Machine Learning Collaboration with Oracle Data Science
A deep look at Oracle Data Science and the AutoML Capabilities

This week I was sadly forced to skip my planned trip to OOW London in which Rittman Mead had a fantastic booth and Jon Mead presented the "How to Become a Data Scientist" session with Oracle Analytics Cloud and Oracle Machine Learning.
@jonmead prepped and primed to deliver @FTisiot’s How To Become A Data Scientist presentation. Get down to Zone 4! #OOWLON #DataScience pic.twitter.com/BRFobFuTX0
— RittmanMead (@rittmanmead) February 12, 2020
The last-minute plan change, however, gave me time to test a new product just being available in the Oracle Cloud: Oracle Data Science! I've been talking about the tool been announced in my OOW19 Review post describing it as a Data Science collaboration tool coming from the acquisition of DataScience.com, let's have a look in detail at the first release.
Instance Creation
Oracle Data Science can be found in the OCI console, under the Data and AI section with other products including the newly released Data Catalog and Data Flow
Before starting creating a Data Science Project, you'll need to review some security and policy settings which are well described in this blog post. Those settings are not straightforward, but once in place, we can then create a Project, where a team can collaborate. All we need to define is the compartment name, the project name and description.
After creating the project, is time to create one (or more) Notebook Sessions within the project. In here we need to specify the compartment (the same as the project), the name of the notebook session, the shape (choosing between a pre-defined list of shapes), the size of the block storage and the networking details.
If all the security and policy settings are working we'll have the notebook instance created in minutes
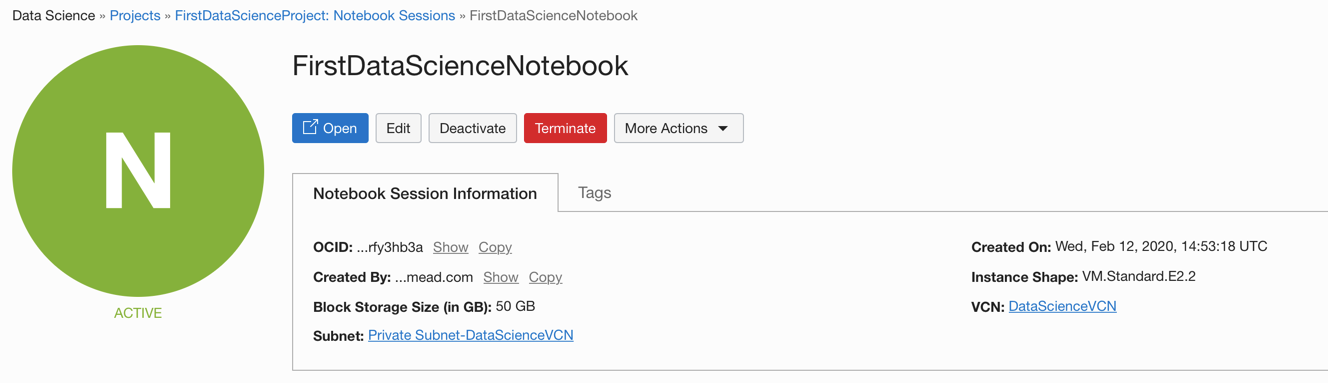
We can then click on Open to enter the notebook itself.
What's in the Notebook
What we see immediately is that Data Science is based on instantiated images of jupyter notebooks including Python 3. Data Science Notebooks can also be version-controlled with a pre-built git integration and contain all the best python open source ML libraries like TensorFlow, Keras, SciKit-Learn, and XGBoost as well as the common visualization ones like Plotly and Matplotlib. The terminal access also means that we have the freedom to install any other custom library we might be interested in.
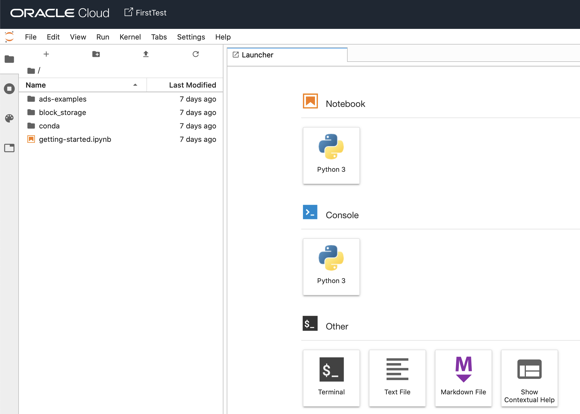
We can now create a Python notebook and start solving out ML problems.
