Oracle Generative AI Services


Overview
The Oracle Generative AI Services is a new fully managed service where you can use and customise pre-trained large language models (LLMs) for text generation. It is now available on Oracle Cloud Infrastructure (OCI) in the US Midwest (Chicago) Region.
The current facets of the service include:
The Playground - A console interface from which you can play with the pre-trained, or your own custom models. The interface is like many other AI service providers with a prompt entry box, “Generate” button, and response section.
You can edit a range of model parameters and test the models with a variety of prompts. You can then create generated Java or Python code that you can extract and integrate into other applications.
Dedicated AI clusters - Compute resources that can be used to create and host your own fine-tuned custom models.
Custom models - The pre-trained models that have been fine-tuned by you on a dedicated AI cluster. Fine-tuning involves customising pre-trained models to perform specific tasks or behaviours.
Endpoints - Endpoints are created on a dedicated AI cluster and used to access a custom model you have created. The custom model will then be listed from within the playground, or you can use a custom model in an application via the created endpoint.
Pre-trained Models
There are several pre-trained LLMs that you can use from within the playground or fine-tune for your needs. These models fall into several categories:
Text Generation - This is used to generate new text, or extract information from your text. Example use cases include: Drafting documents, emails, chatbot responses to questions, information retrieval from supplied text, and rewriting text in a different style.
Text Summarisation - This can be used to summarise text, includes changing the format, length or tone of the text.
Text Embedding - This can be used to convert text into a numeric form. The text can be of varying lengths, for example sentences or paragraphs. You can then use these embeddings to find similarities in the texts which is useful for semantic searches, or classifying similar text.
Playground
To use the Generative AI Services from the console go to Analytics and AI → Generative AI (Under AI Services).
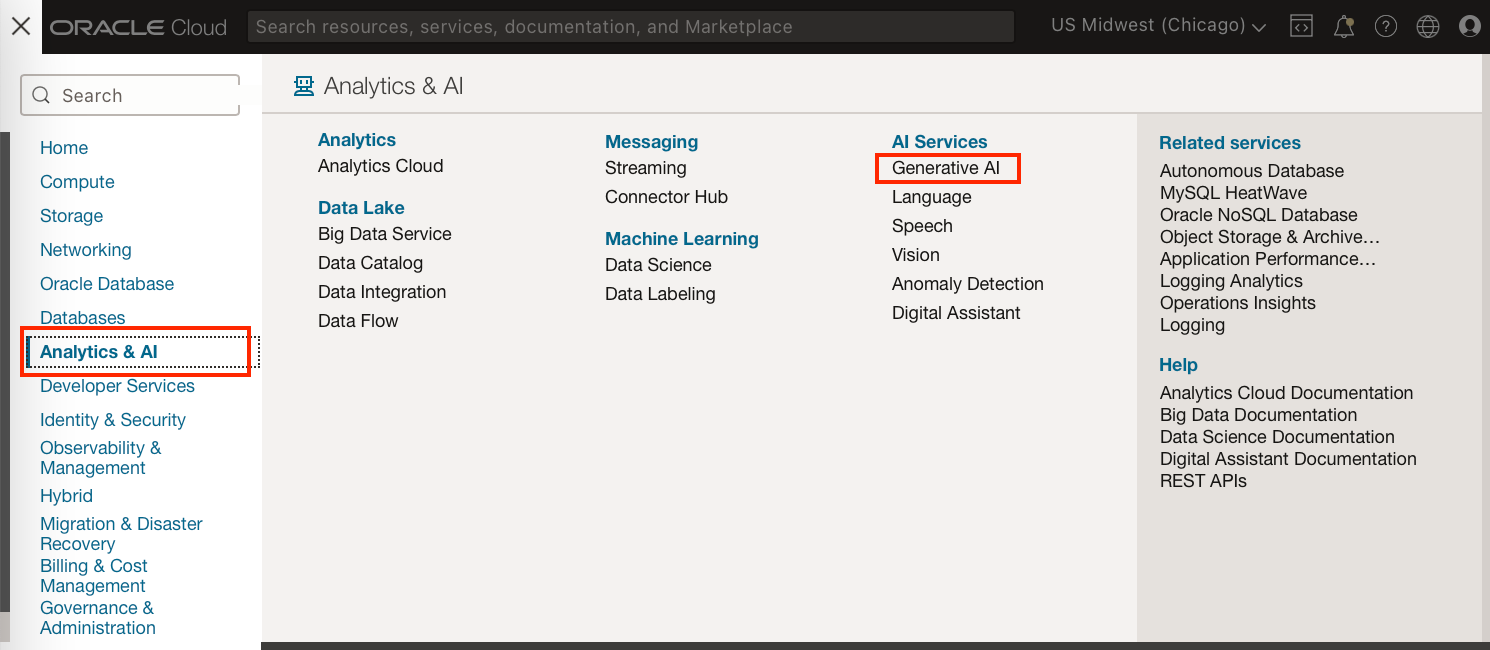
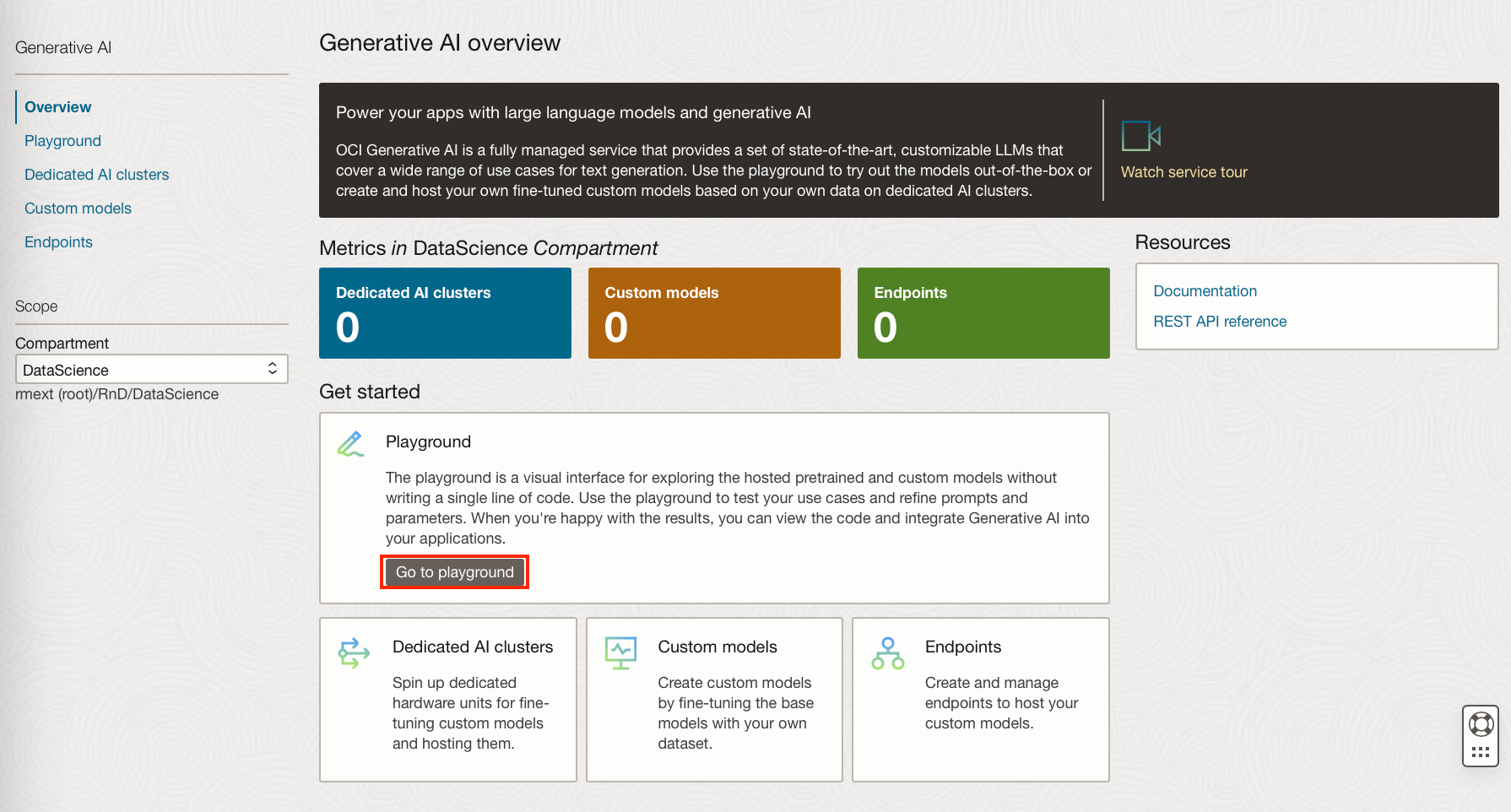
The playground can be found on the Overview page, or on the tab panel on the left.
