OBIEE BI Server Cache Management Strategies


The OBIEE BI Server cache can be one of the most effective ways of improving response times of OBIEE dashboards. By using data already in the cache it reduces load on the database, the network, and the BI Server.
Should you be using it? I always describe it as the “icing on the cake” – it’s not a fix for a badly-designed OBIEE system, but it does make a lot of sense to use once you’re happy that the foundations for the system are in place. If the foundations are not not in place? Then you’re just papering over the cracks and at some point it’s probably going to come back to bite you. As Mark Rittman put it nearly seven years ago, it’s “[…]usually the last desperate throw of the dice”. The phrase “technical debt”? Yeh, that. But, BI Server caching used after performance review and optimisation rather than instead of - then it’s a Good Thing.
So you’ve decided to use the BI Server cache, and merrily trotted over to Enterprise Manager to enable it, restarted the BI Server, and now your work is done, right? Not quite. Because the BI Server cache will start to store data from all the queries that you run, and use it to satisfy subsequent queries. Not only will it match on a direct hit for the same query, it will use a subset of an existing cache entry where appropriate, and can even aggregate up from what’s in the cache to satisfy a query at a higher level. Clever stuff. But, what happens when you load new data into your data warehouse? Well, the BI Server continues to serve requests out of the cache, because why shouldn’t it? And herein lies the problem with “just turn caching on”. You have to have a cache management strategy.
A cache management strategy sounds grand doesn’t it? But it boils down to two things:
- Accuracy – Flush any data from the cache that is now stale
- Speed – Prime the cache so that as many queries get a hit on it, first time
Maintaining an Accurate Cache
Every query that is run through the BI Server, whether from a Dashboard, Answers, or more funky routes such as custom ODBC clients or JDBC, will end up in cache. It’s possible to “seed” (“prime”/“warmup”) the cache explicitly, and this is discussed later. The only time you won’t see data in the cache is if (a) you have BI Server caching disabled, or (b) you’ve disabled the Cacheable option for a physical table that is involved in providing the data for the query being run.
You can see metadata for the current contents of the cache in the Administration Tool when connected online to the BI Server, through the Manage -> Cache menu option. This gives you lots of useful information (particularly when you come to optimising cache usage) including the size of each entry, when it was created, when it was last used, and so on.
Purging Options
So we’ve a spread of queries run that hit various dimension and fact tables and created lots of cache entries. Now we’ve loaded data into our underlying database, so we need to make sure that the next time a user runs an OBIEE query that uses the new data they can see it. Otherwise we commit the cardinal sin of any analytical system and show the user incorrect data which is a Bad Thing. It may be fast, but it’s WRONG….
We can purge the whole cache, but that’s a pretty brutal approach. The cache is persisted to disk and can hold lots of data stretching back months - to blitz all of that just because one table has some new data is overkill. A more targeted approach is to purge by physical database, physical table, or even logical query. When would you use these?
- Purge entire cache - the nuclear option, but also the simplest. If your data model is small and a large proportion of the underlying physical tables may have changed data, then go for this
- Purge by Physical Database - less brutal that clearing the whole cache, if you have various data sources that are loaded at different points in the batch schedule then targeting a particular physical database makes sense.
- Purge by Physical Table - if many tables within your database have remained unchanged, whilst a large proportion of particular tables have changed (or it’s a small table) then this is a sensible option to run for each affected table
- Purge by Query - If you add a few thousand rows to a billion row fact table, purging all references to that table from the cache would be a waste. Imagine you have a table with sales by day. You load new sales figures daily, so purging the cache by query for recent data is obviously necessary, but data from previous weeks and months may well remain untouched so it makes sense to leave queries against those in the cache. The specifics of this choice are down to you and your ETL process and business rules inherent in the data (maybe there shouldn’t be old data loaded, but what happens if there is? See above re. serving wrong data to users). This option is the most complex to maintain because you risk leaving behind in the cache data that may be stale but doesn’t match the precise set of queries that you purge against.