Pro-Tip: move all notebooks and data under the folder /block_storage otherwise you'll lose the content when stopping and starting the notebook.
Oracle Accelerated Data Science (ADS) SDK
A new feature coming with Oracle Data Science is also the Accelerated Data Science (ADS) SDK: a python library simplifying and accelerating the data science process by offering a set of methods that covers all the phases of the process, from data acquisition to model creation, evaluation and interpretation.
The first step to use the SDK is to import the related libraries
from ads.dataset.factory import DatasetFactory
from ads.dataset.dataset_browser import DatasetBrowserThen we can import the data and define pointsCat as our target column
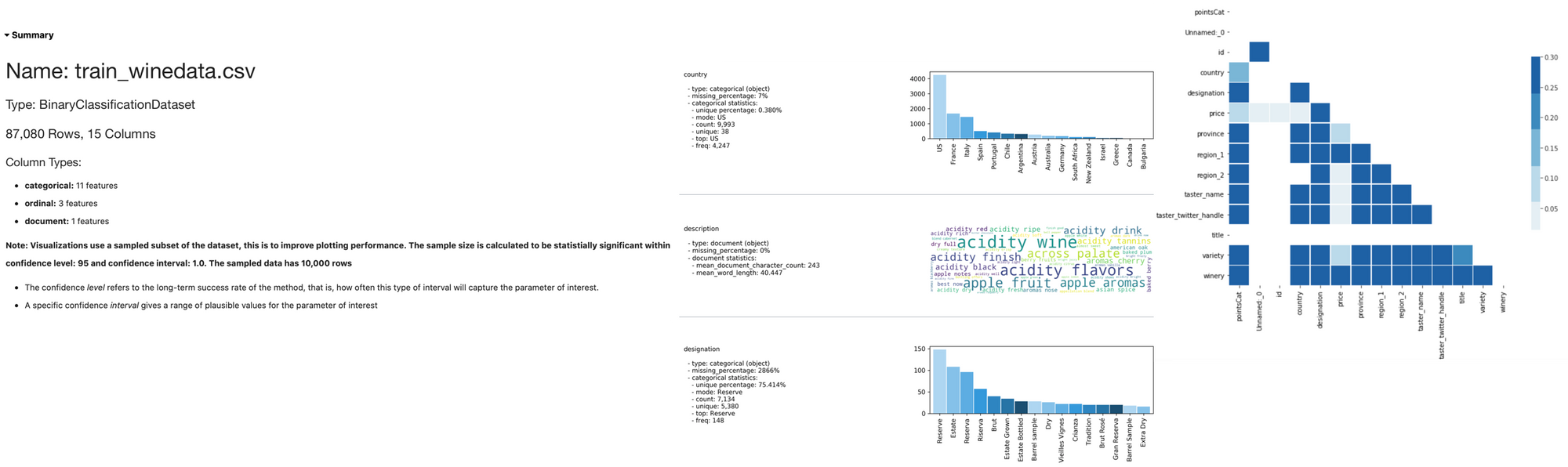
df=DatasetFactory.open("Data/train_winedata.csv", target="pointsCat")Immediately after importing, the library will suggest to use two methods: show_in_notebook() and get_recommendations(). Let's execute them!
