Introducing Oracle Enterprise Data Quality
Visually, BI dashboards and analyses can be impressive and appear to meet the user’s needs, but if the data displayed on the dashboards isn't reliable or correct then those same users can quickly lose faith in what they contain. Therefore, it’s important that assessing and managing data quality becomes an important part of any BI and data warehousing project.
Oracle recently introduced Oracle Enterprise Data Quality (EDQ) as their latest solution to the data quality “problem”, originally developed by Datanomic and known as “Dn: Director”. The acquisition of Datanomic is part of a renewed push by Oracle into data quality management. The acquisition follows on from previous efforts based around Oracle Data Integrator and, before that, Oracle Warehouse Builder.
Readers of this blog may well remember previous data quality initiatives based around ODI and OWB, with products like “Oracle Data Profiling and Quality” (OEM’d from Trillium) and “Data Quality Option for Oracle Database” based around Oracle Warehouse Builder. Mark posted a summary of the two tools a few years ago, but it’s probably true to say that neither gained much traction within the marketplace, hence the reboot of their strategy around Datanomic and what is now Oracle Enterprise Data Quality.
Of course “data quality” as a topic area has been around for a while and there have always been tools to address it, so why should we be interested in another Oracle initiative in this area? Enterprise Data Quality is a bit different to previous efforts Oracle have made in this area, principally in that it’s more of a complete solution, it’s been on the market (successfully) for a while in it’s Datanomic guise. It tries to extend the data quality management process through to business users, who of course in the end govern the data and have the power to improve its quality long-term.
As a product, EDQ has more to offer in terms of data quality than tools like ODI and OWB in that it’s a complete data quality management platform, rather than being just a plug-in to an ETL tool. Key features include:
- All data quality operations are bundled in one tool (profiling, auditing, cleansing, matching).
- EDQ is designed to be easy and intuitive to use, making it possible to involve business users in the data quality management process.
- Support for data governance best practices, and display of data quality KPIs through a dashboard.
- The ability to create and raise cases (like help-desk tickets) as data quality issues are identified, and then being assigned to developers or business users to resolve in a structured, tracked way
- A library of standardized data quality operations that can be applied and if needed, customized, the aim being to avoid “re-inventing the wheel” and instead leveraging standard techniques to identify and resolve common data quality issues.
- Although EDQ runs standalone, Oracle have however developed an ODI plug-in (via a tool that you add to packages and load plans) that call-out to EDQ functionality, in a similar way to the ODI tool that currently integrates with the Trillium-based Oracle Data Profiling and Quality. We’ll look at this tool and how EDQ works with ODI in a future post.
- Another feature of EDQ is the ability to build a package and then deploy and re-use it across the whole organization. Packages can also be developed for specific vertical markets and applications, such as fraud detection and risk and compliance application. Datanomic took their core data quality technologies and used them to create packaged DQ products such as their risk and compliance application, an approach that gained a fair bit of traction in areas such as financial services and banking. A good example of such a solution is Watchscreen.
Datanomic’s data quality software will become part of the Oracle Data Integration solution and will deliver a complete solution for data profiling, data quality and data integration. In addition, Datanomic offered a number of data quality-based applications, pre-packaged business-ready solutions.
DQ Main principles
Data quality can be thought of as having four main principles, with the EDQ platform providing solutions aligned with them:
- Understand the data Analyze the data, identify issues, gaps and errors.
- Improve the data Transforming and correcting the data to improve the data quality.
- Protect the data Having a continuous process by measuring and correcting the data by integrating it into the daily ETL load
- Govern the data Having a process for monitoring the data quality and showing the results on a dashboard. Have a process for tracking and resolving issues.

The main application of EDQ, called “Director”, is used for profiling, analyzing and cleaning your data. EDQ has capabilities for logging, detecting issues and assigning them to resources, as well as monitoring and matching data.
EDQ is similar to ETL tools that define sources and targets, and then use mappings to transfer the data. In EDQ mappings are called processes, which can be scheduled to run at a chosen time, and can be integrated with the load plans and packages used by Oracle Data Integrator, through the Open Tools SDK.
