Analysing Social Media Activity with ADW and OAC
Analysing Twitter Activity using the Oracle Text features within the Oracle Database, Oracle Analytics Cloud and SQL Developer Web!


Yesterday I wrote a series of tweets talking about my Twitter activity analysis with Oracle's Autonomous Database and Oracle Analytics Cloud. Since the tweet became popular and I didn't share the steps, I thought a blog post should follow, so... here we are!
[1/N]
— Francesco Tisiot (@FTisiot) October 27, 2020
I wanted to analyse my Social Media data.
I exported my @Twitter data and analysed with the #OracleText in the #OracleAutonomousDatabase @OracleDatabase and @OracleAnalytics Cloud
Starting from the easy… which is the tweet with most likes?
hint: Becoming @oracleace #ACED! pic.twitter.com/gUQR0Ur7k7
Getting the Data from Twitter
There are many ways that you can get data from Twitter. For the sake of my exercise I requested a dump from my data from the Twitter website. You can request the same following these instructions.
Once the data is ready, you'll receive a mail or a notification and you'll be able to download the related zip file named twitter-YYYY-MM-DD-hashed_string.zip.
Once unzipped you'll see two folders:
assetscontaining files you attached in your tweets (mostly images)datawhere the actual interesting information is.

Within the data folder I concentrated on the tweet.js file which contains the tweet information. There are other interesting files such as followers.js or like.js but I didn't include those datasets in my analysis as of now.
Warning: the tweet.js dataset contains only the tweets written by you. It doesn't contain all people tagging you in a tweet or replies to your tweets.
The Your archive.html file allows you to browse the content on the folder from a web browser
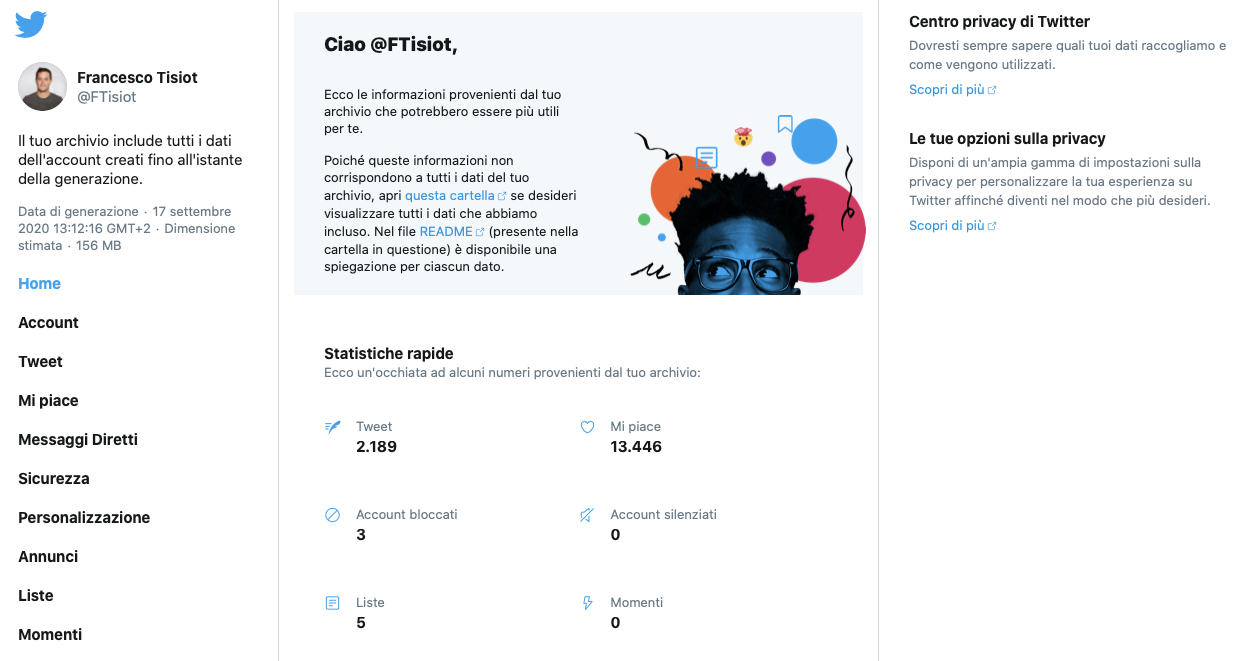
Importing Data into ADW with SQL Developer Web
The next step in my analysis is to import the data into the Autonomous Data Warehouse. For this task, I used SQLDeveloper Web, available by default in ADW, which has a powerful utility to import JSON documents as rows in a relational table. Jeff Smith's post covers the process in detail.