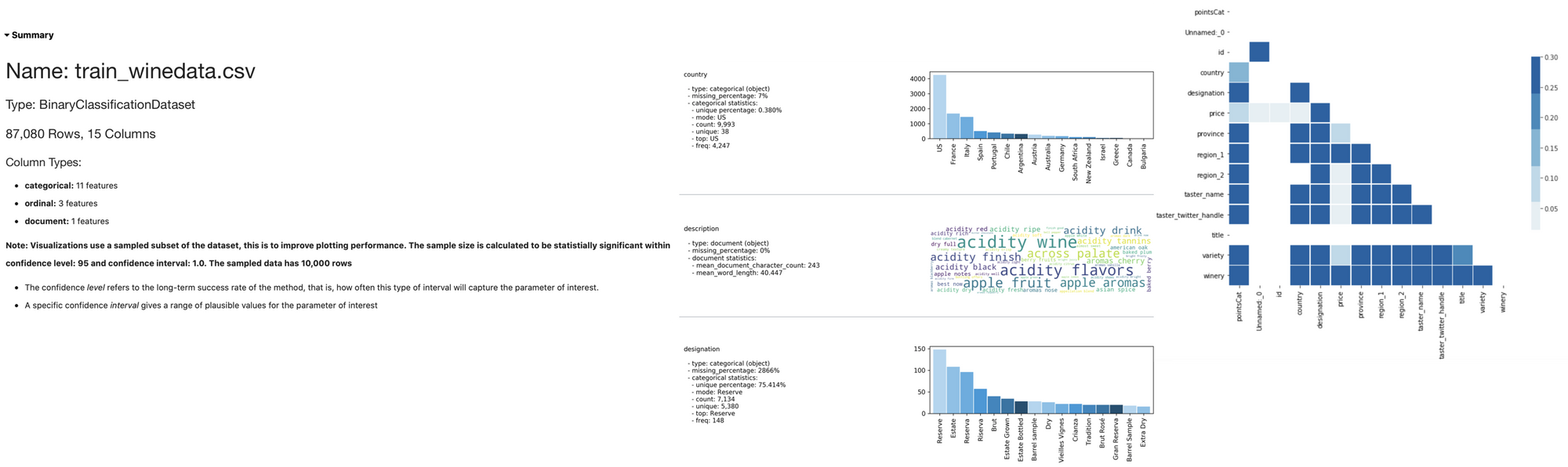
df.show_in_notebook()This function creates a series of sections enabling us to understand better the dataset. The sections include a Summary expressing the overall features of the dataset, then for each Feature, a dedicated chart will represent the distribution. The Correlation tab shows the similarity between features and finally, the Data tab shows examples of the dataset.
The next step to try is the get_recommendations() which generates few interesting suggestions to transform our dataset. The function shows which are the primary columns that should be deleted, suggestions on how to handle missing values and features with strong correlation, lastly allows the identification of the positive label for the target.
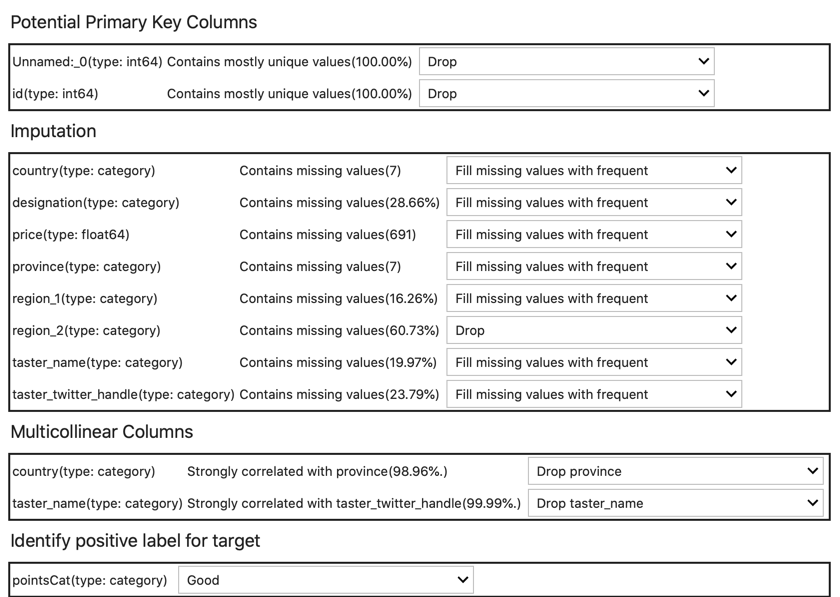
The end-user can keep or change any of the values proposed and apply the transformations. Please note that the original object is not modified, to get the transformed object we need to call
wine_transformed=df.get_transformed_dataset()If we don't want to go through all the transformations we can rely on ADF to chose the best for us by calling the auto_transform() function which will implement all the transformations suggested before with the default parameters. If we want to have a look at what transformations have been processed by the auto_transform(), we can call the visualize_transforms() function which will show the pipeline in an image similar to the below
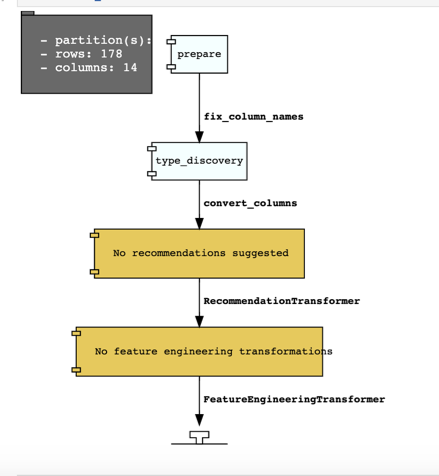
Next step is to create a predictive model, again with the SDK is just a few lines of code away
from ads.dataset.factory import DatasetFactory
from ads.automl.provider import OracleAutoMLProvider
from ads.automl.driver import AutoML
from ads.evaluations.evaluator import ADSEvaluator
ml_engine = OracleAutoMLProvider(n_jobs=-1, loglevel=logging.ERROR)
oracle_automl = AutoML(wine_transformed, provider=ml_engine)
automl_model1, baseline = oracle_automl.train()The SDK will now start testing a few ML algorithms to find the one providing the best results. At the end of the execution, it'll show a summary output like the following which includes also the Selected Algorithm which is the ML model having the best score.