Within the playground, you can select the model and type of model you wish to use from the dropdown. Obviously, this will depend on your use case.
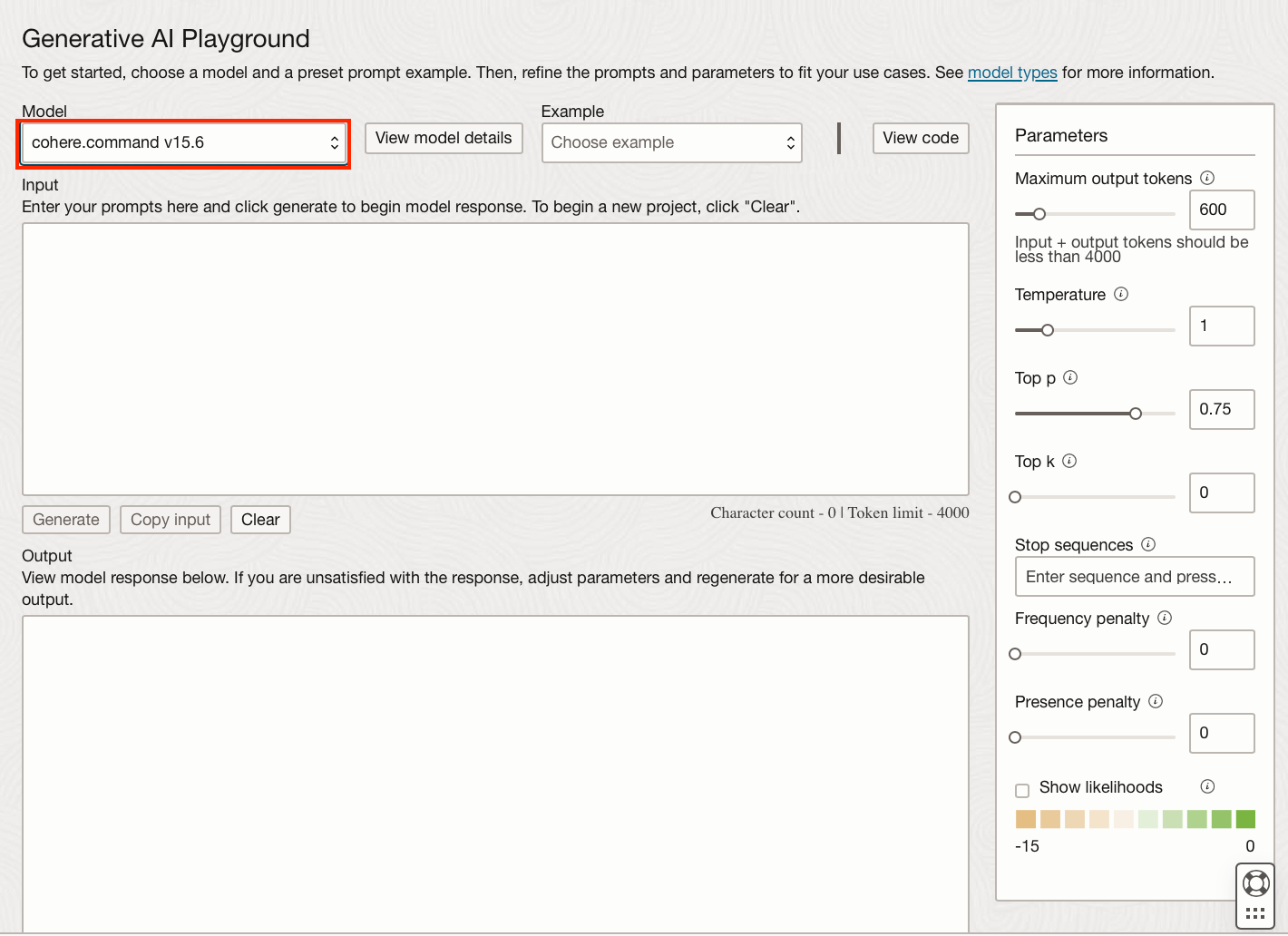
Currently, there are several models of each type available. The majority of these models are developed and trained by Oracle's partner Cohere.