Unfortunately when trying to import into ADW the file tweet.js I encountered an error due to the fact that the file itself is not a pure JSON file, pretty clear if you check the file itself
window.YTD.tweet.part0 = [ {
"tweet" : {
"retweeted" : false,
"source" : "<a href=\"http://twitter.com/download/iphone\" rel=\"nofollow\">Twitter for iPhone</a>",
.....
"lang" : "en"
}
},
....
{
"tweet" : {
"retweeted" : false,
"source" : "<a href=\"http://twitter.com/download/iphone\" rel=\"nofollow\">Twitter for iPhone</a>",
.....
"lang" : "en"
}
}
]The first item to remove from our file is the window.YTD.tweet.part0 = prefix. I believe this is due to the pagination of the results, but it clearly screws up the JSON formatting.
Once removed I could parse the tweet.js file with SQLDeveloper Web, but the table definition proposed had only one column with containing the whole TWEET JSON document.
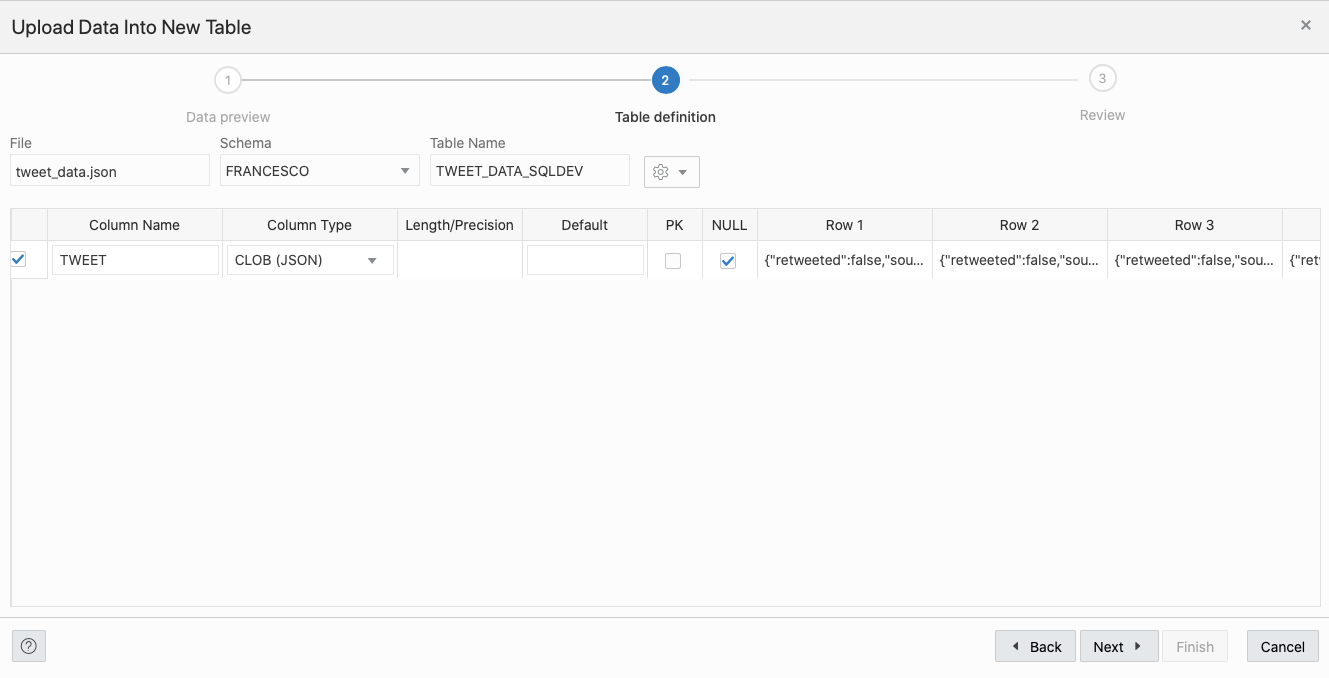
At this point, I could either accept this and do further processing using Oracle's SQL JSON parsing functionality or slightly change the shape of the file to be ingested correctly and I opted for the second.