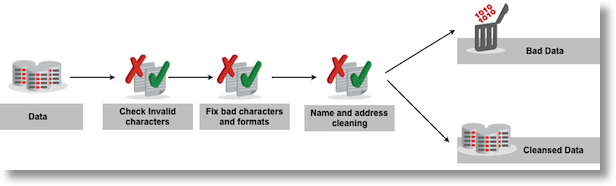
Example of a transformation
In the example below, data is loaded from a file or from a database table, following which the data is analyzed for invalid characters and cleaned. Finally the ‘bad’ data will be saved to a separate file or table and ‘good’ data will be written to a file/table.
Prebuilt processors
EDQ has prebuilt processors, which can be customised if required. A group of processors makes a process (similar to an ETL mapping). I will only highlight some of the available tool palettes.
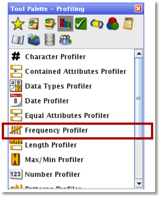
The frequency profiler is very interesting because it helps you to understand your data and helps you to spot the first data issues. When there is an abnormally high or low number of frequencies for a column then you may perhaps consider investigating these fields.
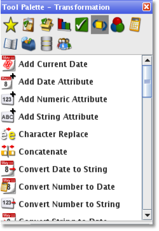
As you can see in the above screenshot, there are a lot of transformation processes that you can make use of, to for example convert a string to data, concatenate strings, replace characters within strings and so forth.
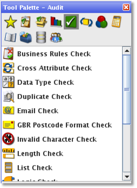
There are also many auditing options such as ones around email and business rules checking. Do not forget that these processors are all prebuilt, and as stated before you can define your own processes or customize existing ones.
EDQ Reporting and case management
Having the business involved is key in any data quality project; therefore the EDQ platform has an integrated tool for data quality issue management. Within EDQ there is another tool for the creation of reports and dashboards, which can help to improve communication with the business as they will be able to see any data quality issues in graph form.
Data Profiling
Data profiling is concerned with the first analysis of a data source in order to understand the data, and identify issues with its quality or content. In EDQ data profiling is automated, so that when creating a process a wizard will prompt the user to begin data profiling at the start of it. After adding data profiling to a project, you can the analyze the initial results within the result browser. To take an example, I have loaded a sample of a customer table and started profiling on the customer table, as shown in the screenshot below:
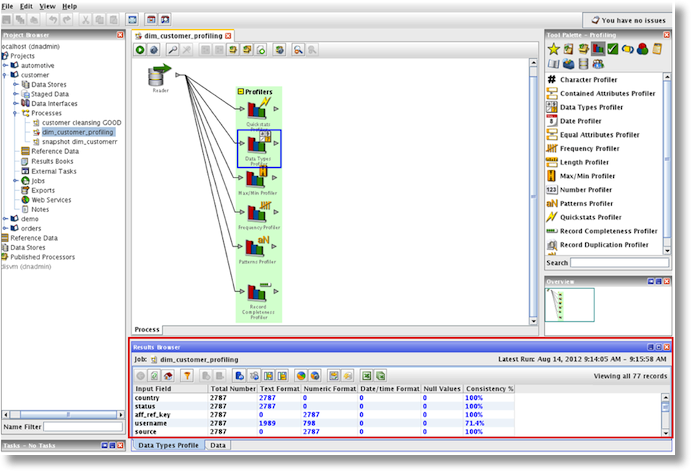
The data profiler checks the consistency for a column for the date format. In the above screenshot the column ‘username’ is 71.4% consistent, so a closer look is needed to validate its data content.
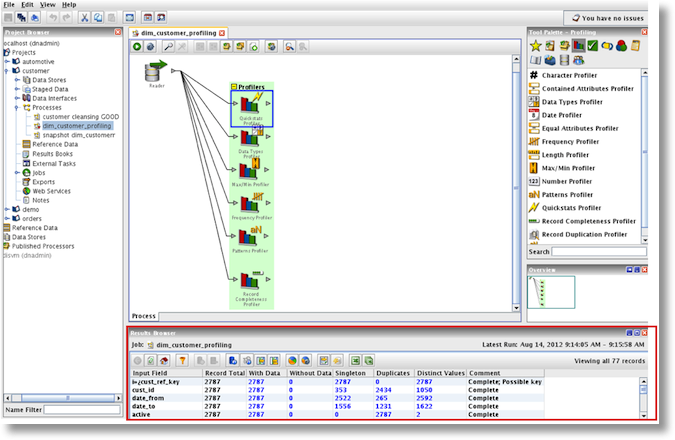 The results browser also indicates if a field has unique values or of there are duplicates or if it has null values.
When choosing a sample of the data set a trend for the complete dataset can be derived. It is depending of the data quality strategy which approach you want to take.
