Real-time BI: EDW with a Real-time Component
I apologize for the long delay in getting this last portion of the Real-time discussion in place. Since I wrote the first two installments, we've had the BI Forum (US and UK versions), plus a flurry of activity around Rittman Mead in the US, followed up by KScope11. But a promise is a promise, and here goes with the conclusion.
I laid out the general vocabulary and considerations for Real-time BI in my first post in this series, and then followed up with how to implement Real-time BI using a federated approach that relies on the metadata capabilities OBIEE to blend two different environments into one. Now I'd like to discuss how we might implement a Real-time solution by relying on ETL instead of BI Tool metadata. I call this EDW with a Real-Time Component.
Whereas the Federated OLTP/EDW Reporting option provides us an option to layer real-time data into an otherwise classic batch-loaded EDW, delivering the EDW with a Real-Time Component requires designing an EDW from the ground up that supports real-time reporting. Specifically, we have to design our fact tables to support what Ralph Kimball calls the “real-time partition” in his book The Kimball Group Reader: “To achieve real-time reporting, we build a special partition that is physically and administratively separated from the conventional static data warehouse tables. Actually, the name partition is a little misleading. The real-time partition may be a separate table, subject to special rules for update and query.” We construct a separate section for each of our fact tables to facilitate the following 4 requirements, as defined by Kimball:
- Contain all activity since the last time the load was run
- Link seamlessly to the grain of the static data warehouse tables
- Be indexed so lightly that incoming data can “dribble in”
- Support highly responsive queries
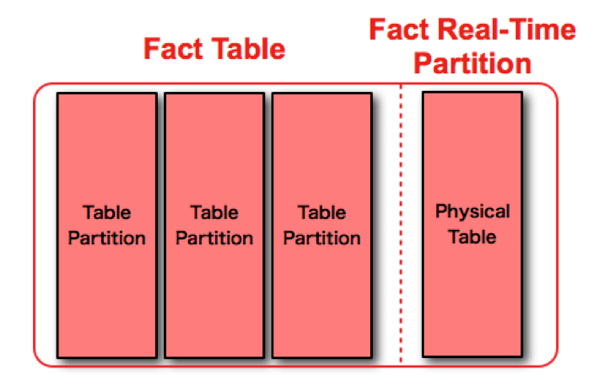
So we modify our model to support the interaction of real-time and static data, but we also modify our ETL to support this. In fact, to construct an EDW with a Real-Time Component, we have to build some very intricate interaction between the database, the data model and ETL processes. The static fact table is partitioned on a date data-type using standard Oracle partitioning strategies. The real-time partition is structured in such a way as to be loadable throughout the day. In other words, there are no indexes or constraints enabled on the table. ETL against the real-time partition uses a process comparable to traditional load scenarios, but using micro-batch instead, running as often as 100 times a day or more. Alternative methods include transactional style, record-by-record loading, possible using web services or message-based system such as JMS queues.
We effectively want to build a single logical fact table out of the combination of the static EDW fact table and the real-time fact partition. There are several ways to do this. We could use OBIEE fragmentation for this, as we saw in the last post. This would work, but it's not what I recommend. The reason we used fragmentation in the last post is because we were joining two completely different data sets across conformed dimensions into a unified model. However, with the real-time partition, we have two tables that have exactly the same structure—both using the same surrogate keys to the same dimension tables—just separated across different segments for performance reasons. In this case, I choose to UNION the two datasets with either a database view, or an opaque view in OBIEE.