Once you have selected a model you can then supply the model with prompts.
It is important to remember these models are trained on curated datasets, they will not know current events past their training dates and they will not know about your business processes or data. They can however be invaluable assets in drafting emails, rewording text, expanding bullet points to paragraphs, and even writing SQL statements with enough supplied information.
While using the playground you can vary different model parameters (dependent on the type of model chosen), and then click “Generate” again to change the output. If you wish to keep the context of prior prompts but add additional information or ask additional questions then type the next prompt in a new line after the output.
Pre-trained model parameters
Text Generation
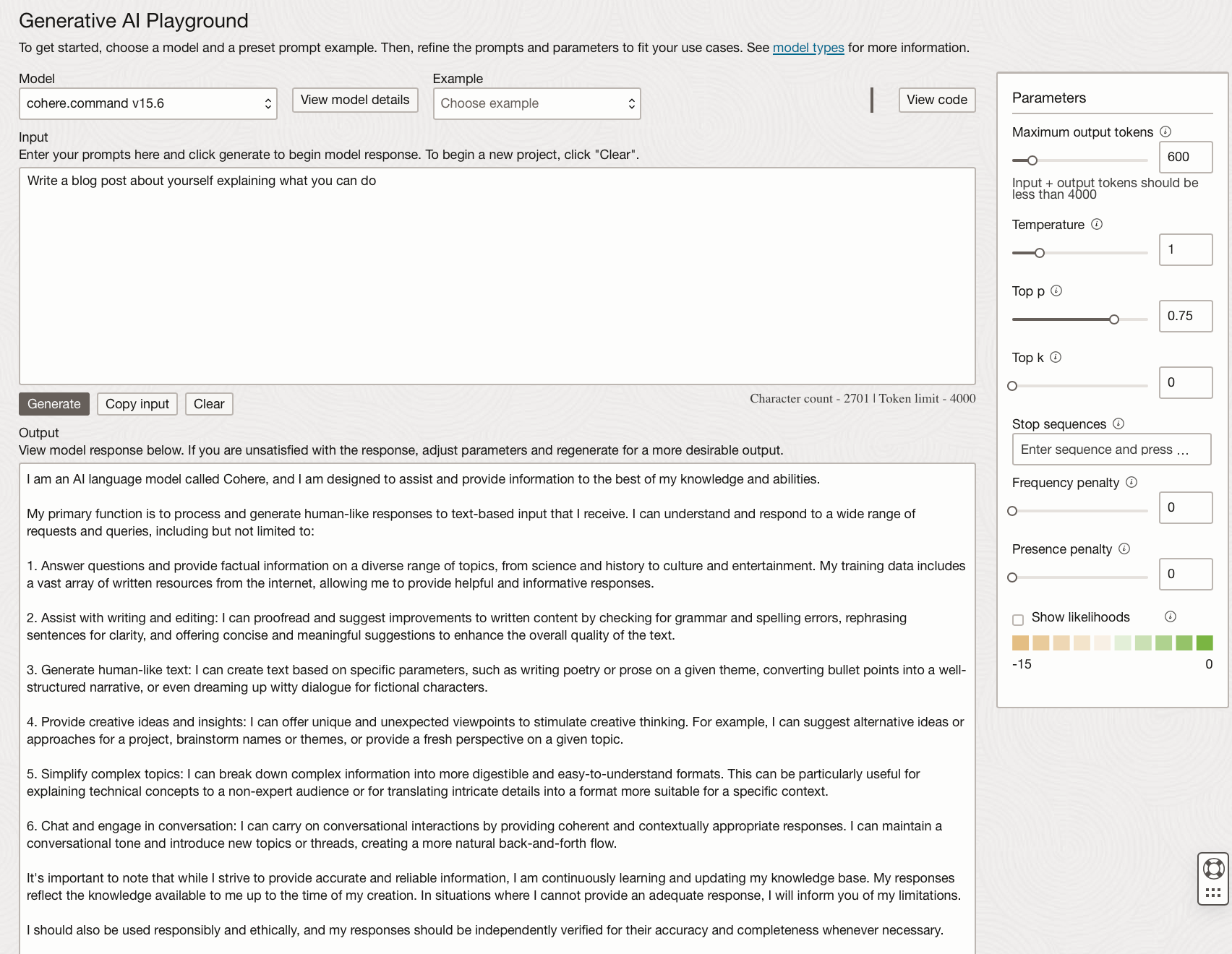
While using the text generation models you can vary:
Maximum output tokens - This is essentially the length of the response, one word is around 1-3 tokens.
