. Principal components are dimensions along which your data points are most spread out, but as opposed to the example above, feature space will have n-dimensions not 3, and a principal component can be expressed a single feature or as a combination of many existing features.
Linear discriminant analysis (LDA)
LDA is a supervised dimensionality reduction method, using known class groupings. It achieves a similar goal to PCA, but instead of finding the axes that maximise the variance, it will represent the axes that maximise the separation between multiple classes. These are called linear discriminants.
For multi-class classification, it would be assumed that LDA would achieve better results than PCA, but this is not always the case.
Summary
The features in your data will influence the results that your predictive model can achieve.
Having and engineering good features will allow you to most accurately represent the underlying structure of the data and therefore create the best model.
Features can be engineered by decomposing or splitting features, from external data sources, or aggregating or combining features to create new features.
Feature selection reduces the computation time and resources needed to create models as well as preventing overfitting which would degrade the performance of the model. The flexibility of good features allows less complex models, which would be faster to run and easier to understand, to produce comparable results to the complex ones.
Complex predictive modelling algorithms perform feature importance and selection internally while constructing models. These models can also report on the variable importance determined during the model preparation process. However, this is computationally intensive and by first removing the most obviously unwanted features, a great deal of unnecessary processing can be avoided.