When importing JSON documents into rows, SQLDeveloper Web analyses only the first level or attributes in the document itself. In the case of our tweet.js file was something like
{
"tweet" : {
...
}
},
{
"tweet" : {
...
}
},The first level parsed by SQL Developer Web was correctly only extracting the tweet element and proposing a CLOB (JSON) column to store it. But I wanted the content of the tweet to be parsed. I ended up removing the first layer by substituting in the file any occurrence of },{ "tweet" : { with a simple comma and removing the initial and final parenthesis.
The file now looks like the following
[ {
"id" : "279908827007180800",
"created_at" : "Sat Dec 15 11:20:39 +0000 2012",
"full_text" : "Finally at home after #christmasparty... Looooong travel!",
"lang" : "en"
...
}
,{
"id" : "276794944394498048",
"created_at" : "Thu Dec 06 21:07:12 +0000 2012",
"full_text" : "@mRainey will you be there next week too? Enjoy uk and visit #italy if you can!",
"lang" : "en",
...
}
...
}]We can now parse the file with SQL Developer Web, and the output correctly identifies all the first level entities in the JSON document.
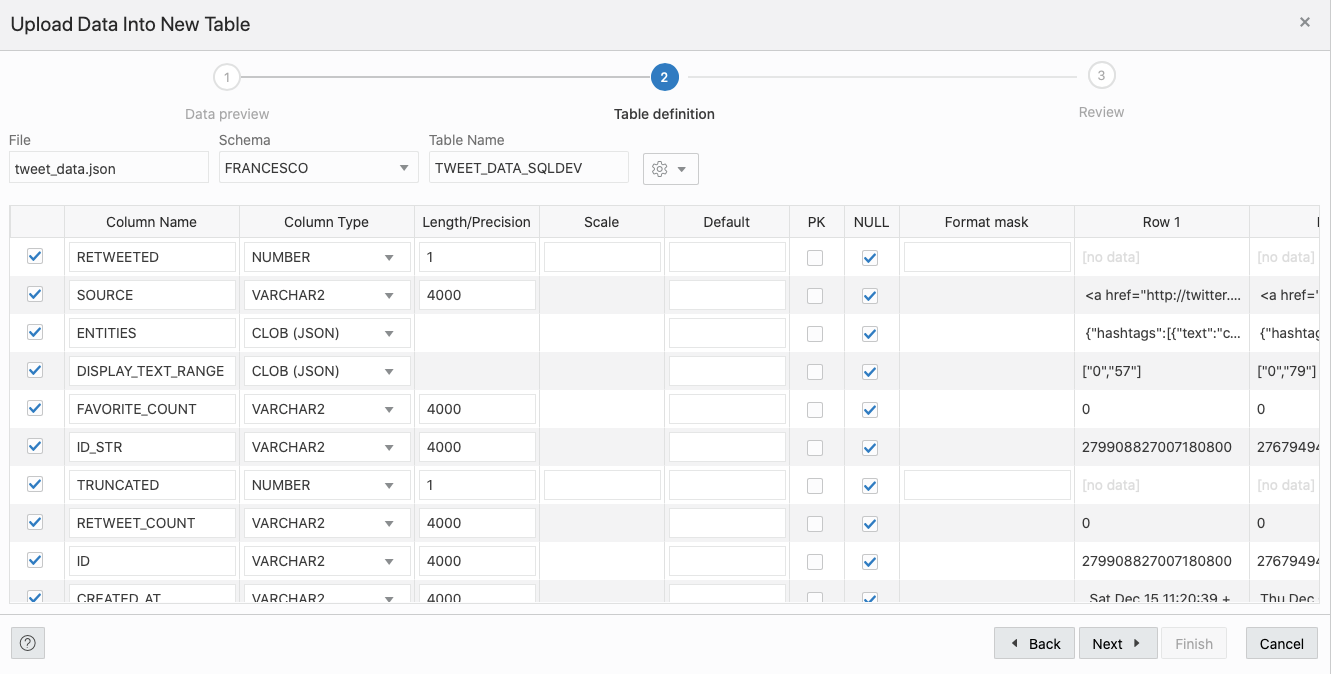
Few more clicks and we have our table FRANCESCO.TWEET_DATA_SQLDEV populated automagically!
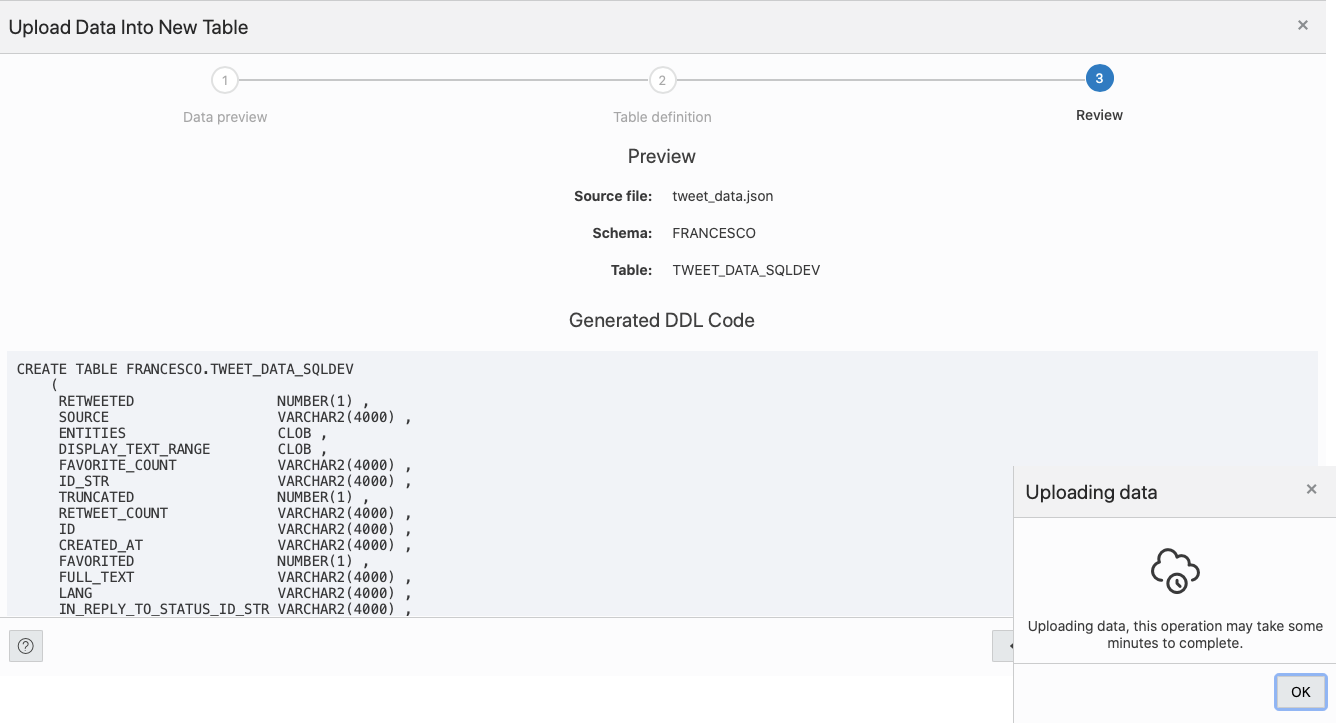
Note: The whole process above could be implemented and automated in several different ways, the aim of the blog post is only to demonstrate the feasibility of the analysis.