Temperature - This determines how random or creative the response can be. If you want the same output for a prompt every time this should be set to 0.
Top p - This can be used to ensure that only the most likely tokens are considered for each step. p is the minimum percentage to consider for the next token, i.e. the default of 0.75 will exclude the least likely 25 percent for the next token.
Top k - This is another way to limit the tokens that can be chosen at each step, this limits the next chosen token to the top k most likely. A higher k has more tokens to choose from and will generate more random outputs. Setting to 0, which is the default, does not use this method.
Stop Sequences - A case-sensitive set of characters that stops the output. This could be a word, phrase, single character or new line.
Frequency Penalty - Assigns a penalty to repeated tokens depending on how many times it has already appeared in the prompt or output. Higher values will reduce repeated tokens and outputs will be more random.
Presence Penalty - Assigns a penalty to each token when it appears in the output to encourage outputs with tokens that have not been used. Higher values will reduce repeated tokens and outputs will be more random.
Show likelihoods - Turning this on will assign numbers to the generated tokens between -15 and 0. Larger numbers are more likely to follow the previous token, the generated text will be colour-coded, and you can hover over the generated words to see their likelihood.
Text Summarisation
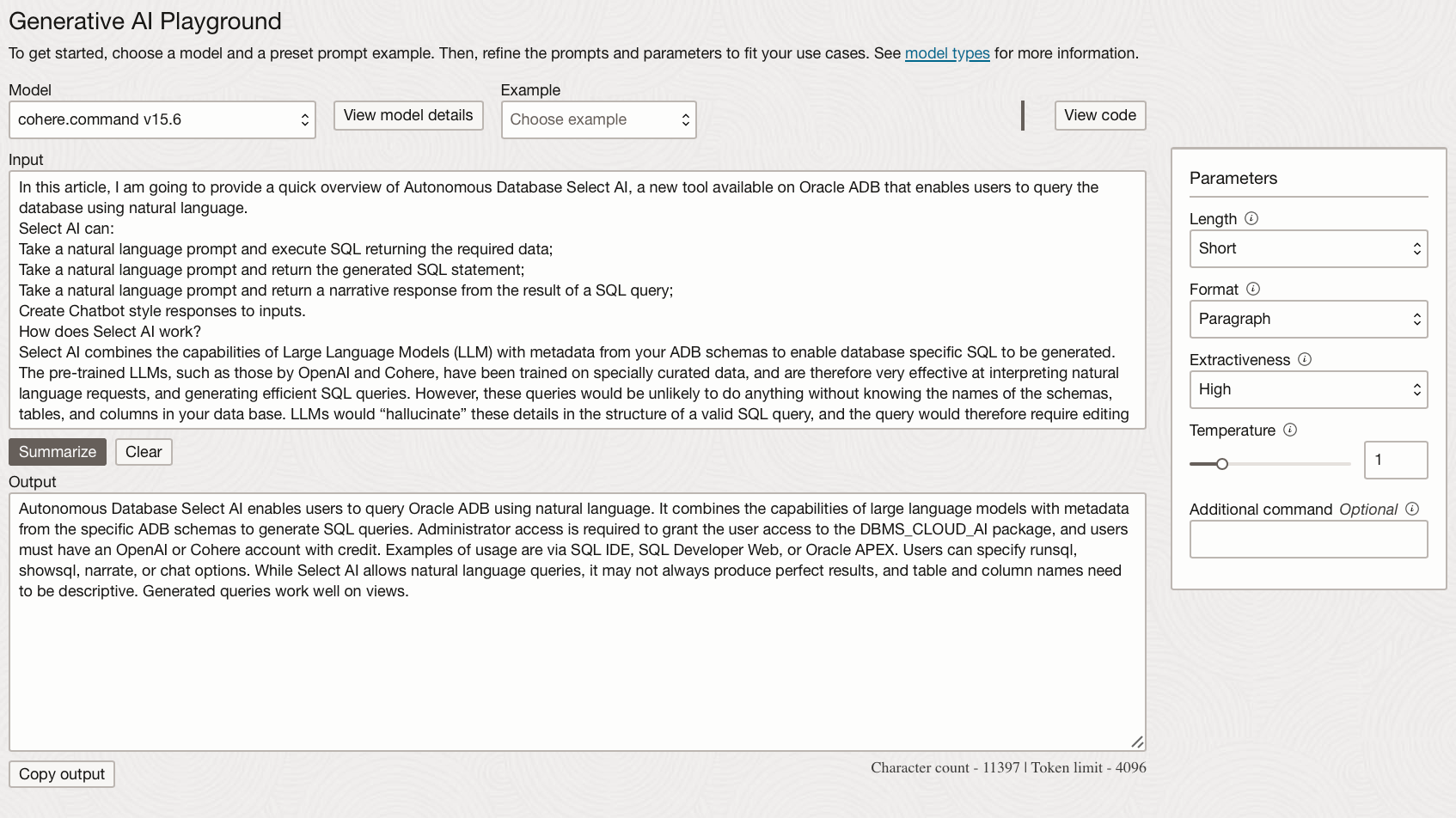
Length - Choose between short, medium and long
Format - Specify if you want the summary response in a paragraph or in bullet points.