Which one is correct depends on
- your data load and how many tables you’ve changed
- your level of reliance on the cache (can you afford low cache hit ratio until it warms up again?)
- time to reseed new content
If you are heavily dependant on the cache and have large amounts of data in it, you are probably going to need to invest time in a precise and potentially complex cache purge strategy. Conversely if you use caching as the ‘icing on the cake’ and/or it’s quick to seed new content then the simplest option is to purge the entire cache. Simple is good; OBIEE has enough moving parts without adding to its complexity unnecessarily.
Note that OBIEE itself will perform cache purges in some situations including if a dynamic repository variable used by a Business Model (e.g. in a Logical Column) gets a new value through a scheduled initialisation block.
Performing the Purge
There are several ways in which we can purge the cache. First I’ll discuss the ones that I would not recommend except for manual testing:
- Administration Tool -> Manage -> Cache -> Purge. Doing this every time your ETL runs is not a sensible idea unless you enjoy watching paint dry (or need to manually purge it as part of a deployment of a new RPD etc).
- In the Physical table, setting Cache persistence time. Why not? Because this time period starts from when the data was loaded into the cache, not when the data was loaded into your database.
An easy mistake to make would be to think that with a daily ETL run, setting the Cache persistence time to 1 day might be a good idea. It’s not, because if your ETL runs at 06:00 and someone runs a report at 05:00, there is a going to be a stale cache entry present for another 23 hours. Even if you use cache seeding, you’re still relinquishing control of the data accuracy in your cache. What happens if the ETL batch overruns or underruns?
The only scenario in which I would use this option is if I was querying directly against a transactional system and wanted to minimise the number of hits OBIEE made against it - the trade-off being users would deliberately be seeing stale data (but sometimes this is an acceptable compromise, so long as it’s made clear in the presentation of the data).
So the two viable options for cache purging are:
BI Server Cache Purge Procedures
These are often called “ODBC” Procedures but technically ODBC is just one - of several - ways that the commands can be sent to the BI Server to invoke.
As well as supporting queries for data from clients (such as Presentation Services) sent as Logical SQL, the BI Server also has its own set of procedures. Many of these are internal and mostly undocumented (Christian Berg does a great job of explaining them here, and they do creep into the documentation here and here), but there are some cache management ones that are fully supported and documented. They are:
SAPurgeCacheByQuerySAPurgeCacheByTableSAPurgeCacheByDatabaseSAPurgeAllCacheSAPurgeCacheBySubjectArea(>= 11.1.1.9)SAPurgeCacheEntryByIDVector(>= 11.1.1.9)
The names of these match up to the purge processes that I describe above. The syntax is in the documentation, but what I am interested in here is how you can invoke them. They are my preferred method for managing the BI Server cache because they enable you to tightly couple your data load (ETL) to your cache purge. Setting the cache to purge based on a drop-dead timer (whether crontab, tivoli, Agent/iBot, whatever) gives you a huge margin of error if your ETL runtime does not remain consistent. Whether it organically increases in runtime as data volumes increase, or it fails and has to be fixed and restarted, ETL does not always finish bang-on when it is ‘supposed’ to.
You can call these procedures in the several ways, including:
- nqcmd - one of the most common ways, repeated on many a blog, but requires nqcmd/OBIEE to be installed on the machine running it. nqcmd is a command-line ODBC client for connecting to the BI Server
- ODBC - requires BI to be installed on the machine running it in order to make the OBIEE ODBC driver available
- JDBC - just requires the OBIEE JDBC driver, which is a single
.jarfile and thus portable - Web Service - the OBIEE BI Server Web Service can be used to invoke these procedures from any machine with no dependencies other than some WSM configuration on the OBIEE server side.
My preference is for JDBC or Web Service, because they can be called from anywhere. In larger organisations the team building the ETL may have very little to do with OBIEE, and so asking them to install OBIEE components on their server in order to trigger cache purging can be quite an ask. Using JDBC only a single .jar needs copying onto the server, and using the web service not even that:
curl --silent --header "Content-Type: text/xml;charset=UTF-8" --user weblogic:Admin123 --data @purge_cache_soap.xml http://192.168.56.102:7780/AdminService/AdminService [...] [59118] Operation SAPurgeAllCache succeeded! [...]
