How to Sense-Check Your Data Science Findings
Introduction
One of the most common pitfalls in data science is investing too much time investigating a dead-end. It happens to the best of us; you're convinced that you've found something amazing and profound that will revolutionise the client's business intelligence...And then, in an awkward presentation to a senior stakeholder, somebody points out that your figures are impossible and somewhere along the way you've accidentally taken a sum instead of an average. Here are a few tricks you can and should use to make this kind of embarrassment less likely.
Visualise Early and Often
The sooner you plot your data, the quicker you will notice anomalies. Plot as many variables as you have time for, just to familiarise yourself with the data and check that nothing is seriously wrong. Some useful questions to ask yourself are:
• Is anything about these data literally impossible? E.g., is there an 'age' column where someone is over 200 years old?
• Are there any outliers? Sometimes data that has not been adequately quality-checked will have outliers due to things like decimal-point errors.
• Are there duplicates? Sometimes this is to be expected, but you should keep it in mind in case you end up double-counting duplicate entries.
If It's Interesting, It's Suspicious
I once worked on a project that found that social deprivation scores negatively correlated with mental health outcomes, i.e., more deprived groups had better mental health scores. This was exactly the kind of surprising result that would have made for a great story, with the unfortunate caveat that it wasn't at all true.
It turned out that I had mis-coded a variable; all my zeroes were ones, and all my ones were zeroes. Fortunately I spotted this before the time came to present my findings, but this story illustrates an important lesson:
Findings that are interesting and findings that are erroneous share a common property: both are surprising.
Talk to Subject-Matter Experts
'Ah, this is impossible- this number can never go above ten' is one of the most heart-breaking sentences I've ever heard in my career.
It's often the case that someone more familiar with the data will be able to spot an error that an analyst recently brought onto a project will miss. It is essential to consult subject-matter experts often to get their eyes on your findings.
Check for Missing Data
There is a legendary story in data collection about Survivorship Bias. In WWII, a group called the Statistical Research Group was looking to minimise bombers lost to enemy gunfire. A statistician name Abraham Wald made the shrewd observation that reinforcements should be added to the sections of planes that returned from missions without bullet holes in them, rather than- as intuition might suggestion- the parts riddled with bullets. This was because those planes were the ones that returned safely, and so the parts that were hit were not essential to keeping the pilot alive.
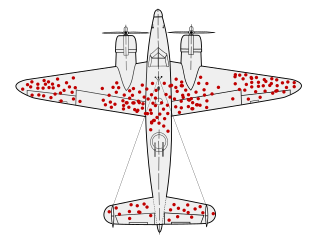
Missing data can poison a project's findings. There are a lot of reasons data could be missing, some more pernicious than others. If data is missing not-at-random (MNAR) it may obscure a systematic issue with data collection. It's very important to keep this in mind with something like survey data, where you should expect people who abandon the survey to be qualitatively different to people who complete it.
Understand Where the Data Came From and Why
Did you assemble this dataset yourself? If so, how recently did you assemble it, and do you still remember all of the filters and transformations you applied to get it in its current form? If someone else assembled it, did they document what steps they took and are they still around to ask? Sometimes a dataset will be constructed with a certain use case in mind different from your use case, and without knowing the logic that went into making it you run the risk of building atop a foundation of errors.
Beware the Perils of Time Travel
This one isn't a risk for all kinds of data, but it's a big risk for data with a date component- especially time series data. In brief, there is a phenomenon called Data Leakage wherein a model will be built such that it unintentionally cheats by using future data to predict the past. This trick only works when looking retrospectively because in the real world, we cannot see the future. Data leakage is a big enough topic to deserve its own article, but just be aware that you should look it up before building any machine learning models.
Conclusion
It is impossible to come up with a fully-general guard against basic errors, and kidding yourself into thinking you have one will only leave you more vulnerable to them. Even if you do everything right, some things are going to slip you by. I encourage you to think of any additions you might have to this list.