Text Tokenization with Oracle Text
The Tweet's FULL_TEXT column tokenization is done in the Oracle Database, you can see the full process described by the following video produced by the Oracle Analytics PM team.
If you prefer a short version of it, here it is: I basically created the following index
CREATE INDEX "FRANCESCO"."TWITTER_TWEET_IDX" ON "FRANCESCO"."TWEET_DATA_SQLDEV" ("FULL_TEXT") INDEXTYPE IS "CTXSYS"."CONTEXT";The INDEXTYPE IS "CTXSYS"."CONTEXT" creates an index using Oracle Text. A more accurate description of the procedure can be found in OracleBase's post.
Once the index is created, we can see some new tables appearing with the name DR$INDEX_NAME$LETTER with
$DR$being a fixed prefixINDEX_NAMEthe name of the indexLETTERa single letter betweenI,K,N,U,Rwhich meaning can be found in this Document
For the purpose of our analysis, we'll focus on the DR$TWITTER_TWEET_IDX$I table which contains the tokens of our FULL_TEXT column.
But the token by itself is not very useful, we need to match the token with the Tweet's ID to be able to provide meaningful analysis. Again, this is covered nicely by another video created by the Oracle Analytics PM team.
In order to associate the Token with the original Tweet we can use again the power of Oracle Text and the Index created above with the following query
SELECT
full_text,
score(1) AS text_score,
token_text,
a.id
FROM
tweet_data_sqldev a,
(
SELECT DISTINCT
token_text
FROM
dr$twitter_tweet_idx$i
)
WHERE
contains(a.FULL_TEXT, '/' || token_text, 1) > 0Again for more info about Oracle Text's CONTAINS function please refer to the relevant documentation.
I physicalized the output of the above query in a table ( TWEET_TOKENS), which contains the TOKEN_TEXT together with the Tweet's ID so we can now join this table with the original one containing the list of Tweets in Oracle Analytics Cloud.
Note: One of the next versions of Oracle Analytics Cloud will provide the Tokenization as step of a DataFlow within the Database Analytics options! You'll be able to tokenize your strings without leaving OAC.
Analysis of the Data in Oracle Analytics Cloud
If you're a frequent blog reader, this is probably the easiest part. I just had to:
- Create a connection to my Autonomous DataWarehouse by using the wallet file.
- Create the two datasources: one for
TWEET_DATA_SQLDEVand another forTWEET_TOKENS - Create a project and include both Datasources
Once in the project, the first visualization is about the most "liked" tweet... no surprise is when I become Oracle Ace Director, back in 2019, during KScope Keynote!
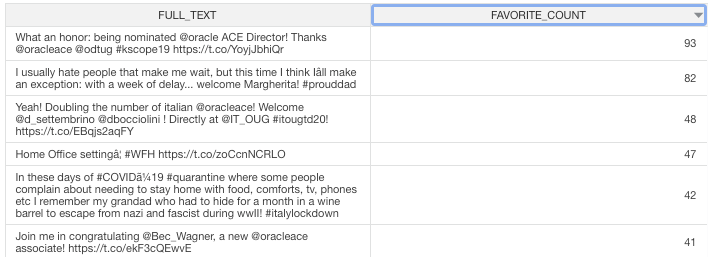
This first visualization is ok, but not really using any of the Oracle Text capabilities exposed in the Tokens... so my next analysis was...
