Oracle Data Integrator Designer for OWB Developers
Last time I described some of the aspects of ODI Topology. I only touched the surface of this subject and mainly kept to database sources; if you attend one of the Rittman Mead ODI bootcamps (we have public versions of the ODI course coming up in Australia, India, USA and the UK) you will learn a lot more about this topic over the four days of the course.
I surpose that the component of ODI that feels most like home to an OWB developer is the Designer Navigator. Functionally it is like an amalgam of the table editor, the mapping editor and the workflow editor with a load of other stuff thrown in. Again, just like the Topology Navigator, it is organised in accordion tabs. In this blog I am going to talk about just two of the accordions on the navigator: Models and Projects. These two are possibly all you need to design an ETL process; the model defines the structure of the data sources and targets (the tables in my example) and the project describes how the data is mapped from source model(s) to target model (usually in an interface) and how interfaces procedures and more are orchestrated in a PACKAGE (a package is similar to a process flow in OWB).
Models
In the same way that the Physical Architecture on the Topology Navigator contains data servers, the Designer Navigator's Models accordion hold Datastores. Datastores describe the structure of the data sources (think tables and files) and targets we place on to the interfaces. Right clicking in the models section gives us the option to create new folders, sub-folders, models and the data stores themselves. Folders and sub folders are optional components that help you organize your work. In the picture below we are naming the folder based on business purpose but another good approach is name the folder by technologies - for example an Oracle folder, a XML folder and so on.
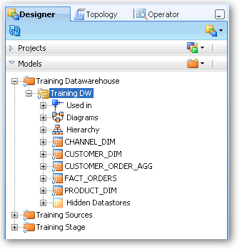
The model is the linkage to the Technology Navigator items. We name the model, specify the technology and give the logical architecture, the actual connection to the data server comes through the context. From the model we can right click to define the datastores themselves or optionally generate them by reverse engineering the connection. Generally, I prefer to reverse engineer as this process brings in the table, the columns and the constraints but it is equally feasible to create your own datastores in the navigator. Just as in OWB, reverse engineering a second time does not remove any alterations you made to the the data store design - you can get caught out if columns change name between imports.
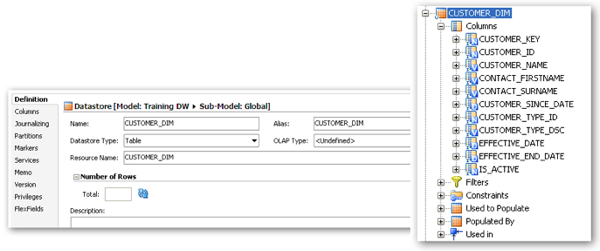
As you can see we can also define filters and constraints - filters are effectively a "where clause" that gets appended to the select query used for data sources; for example we may only want to load rows where STATUS = 'ACTIVE'. Constraints are where we define primary and alternate keys, unique constraints and so on. These constraints need not be physically implemented in the database but they are important to ODI. The primary or alternate keys are used in update operations to select the rows to update and unique constraints and not null constraints will be used if you elect to use the check modules as part of the interface implementation.
Projects
At last I get to the section where we actually implement the data flow from source to target. The first step on the projects accordion is to create a named project. This will generate sections for variables, sequences and knowledge modules (this may be somewhat different in the new 11.1.1.6 release as we can use versioned global Knowledge Modules). We can also create a folder to hold all of our interfaces, procedures and packages.
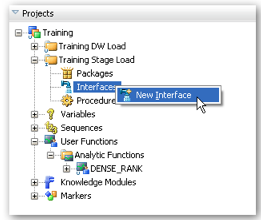
Interfaces are similar to OWB mappings in that they describe how data flows from table A, column B to table Z column X. Just as in OWB we can implement filters on the data sources, joiners between source tables (inner, left, right and full outer, and cartesian joins are supported) look-ups and set-based operators such UNION and MINUS. Where it differers is in that an ODI interface consists of a single target table and we do not have a palette of operators to place on the dataflow in the way in which we add expressions and constants to OWB mappings. Neither of these are a particular problem - constants and expressions can be typed directly in the mapping or quick edit tabs of the ODI interface editor (in fact ODI is more flexible as we can chose where to apply the expressions: on the source, the target or an intermediate stage table, this is a very useful feature) Not having multi-table inserts is again fairly simple to work around. Where the ODI interface is different from the OWB mapping is that we have a further two tabs of settings that we may need to complete - the flow tab is where we specify the knowledge modules our interface uses - there will always be one Integration Knowledge Module (IKM) which describes how data goes into the target datastore and depending on the technologies used in the interface possibly a Load Knowledge Module (LKM) this may not be the case if source and target datastores are on the same data server. The flow tab also has a selector to allow us to implement data validation on load through the use of a Check Knowledge Module (CKM).
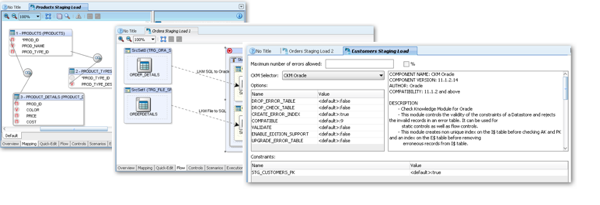
The Knowledge Modules I referred to above are, under the covers, ODI Procedures, that is a program of ODI actions to be executed in sequence. An ODI procedure consists of one or more steps (units of code) written in one of the supported scripting technologies (SQL, Jython, Groovy); within a procedure we can use multiple technologies, for example the first step may execute an OS command from Jython and a subsequent step perform some SQL action on a database table. In addition to the in-built functionality of Jython we can add our own functionality by importing java routines from .JAR files included in the ODI code path. Procedures, like interfaces can access ODI variables and metadata functions; both of these features allow us to develop very flexible processes.
The final part of the ODI project I will consider in this blog is the Package. Packages are similar in concept to the process flows in OWB, however unlike OWB they do not require the use of Oracle Workflow. Like the other accordions in the Designer Navigator right clicking in the package area gives us the option to create a new package. The package designer allows us to drop on to the screen the various interfaces and procedures we need to implement our package. In addition there is a rich palette of ODI actions that can also be added to perform tasks such as file unzipping, decryption and FTP transfers. We can also include ODI variables in the package and thus introduce conditional logic to the package. We specify the first step of the package by right-clickign on it and selecting "first step" then link it to the subsequent tasks by using the OK arrow tool (for success) or the KO arrow (for failure) in the case of the variable comparison operator OK is TRUE and KO is FALSE.
Of course, there is a lot more to ODI than I have covered in just three blog posts (there is more to OWB than this too!) but hopefully it has given a flavour of how ODI looks and perhaps the encouragement to try it out (or book an ODI course)