For details of configuring ODI to use the BI Server JDBC driver in order to tightly couple the cache management into an existing ODI load job, stay tuned for a future blog!
Event Polling Tables (EPT)
NB Not Event “Pooling” Tables as I’ve often seen this called
The second viable approach to automated cache purging is EPT, which is a decoupled approach to managing the cache purge, with two components:
- An application (your ETL) inserts a row into the table
S_NQ_EPT(which is created at installation time by the RCU in the BIPLATFORM schema) with the name of the physical table in which data has been changed - The BI Server polls (hence the name) the
S_NQ_EPTtable periodically, and if it finds entries in it, purges the cache of data that is from those tables.
So EPT is in a sense the equivalent of using SAPurgeCacheByTable, but in a manner that is not tightly coupled. It relies on configuring the BI Server for EPT, and there is no easy way to know from your ETL if the cache purge has actually happened. It also means that the cache remains stale potentially as long as the polling interval that you’ve configured. Depending on when you’re running your ETL and the usage patterns of your users this may not be an issue, but if you are running ETL whilst users are on the system (for example intra-day micro ETL batches) you could end up with users seeing stale data. Oracle themselves recommend not setting the polling interval any lower than 10 minutes.
EPT has the benefit of being very easy to implement on the ETL side, because it is simply a database table into which the ETL developers need to insert a row for each table that they update during the ETL.
Seeding the Cache
Bob runs an OBIEE dashboard, and the results are added to the cache so that when Bill runs the same dashboard Bill gets a great response rate because his dashboard runs straight from cache. Kinda sucks for Bob though, because his query ran slow as it wasn’t in the cache yet. What’d be nice would be that for the first user on a dashboard the results were already in cache. This is known as seeding the cache, or ‘priming’ it. Because the BI Server cache is not dumb and will hit the cache for queries that aren’t necessarily direct replicas of what previously ran working out the optimal way to seed the cache can take some trial and error careful research. The documentation does a good job of explaining what will and won’t qualify for a cache hit, and it’s worth reading this first.
There are several options for seeding the cache. These all assume you’ve figured out the queries that you want to run in order to load the results into cache.
- Run the analysis manually, which will return the analysis data to you and insert it into the BI Server Cache too.
- Create an Agent to run the analysis with destination set to Oracle BI Server Cache (For seeding cache), and then either:
- Schedule the analysis to run from an Agent on a schedule
- Trigger it from a Web Service in order to couple it to your ETL data load / cache purge batch steps.
- Use the BI Server Procedure SASeedQuery (which is what the Agent does in the background) to load the given query into cache without returning the data to the client. This is useful for doing over JDBC/ODBC/Web Service (as discussed for purging above). You could just run the Logical SQL itself, but you probably don’t want to pull the actual data back to the client, hence using the procedure call instead.