Which words do I use more often when tweeting?
Easy... with the two datasources created above!

How does it change when I reply to people?
Well, you can see that words about OUG sessions and Oracle are still there, but there is the emerging topic of Food!

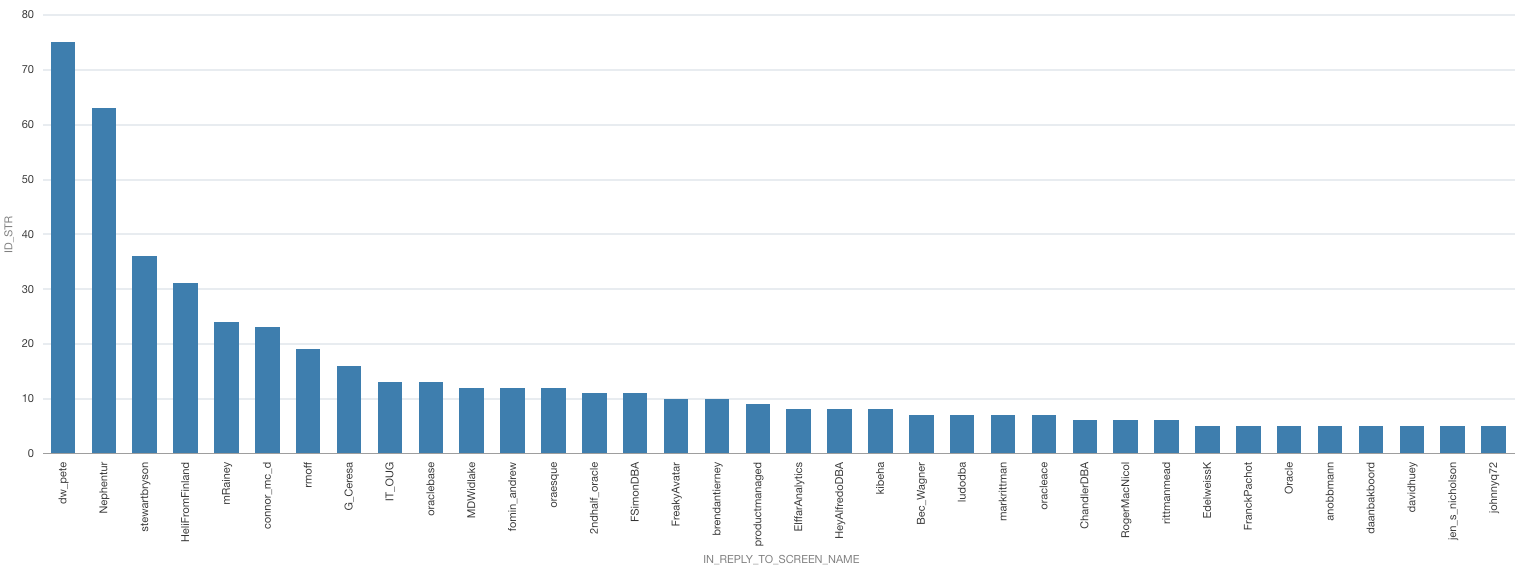
Who do I interact most with?
I plotted the # of Replies to specific Users…
No wonder (at least to me) that I get the most interactions with people that tag me with Italian food abominations…
And... how do I reply to them?
Again, very easy with Oracle Analytics Cloud Trellis Options.