Extractiveness - How much to reuse the input in the generated summary, high extractiveness may pull out entire sentences, while low values will paraphrase.
Temperature - This determines how random or creative the response can be. For summaries and questions, this should be lower since there are “correct” answers.
Additional command - Can be added to write the summary in a particular style or focus on specific aspects of the text to summarise.
Text Embedding
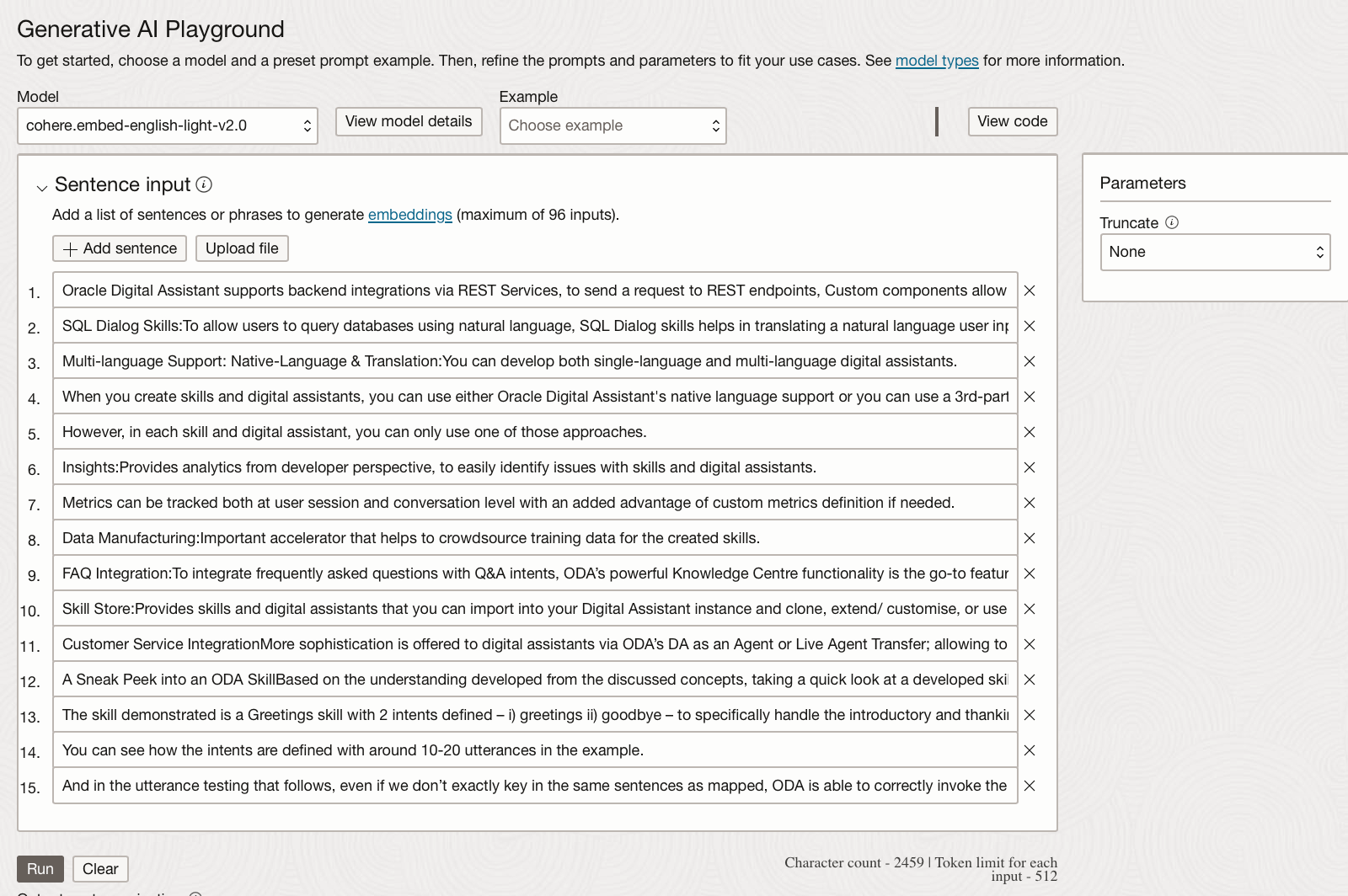
The text embedding models will let you decide whether to truncate the input, currently, you can add 96 sentences or a 96 line file.