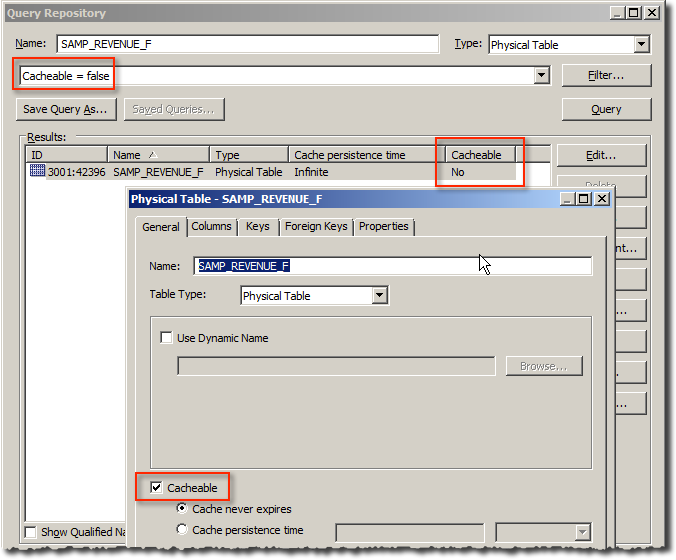
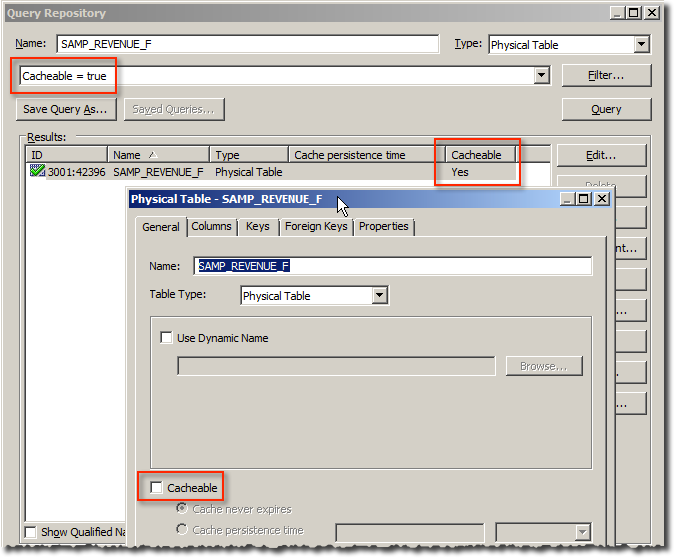
Sidenote - Checking the RPD for Cacheable Tables
The RPD Query Tool is great for finding objects matching certain criteria. However, it seems to invert results when looking for Cacheable Physical tables - if you add a filter of Cacheable = false you get physical tables where Cacheable is enabled! And the same in reverse (Cacheable = true -> shows Physical tables where Cacheable is disabled)
Day in the Life of an OBIEE Cache Entry (Who Said BI Was Boring?)
In this example here I’m running a very simple report from SampleApp v406:
The Logical SQL for this is:
SELECT 0 s_0, "A - Sample Sales"."Time"."T02 Per Name Month" s_1, "A - Sample Sales"."Base Facts"."1- Revenue" s_2 FROM "A - Sample Sales" ORDER BY 1, 2 ASC NULLS LAST FETCH FIRST 5000001 ROWS ONLY
Why’s that useful to know? Because when working with the cache resubmitting queries is needed frequently and doing so directly from an interface like nqcmd is much faster (for me) than a web GUI. Horses for courses…
So I’ve run the query and now we have a cache entry for it. How do we know? Because we see it in the nqquery.log (and if you don’t have it enabled, go and enable it now):
[2015-09-23T15:58:18.000+01:00] [OracleBIServerComponent] [TRACE:3] [USER-42] [] [ecid: 00586hFR07mFw000jzwkno0005Qx00007U,0] [tid: 84a35700] [requestid: a9730015] [sessionid: a9730000] [username: weblogic] -------------------- Query Result Cache: [59124] The query for user 'weblogic' was inserted into the query result cache. The filename is '/app/oracle/biee/instances/instance1/bifoundation/OracleBIServerComponent/coreapplication_obis1/cache/NQS__735866_57498_0.TBL'.
