Data Virtualization: What is it About?
What is Data Virtualization? What are the components of a Data Virtualization tool? How can I provide Data Virtualization with Oracle tools?

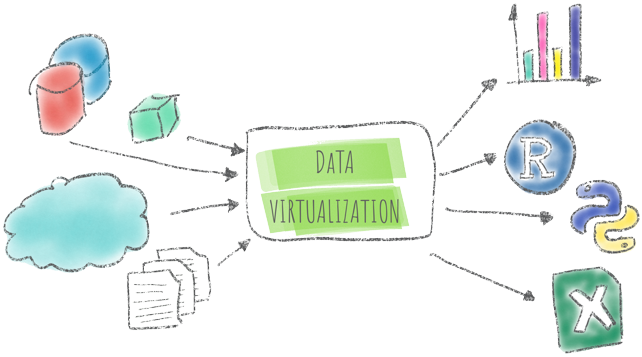
The fast growth of company's data, data-sources and data-formats is driving an increasing interest in the field of Data Virtualization; what is it about? And what tools can provide this functionality?
Data Virtualization defines an approach to expose data coming from disparate data sources via a common interface to downstream applications.
Do you have your sales data in an Oracle Database and client peculiar information in some Cloud App? Data Virtualization will show them as an unique data source while, in the backend, will fire the proper queries to source-systems, retrieve the data and apply the correct joining conditions. Data Virtualization abstracts the technical aspects of the datasources from the consumer. Unlike the ETL approach, there is no data copy or movement, with source systems accessed in real-time when the query is executed (also called Query in Place (QIP)).
To be clear: Data Virtualization is NOT a replacement of ETL, both paradigms are valid in specific use-cases. Data Virtualization is a perfect scenario when reduced amounts of data coming from various systems need to be joined and exposed. On the other side, when massive amounts of data need to be parsed, transformed and joined and data-retrieval speed is the key, then an ETL (or ELT) approach is still the way to go.
Data Virtualization Components?
So far we had a look at the theory and goals of Data Virtualization, but what are the main components of such a tool? We can summarize them in four main points in our source-to-user path: Data Access Optimization, Business Logic, Data Exposure and Security.
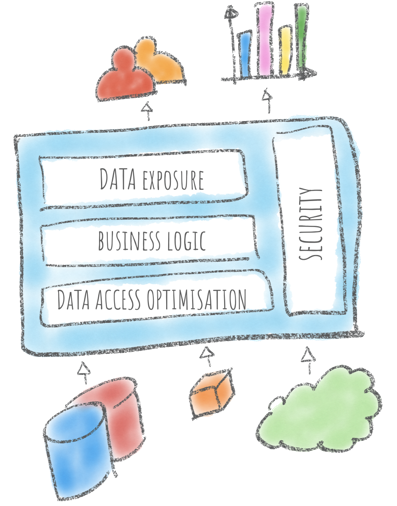
What should each layer do? Let's see them in detail.
Data Access Optimization
In this layer, the connection to data-sources needs to be defined, tuning parameters set and data-points of interest determinate. This query should be responsible for optimizing the query pushdown to source systems in order to retrieve the minimal row-set that needs to be displayed or joined with other datasources.
The Data Access Optimization layer should also be able to handle different datasources with different capabilities (e.g. aggregation functions) and, in case pushdown is not possible, perform transformations after data load. Finally, to ease the stress on the source system, caching options should be available in this layer.
This layer should also dictate the methodology of datapoints access, defining (with the help of the Security layer) if a certain column can be read-only or also written.
Business Logic

The Business Logic Layer should be responsible for translating data-points to company-defined metrics or attributes. Datapoints can come from various data-sources so it should also contain the definitions of joining conditions and data federations.
Metrics and attributes need to have aggregations and hierarchies defined in order to be used by downstream applications. Hierarchies can also help with vertical data federation, defining exactly the granularity of each datapoint, thus enabling query optimization when more aggregated datasources are available.
The Business Logic Layer is also responsible for decoupling Business Logic from datasources: when a change in a datasource happens (e.g. the creation of a datamart or a database vendor change) the metrics and attributes layout will not be altered, all the changes will happen in the Data Access Optimization and hidden in the Business Logic Layer definitions.
Data Exposure

The Data Exposure Layer is the one facing downstream applications or users, in this layer metrics and attributes should be organized in business-driven structures and made accessible via various methods like web-interfaces, ODBC, SOAP or REST.
Datapoints defined at this layer should contain business descriptions and be researchable via a data catalog allowing the re-usage of pre-built content.
Security