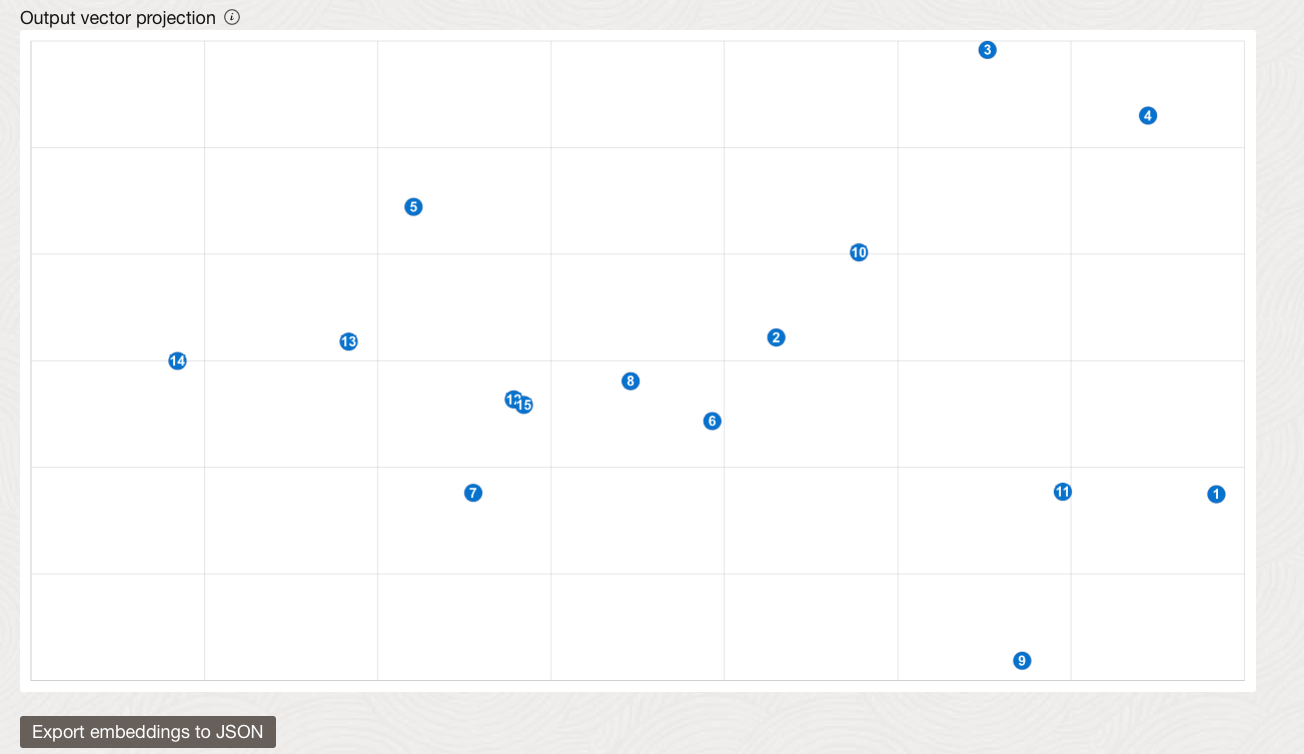
It will then show you a graphical representation of your vector embedding where closer points represent sentences with more similarities. You can then export the vectors to a JSON file by clicking on the button under the graph.