We see it in Usage Tracking (again, if you don’t have this enabled, go and enable it now):
SELECT TO_CHAR(L.START_TS, 'YYYY-MM-DD HH24:Mi:SS') LOGICAL_START_TS, SAW_SRC_PATH, NUM_CACHE_INSERTED, NUM_CACHE_HITS, NUM_DB_QUERY FROM BIEE_BIPLATFORM.S_NQ_ACCT L ORDER BY START_TS DESC;

We can also see it in the Administration Tool (when connected online to the BI Server):

We can even see it and touch it (figuratively) on disk:

So we have the data in the cache. The same query run again will now use the cache entry, as seen in nqquery.log:
[2015-09-23T16:09:24.000+01:00] [OracleBIServerComponent] [TRACE:3] [USER-21] [] [ecid: 11d1def534ea1be0:6066a19d:14f636f1dea:-8000-000000000000b948,0:1:1:5] [tid: 87455700] [requestid: a9730017] [sessionid: a9730000] [username: weblogic] -------------------- Cache Hit on query: [[ Matching Query: SET VARIABLE QUERY_SRC_CD='Report',SAW_SRC_PATH='/users/weblogic/Cache Test 01',PREFERRED_CURRENCY='USD';SELECT 0 s_0, "A - Sample Sales"."Time"."T02 Per Name Month" s_1, "A - Sample Sales"."Base Facts"."1- Revenue" s_2 FROM "A - Sample Sales" ORDER BY 1, 2 ASC NULLS LAST FETCH FIRST 5000001 ROWS ONLY Created by: weblogic
and in Usage Tracking:

“Interestingly” Usage Tracking shows a count of 1 for number of DB queries run, which we would not expect for a cache hit. The nqquery.log shows the same, but no query logged as being sent to the database, so I’m minded to dismiss this as an instrumentation bug.
Now what about if we want to run a query but not use the BI Server Cache? This is an easy one, plenty blogged about it elsewhere - use the Request Variable DISABLE_CACHE_HIT=1. This overrides the built in system session variable of the same name. Here I’m running it directly against the BI Server, prefixed onto my Logical SQL - if you want to run it from within OBIEE you need the Advanced tab in the Answers editor.
SET VARIABLE SAW_SRC_PATH='/users/weblogic/Cache Test 01', DISABLE_CACHE_HIT=1:SELECT 0 s_0, "A - Sample Sales"."Time"."T02 Per Name Month" s_1, "A - Sample Sales"."Base Facts"."1- Revenue" s_2 FROM "A - Sample Sales" ORDER BY 1, 2 ASC NULLS LAST FETCH FIRST 5000001 ROWS ONLY
Now we get a cache ‘miss’, because we’ve specifically told the BI Server to not use the cache. As you’d expect, Usage Tracking shows no cache hit, but it does show a cache insert - because why shouldn’t it?

If you want to run a query without seeding the cache either, you can use DISABLE_CACHE_SEED=1:
SET VARIABLE SAW_SRC_PATH='/users/weblogic/Cache Test 01', DISABLE_CACHE_HIT=1,DISABLE_CACHE_SEED=1:SELECT 0 s_0, "A - Sample Sales"."Time"."T02 Per Name Month" s_1, "A - Sample Sales"."Base Facts"."1- Revenue" s_2 FROM "A - Sample Sales" ORDER BY 1, 2 ASC NULLS LAST FETCH FIRST 5000001 ROWS ONLY

These request variables can be set per analysis, or per user by creating a session initialisation block to assign the required values to the respective variables.
Cache Location
The BI Server cache is held on disk, so it goes without saying that storing it on fast (eg SSD) disk is a Good Idea. There's no harm in giving it its own filesystem on *nix to isolate it from other work (in terms of filesystems filling up) and to make monitoring it super easy.
Use the DATA_STORAGE_PATHS configuration element in NQSConfig.ini to change the location of the BI Server cache.
Summary
- Use BI Server Caching as the ‘icing on the cake’ for performance in your OBIEE system. Make sure you have your house in order first - don’t use it to try to get around bad design.
- Use the SAPurgeCache procedures to directly invoke a purge, or the Event Polling Tables for a more loosely-coupled approach. Decide carefully which purge approach is best for your particular caching strategy.
- If using the SAPurgeCache procedures, use JDBC or Web Services to call them so that there is minimal/no installation required to call them from your ETL server.
- Invest time in working out an optimal cache seeding strategy, making use of Usage Tracking to track cache hit ratios.
- Integrate both purge and seeding into your ETL. Don’t use a schedule-based approach because it will come back to haunt you with its inflexibility and scope for error.