You can spot that Food is the major discussion topic with HeliFromFinland and dw_pete, while my chats with @connor_mc_d and @stewartbryson are covering more topics
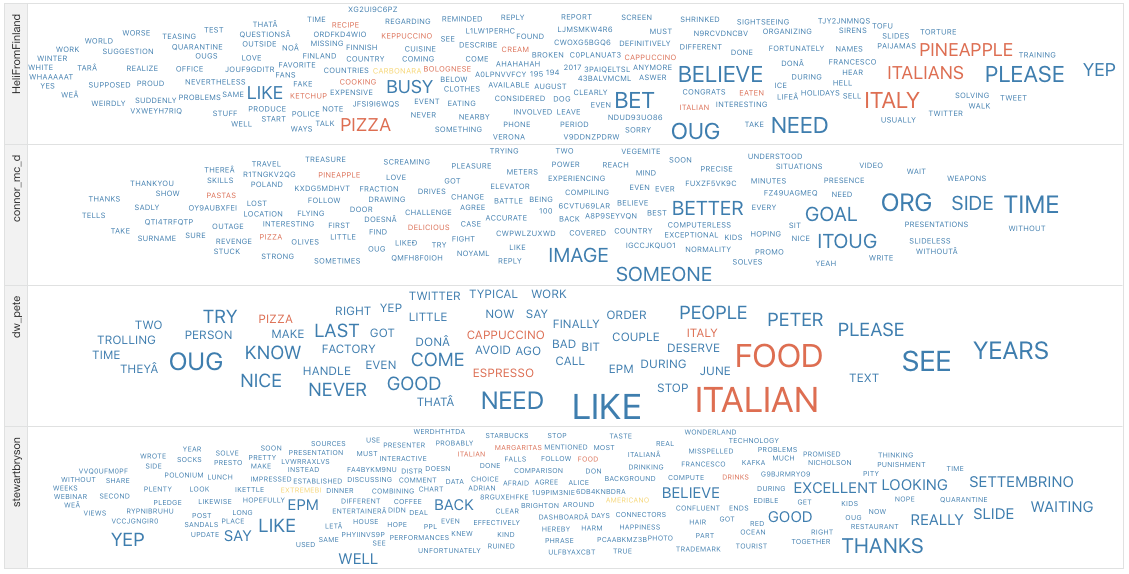
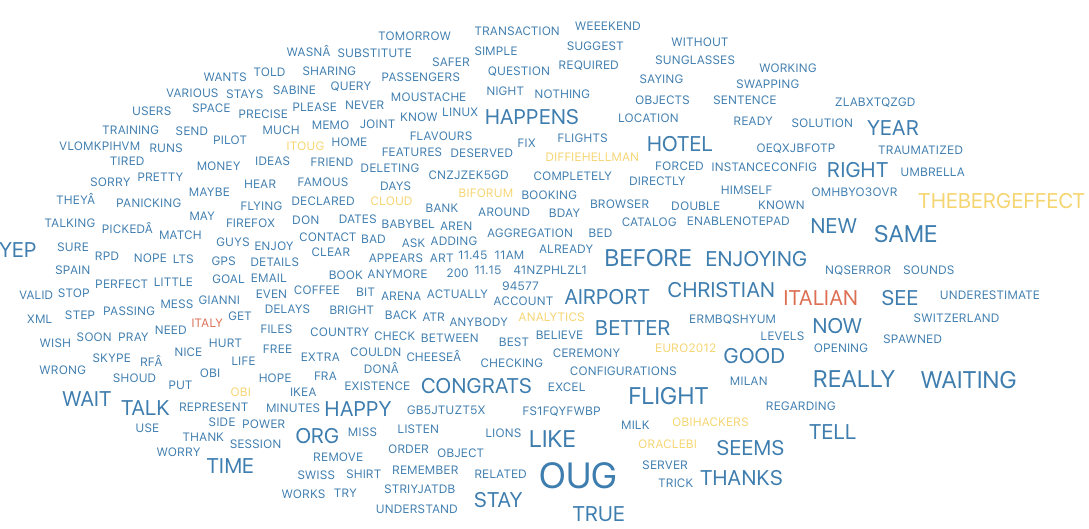
What about Nephentur?
One Last mention to my interactions with Nephentur: It’s clear his love for OUGs, Airports, Flights, Hotels… all driven by #TheBergEffect
Hope you liked the story, just an example of what you can do with a dataset you own and tools available in the Oracle Cloud!