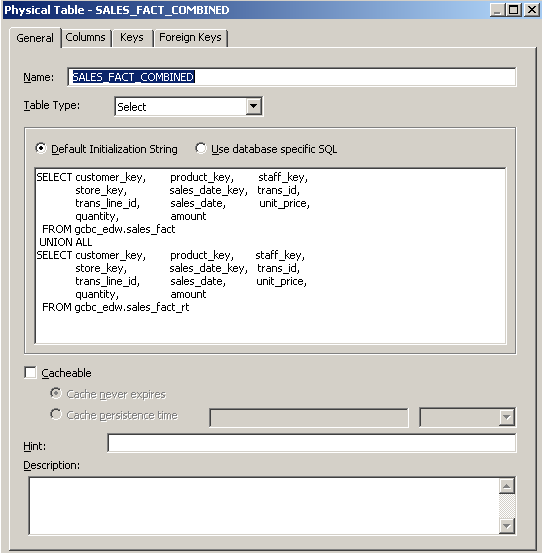
This works because we no longer have to control which source the rows will come from in particular situations: we simply pull all the rows, and use standard WHERE filters to limit the rows where applicable, and like the pruning the BI Server did for us in the last post, the Oracle Database will do for us in this case. We can, however, still present the static fact tables in situations that merit it: I'm thinking of financial reports here. Accountants don't usually like their reports giving different results every time they run them.
We have one issue with the load of the real-time partition: we are assuming that we receive all of our dimension data right along with our fact data in clean CDC subscription groups. That would likely be the case if we were pulling all the data for our data warehouse from a single source-system, but with enterprise data warehouses, that is rarely the case. Receiving dimension data early causes no problems with our load scenario; it doesn’t matter if we do the surrogate key lookup for the fact table load hours or days later than the dimensions. Receiving the fact table data early does present us with ETL logic issues: the correct dimension record may or may not be there when it’s time to load the facts.
There is a simple strategy to handle early-arriving facts. In our ETL, we implement a process to insure that our facts are at least reportable intra-day:
- If a dimension record exists for the current business or natural key we are interested in, then grab the latest record. This is the best we can do at this point, and will usually be the correct value.
- If no dimension record exists yet for the current natural key, then use a default record type equating to “Not Known Yet.” Though it’s not sexy for intra-day reporting, it at least makes the data available across the dimensions we do know about.
- As we approach the end of the day and prepare to “close the books” for the current day, we should have run all dimension loads—even late arriving dimensions—so that our dimension tables are all up to date. At this point we run a corrective mapping to update all the fact records in the real-time partition with the right surrogate keys. This would likely be a MERGE statement, or a TRUNCATE/INSERT style mapping. From a performance perspective, my bet is on the latter.

The above mapping loads the real-time partition in a micro-batch style doing an outer join to the CUSTOMER_DIM table and writing the "Not Known Yet" row in case a customer is not found. Also, I am employing a Splitter Operator in OWB, but I tricked it out to force it to load all rows to BOTH tables: SALES_FACT_RT and SALES_STG_RT. The reason for this is that we don't write dimension natural keys into our fact tables, though I've seen that technique employed in some real-time implementations. So when it's time to run our corrective mapping to correct our fact table data, we just join the SALES_STG_RT table to the now-correct dimension tables and produce the right surrogate keys for each fact record, and load the results into SALES_FACT_RT.
When “closing the books” on the day, we build indexes and constraints on the real-time partition that match those on the partitioned fact table. Once this step is complete, we can then use a partition-exchange operation to combine the real-time partition as part of the static fact table. In Oracle, this is a fast, dictionary update, and occurs almost instantaneously.