For each of the ML algorithms tried, the SDK will also show some summary stats that can be used to evaluate all the models.
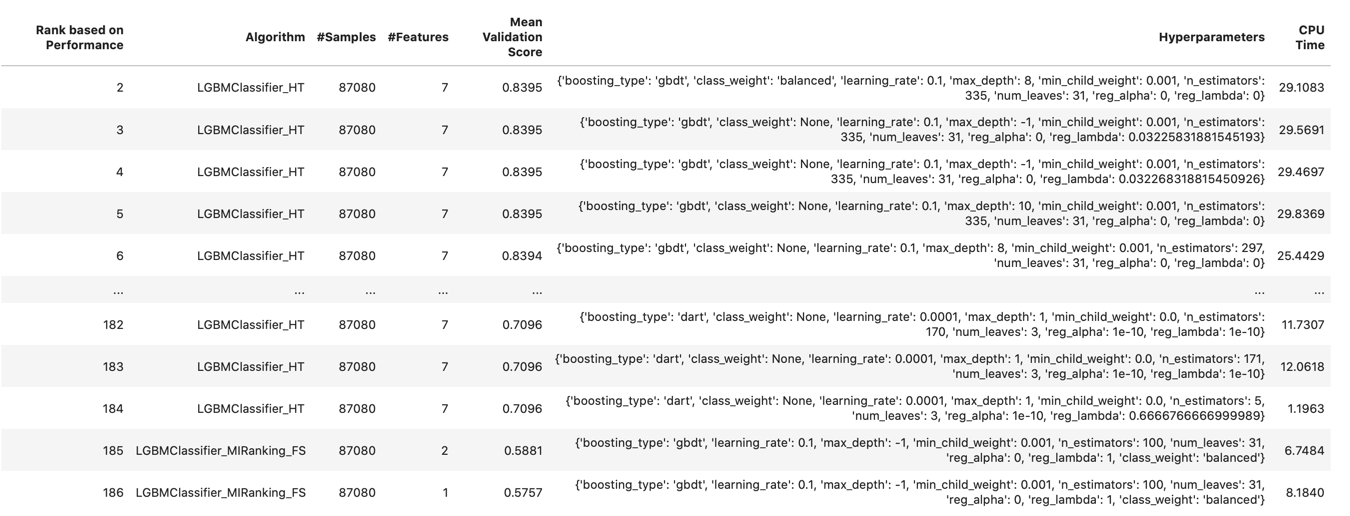
We can reprint the models anytime passing the number of rows to visualize and the sort order as parameters with the following call
oracle_automl.print_trials(max_rows=20, sort_column='Mean Validation Score')And have a graphical representation of why a certain algorithm was selected by calling the visualize_algorithm_selection_trials() function.
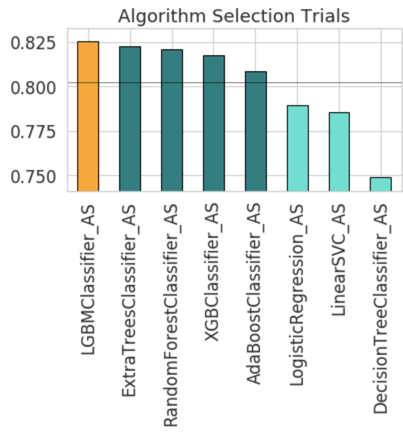
ADS has similar calls to check the sampling size (visualize_adaptive_sampling_trials()) and the features selected (visualize_feature_selection_trials()). These functions can take a while to execute, probably due to the first version of the SDK.