Using the model outside of the playground
Whichever type of model you are using in the playground, if you are happy with the responses produced with the set parameters you have set, you can extract the code to be used in an application.
Click “View code” and select either Java or Python as a language and then “Copy code”. This code can then be pasted into a file or application to enable similar responses to given prompts.
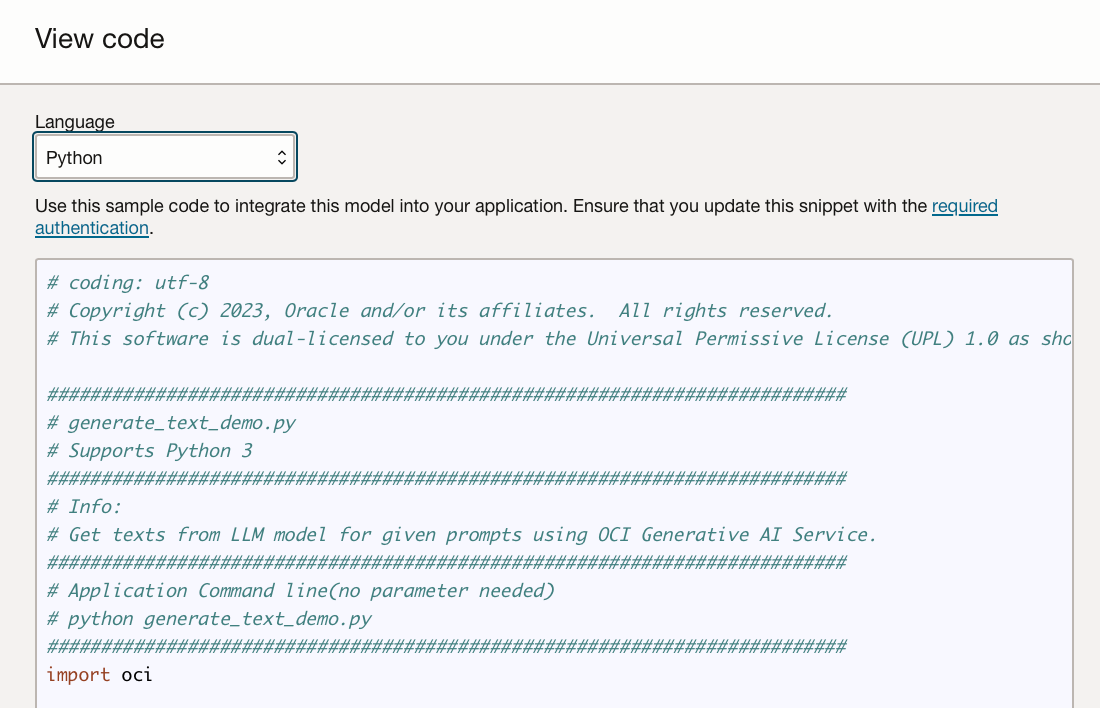
Customising models
If the LLMs are not producing the desired responses, even when varying the model parameters, then you might want to consider fine-tuning a model.
Fine-tuning can be used to customise a pre-trained model to perform specific tasks, adapting it to a narrower subject, or to answer queries in a certain way.
This is done by adjusting the original model by varying internal weights to bias it towards newly supplied data, helping the tuned model to gain new specialised skills while ensuring the model retains its general skills. The new data is typically in the form of an example prompt & expected LLM response in a JSONL file. Each example is one line in the JSONL file, normally you will need around 100-500 samples to fine tune a model. This training data will need to be representative of the end task or skill you want your custom model to be competent in.
It should be noted that the model will only know specific aspects or information about you business if you supply it examples in the training data.
It would be very cumbersome to fine-tune a LLM on a large quantity of your business documentation, for example to enable business and domain specific question-answering capabilities. If you are looking for a model with this kind of functionality that includes information retrieval as well as generative capabilities, then you will be interested in RAG models. These kinds of models combine a search/ retrieval mechanism, which fetches information relevant to a supplied prompt, and uses this information to generate a human like or summary response. This makes RAG models ideal for answering business specific questions, summarising internal documents, and other tasks where accessing your business specific local data is crucial.
We have a blog post coming out about RAG models very soon.
I hope this introductory blog post to Oracle Generative AI Services has piqued your interest and you are excited to give some of these models a go.