Obviously, our partitioning choice for the fact table will determine exactly how this partition-exchange will occur. If we’ll agree to partition the fact table by DAY, then we can use Oracle Interval partitioning, available in Oracle 11gR1 and beyond. We have to make this concession because Interval partitioning tables cannot have partitions in the same table that contain different range-based boundaries. For instance, we can’t have some MONTH-based partitions, while also having some DAY-based partitions, as we can with regular range-based partitioning. Using Interval partitioning is the easiest method, however, because it requires the least amount of partition maintenance as part of the load. For instance, consider the SALES_FACT table listed below, using Interval partitioning on the SALES_DATE_KEY, which we partition on at the DAY grain:
CREATE TABLE sales_fact
(
customer_key NUMBER NOT NULL,
product_key NUMBER NOT NULL,
staff_key NUMBER NOT NULL,
store_key NUMBER NOT NULL,
sales_date_key DATE NOT NULL,
trans_id NUMBER,
trans_line_id NUMBER,
sales_date DATE,
unit_price NUMBER,
quantity NUMBER,
amount NUMBER
)
partition BY range (sales_date_key)
interval (numtodsinterval(1,'DAY'))
(
partition sales_fact_2006 VALUES less than (to_date('2007-01-01','YYYY-MM-DD'))
)
COMPRESS
/
Each time we load a record into SALES_FACT for which no partition currently exists, Oracle will spawn one for the table. But based on our real-time requirements, we will use a partition-exchange operation every day to close the books on the current day processing, so each day, we will need to spawn a clean, new partition to facilitate that partition-exchange. All we need to do to make this happen is issue an insert statement with a DATE value for the partitioning key that equates to TRUNC(SYSDATE). For instance, the following statement would generate a new partition that we can use for the exchange:
SQL> INSERT INTO gcbc_edw.sales_fact 2 ( 3 customer_key, 4 product_key, 5 staff_key, 6 store_key, 7 sales_date_key, 8 trans_id, 9 trans_line_id, 10 sales_date, 11 unit_price, 12 quantity, 13 amount) 14 VALUES 15 ( 16 -1, 17 -1, 18 -1, 19 -1, 20 trunc(SYSDATE), 21 -1, 22 -1, 23 SYSDATE, 24 0, 25 0, 26 0 27 ) 28 / 1 row created. Elapsed: 00:00:00.01 SQL>
Once the insert has created our new SYSDATE-based partition, we can exchange the real-time partition in for this new partition. We can use the new PARTITION FOR clause — which allows us to reference partition names using partition key values — with a slight caveat. Though we can’t use SYSDATE explicitly in the DDL statement, we can reference it implicitly:
SQL> DECLARE
2 l_date DATE := SYSDATE;
3 l_sql LONG;
4 BEGIN
5 l_sql := q'|alter table gcbc_edw.sales_fact exchange partition|'
6 || chr(10)
7 || q'|for ('|'
8 || l_date
9 || q'|') with table gcbc_edw.sales_fact_rt|';
10
11 dbms_output.put_line( l_sql );
12 EXECUTE IMMEDIATE( l_sql );
13 END;
14 /
alter table gcbc_edw.sales_fact exchange partition
for ('03/01/2011 09:38:33 PM') with table gcbc_edw.sales_fact_rt
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.07
SQL>
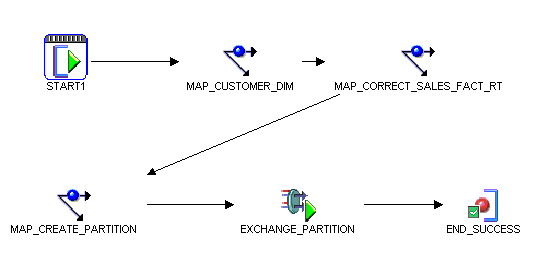
Using the preferred Interval partitioning option, the final “close the books” process flow is shown below. The first step that is taken is to run any late-arriving dimension mappings, in this example, the MAP_CUSTOMER_DIM mapping. Once all the dimensions are up-to-date, we can run the process that corrects all the dimension keys in the real-time partition. Remember, the real-time partition contains small data sets, so updating these records should not be resource intensive. In this scenario, the mapping MAP_CORRECT_SALES_FACT_RT issues an Oracle MERGE statement, but it is quite likely that a TRUNCATE/INSERT statement would work just as well. Once all the data in the real-time partition is correct and ready to go, we issue the MAP_CREATE_PARTITION mapping which uses an insert statement to spawn a new partition, and then the EXCHANGE_PARTITION PL/SQL procedure builds indexes and constraints, and completes the process by issuing the partition-exchange statement.