The model train function accepts optional parameters such as:
- if we are interested in just trying out a specific model (or models) we can pass it via
model_list=['LogisticRegression'] - to change the scoring function we use
score_metric='f1_macro' - to give a hint about the amount of time to spend on training we pass
time_budget=10 - we can specify which features we want always to be included with
min_features=['price', 'country'])
Once created the models, we can then evaluate them with
evaluator = ADSEvaluator(test_wine, models=[automl_model1, baseline],
training_data=wine_transformed, positive_class='Good')
evaluator.show_in_notebook(plots=['normalized_confusion_matrix'])
evaluator.metricswhich results being

The ADF also contains functions for model explainability, but the ones available in v1 don't seem to work well, all the trials done as of now are stopping against errors in the code.
Once we identified the model, it's time to save it, we can do it via
from ads.catalog.model import ModelSummaryList, ModelCatalog
from ads.catalog.project import ProjectSummaryList, ProjectCatalog
from ads.catalog.summary import SummaryList
from ads.common.model_artifact import ModelArtifact
path_to_model_artifact = "/home/datascience/block_storage/my_model"
model_artifact = automl_model1.prepare(path_to_model_artifact, force_overwrite=True)The prepare function will create several files within the chosen directory that describes the model, once done, we can store the model in the catalog with the following
import os
compartment_id = os.environ['NB_SESSION_COMPARTMENT_OCID']
project_id = os.environ["PROJECT_OCID"]
# Saving the model artifact to the model catalog:
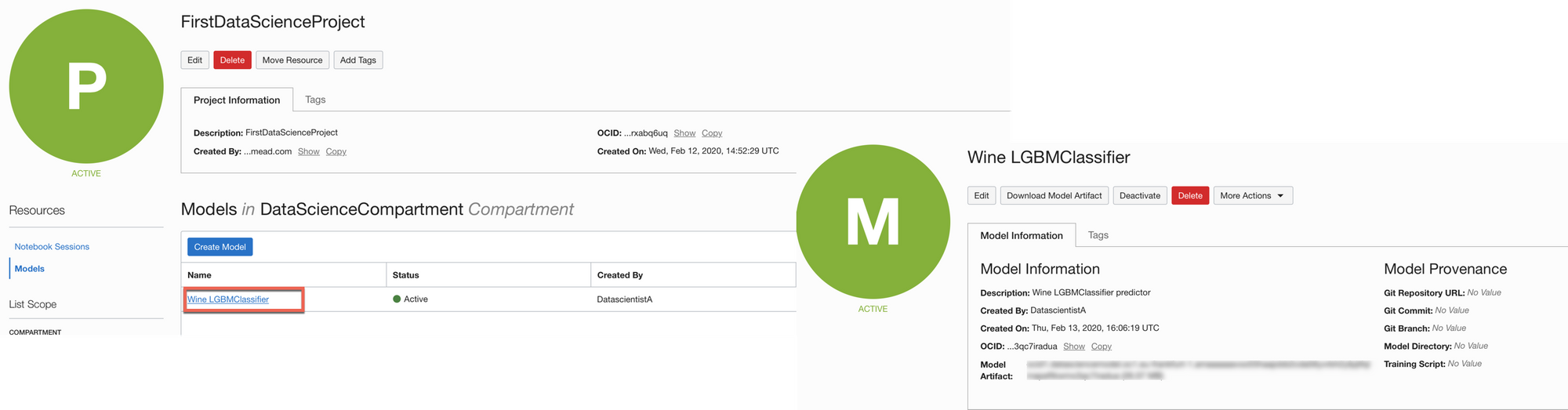
mc_model = model_artifact.save(project_id=project_id, compartment_id=compartment_id, display_name="Wine LGBMClassifier",
description="Wine LGBMClassifier predictor", training_script_path="Training.ipynb", ignore_pending_changes=True)Please note that this step will fail, if you didn't configure the ADF SDK to access the OCI APIs, a separate post is coming covering this step. If on the other side, all the setup is correctly done, the Model is then visible within the Data Science Project Page
The model can now be downloaded and used by others, we can also think about exposing it as function and call it via REST APIs, all possible with the help of the ADS SDK as mentioned in the documentation.
A New Ecosystem for Data Science Collaboration
Oracle Data Science is an interesting product and covers a missing piece in Oracle's AI strategy. As of now the user experience is a bit rough on the edges both during provisioning, with the policy configuration as a required pre-step, and during utilization with some of the steps not working 100% of the times. This, however, is just the first release and we hope to have a speedy following set of new versions as already happening for all the other products in the Oracle cloud.