Exposing data to downstream applications needs to happen securely, thus datapoint access rules need to be defined. Data Virtualization systems should integrate with the company's Identity management tools to identify and dictate who can access any particular datapoint.
Security should not only work as ON/OFF, but also allow the access to subsets of data based on privileges: e.g. a country manager should only see data from his/her own country.
Security is not only about defining boundaries but also about auditing the correct access to data (GDPR?). Data virtualization systems should allow security evaluations or provide pre-built security checks.
Data Virtualization in Oracle
As you might understand, Data Virtualization is a new, hot and growing topic; what has Oracle to offer since there isn't an official Oracle Data Virtualization tool? Well, check the picture below:
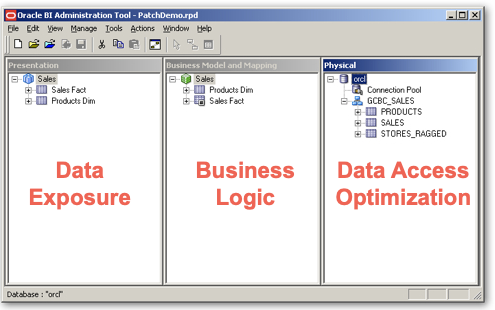
This is an Oracle Analytics repository (RPD)! A tool created in 1998, acquired by Oracle in 2007 and with a long history of successful implementations! The reality is that Data Virtualization is not a new topic (we talked about it in 2008), but simply an old capability, with a new name!
Oracle Analytics RPD's three-layer concept matches exactly the Data Access Optimization, Business Logic and Data Exposure layers mentioned above providing the same functionality. The Security is a key component across the whole Oracle Analytics Platform and successfully integrates with all major identity providers.
Oracle Analytics for Data Virtualization
Oracle Analytics is a tool born for data analytics but solves successfully the problem of Data Virtualization: data from different source systems can be queried, joined and exposed.
OA is capable of firing queries based on fields selected by the downstream application and optimized for the datasource selected. Query pushdown is enabled by default and specific datasource features can be turned ON/OFF via configuration files. Specific transformations can happen in OA's memory if the datasource doesn't allow the pushdown. Results of queries can be cached and served for faster response.
In scenarios where massive amounts of data need to be sourced, probably Oracle Big Data SQL or Cloud SQL could be used, pushing part of the virtualization at the database level.
Vertical and horizontal Data Federation can be defined, so data can span across various tables and aggregated datasources can be used for faster response. Metrics, attributes, hierarchies and joins are defined in the model thus related complexity is hidden from downstream applications.
Data exposed can be accessed via a web browser using the traditional Answers and Dashboard or the innovative Data Visualization. Data can also be extracted via SOAP APIs and via ODBC when the related component is exposed. Data Sources defined in Data Visualization and BI Publisher can also be extracted via REST APIs. There is a plan to extend JDBC access also to RPD defined Subject Areas.

A utility, called Metadata Dictionary, automatically generates a Data Catalog which can be used to expose and share what datapoints are available. In the future, Oracle Analytics Cloud datapoints will also be available via Oracle Data Catalog, a specific offering around this area.
The security included with the tool allows datapoint access definition to specific roles as well as limits on data exports size or access times. Security settings can be exported and audited via external tools. The platform usage can also easily be monitored for performance and security reasons.
Self-service Data Virtualization
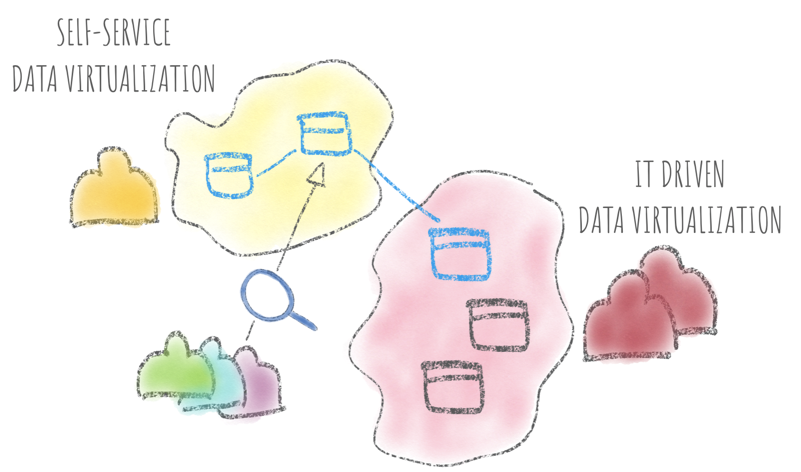
All we discussed so far describes the IT-driven Data Virtualization where the access to data is only managed by a restricted group of people (usually the IT department). Oracle Analytics enables it alongside Self-Service Data Virtualization, where new datasources, joins and security layers can be defined directly by Business Users enabling a faster and secure data sharing process which can still be audited and controlled.
Do you want to expose the business unit's forecast data in your Excel file alongside the revenue coming from your datamart? With Oracle Analytics this is only few clicks away including the security options controlling the audience.
Oracle Analytics offers both top-down and bottom-up approaches to Data Virtualization at the same time! IT-Driven, highly secured and controlled data-sources can coexist with user-defined ones. Joins and metadata models can be built from both sides and promoted to be visible by wider audience, all within one environment that can be tightly secured, controlled and audited.
Conclusion
Data Virtualization is a hot topic indeed, with the ever-increasing number of different datasources in a company's portfolio we'll see the rise of data abstraction layers. But don't look at new shiny tools to solve an old and common problem!
As described above, Oracle Analytics (Cloud or Server) can successfully be used in Data Virtualization contexts. Deployed in conjunction with Oracle Big Data SQL or Cloud SQL and Oracle Data Catalog offers an extremely compelling solution with a set of tools and knowledge already available in the majority of companies.