The results browser also indicates if a field has unique values or of there are duplicates or if it has null values.
When choosing a sample of the data set a trend for the complete dataset can be derived. It is depending of the data quality strategy which approach you want to take.
Data Cleansing
Data cleansing is the process of detecting and correcting corrupt or inaccurate records from a record set, table or database.
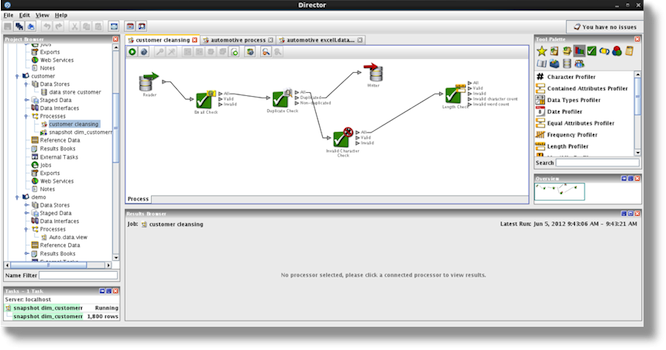
Implementing data cleansing is very straightforward, in that you create a process to which you then add or create the needed processors. In the following screenshot the email address of a column is being checked and it will be checked for duplicates. All validated records will go to the target file/table, and all bad records will be saved in a temporary file/table. Depending on the implemented data quality strategy, you can then either correct the invalid data, or save the data and keep it as a source for improvement of the data quality.
Processing / Scheduling
Once the processes have been made and tested they are placed into a job and are scheduled.
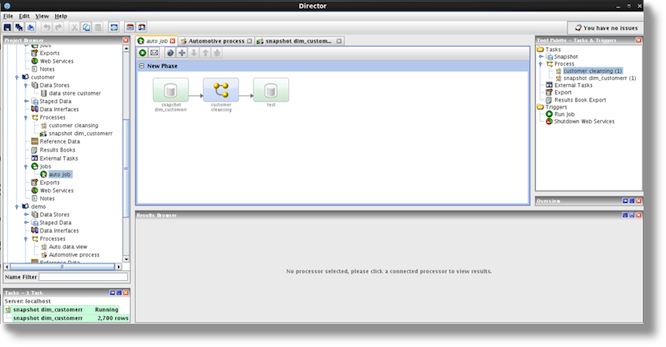
EDQ and ODI Integration
Typically EDQ will be used within an ODI data flow (during a data migration or when populating a data warehouse). Oracle Data Integrator 11.1.1.6.0 introduced a new Open Tool named “Enterprise Data quality” that allows ODI developers to invoke an Oracle Enterprise Data quality job, in the form of an Open Tool. This Oracle blog article explains how to integrate EDQ and ODI in this way.
Data Quality and Oracle Reference Architecture.
Oracle recommends checking data quality before any data gets loaded into the Enterprise Data Warehouse (EDW). Referring to the Oracle Reference Architecture the data should be cleansed before it enters the staging area and should be maintained in one single data source.
Hardware recommendations
For processing data volumes of up to 10 million source records, Oracle recommends a server with 4 cores, 16 GB RAM and a 250 GB hard disk for the EDQ repository.
EDQ architecture
EDQ has a web graphical user interface and several client applications.The server application is built around a Java servlet engine and has a SQL RDBMS system (the data repository), using a repository that contains two database schemas: the director schema and the results schema. The director schema stores configuration data for EDQ and the results schema stores snapshot, staged and results data. It is highly dynamic, with tables being created and dropped as required to store the data handled by processors running on the server. Temporary working tables are also created and dropped during process execution to store any working data that cannot be held in the available memory. When loading and processing data the memory of the server will be used and there will be a lot of I/O to the database.
Conclusion
As said in the beginning of this post, most BI projects suffer in some way from data quality issues, therefore a data quality strategy should really be put in place. The Datanomic acquisition by Oracle can help to deliver data quality solutions within BI projects, based on Datanomic's proven experience in this area. With regards to EDQ, it differentiates itself from other data quality tools because it’s offering a full data quality solution. Another strong point is that a lot of the processes are already prepackaged and ready to use. The tool is designed for having a close communication with the business users by having the case management tool and the reporting option. The tool is also very easy and intuitive to use, therefore a business user can be involved in the creation of data quality processes. We will keep you posted on further news regarding the EDQ solutions.