Using Apache Drill with OBIEE 12c

Apache Drill enables querying with SQL against a multitude of datasources including things like JSON files, Parquet and Avro, Hive tables, RDBMS and more. MapR have released an ODBC driver for it, and I thought it'd be neat to get it to work with OBIEE. It evidently does work for OBIEE running on Windows, but I wanted to be able to use it on my standard environment, Linux.
For more information on Apache Drill, see my previous post, Introduction to Apache Drill.
OBIEE 12c (and 11g and 10g before it) supports three primary ways of connecting to data sources:
- Native Gateway, such as OCI for Oracle. This is always the preferred option as it gives the greatest support and performance.
- Data Direct ODBC Drivers, a set of which are bundled with OBIEE for enabling connectivity to sources such as SQL Server, MySQL, Hive, and Impala. The configuration of these is documented in the OBIEE manuals, and is generally a supported configuration.
- Native ODBC Drivers.
To get OBIEE to work with Apache Drill we'll use the third option - native ODBC drivers. I'm doing this on SampleApp v511. For a geek-out on details of the process I went through and diagnostics used to get this to work, see here.
Update: Fiston has written up an excellent blog post showing how JDBC can be used to connect OBIEE 12c to Apache Drill - very cool!
First Things First - Setting up Apache Drill
Drill can be deployed in distributed configuration (with all the parallel processing goodness which that brings), but also run as a single instance locally. For the sake of simplicity that's what I'm going to do here. It's rather easy to do:
# Download Apache Drill
wget http://www.apache.org/dyn/closer.cgi/drill/drill-1.7.0/apache-drill-1.7.0.tar.gz
# Unpack
tar -xvf apache-drill-1.7.0.tar.gz
# Run
cd /opt/apache-drill-1.7.0/ && bin/sqlline -u jdbc:drill:zk=local
You need to make sure you've got a recent JDK available, and if you're running it on BigDataLite VM watch out for this odd problem that I had which was related to classpaths and maniested itself with the error java.lang.NoSuchMethodError: com.fasterxml.jackson.databind.JavaType.isReferenceType()Z.
All being well, you'll now have a Drill prompt:
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=512M; support was removed in 8.0
Aug 09, 2016 5:51:43 AM org.glassfish.jersey.server.ApplicationHandler initialize
INFO: Initiating Jersey application, version Jersey: 2.8 2014-04-29 01:25:26...
apache drill 1.7.0
"say hello to my little drill"
0: jdbc:drill:zk=local>
From here you can run a simple query to check the version:
0: jdbc:drill:zk=local> SELECT version FROM sys.version;
+----------+
| version |
+----------+
| 1.7.0 |
+----------+
1 row selected (0.392 seconds)
or query one of the built-in sample data sets:
0: jdbc:drill:zk=local> select count(*) from cp.`employee.json`;
+---------+
| EXPR$0 |
+---------+
| 1155 |
+---------+
1 row selected (0.977 seconds)
For more examples of Drill, see the tutorials.
Setting up Drill ODBC on Linux with OBIEE
With Drill setup and running locally, let's now install the ODBC driver. This is all on SampleApp v511 / Oracle Linux 6.7.
sudo rpm -i http://package.mapr.com/tools/MapR-ODBC/MapR_Drill/MapRDrill_odbc_v1.2.1.1000/MapRDrillODBC-1.2.1.x86_64.rpm
Next, create the MapR Drill ODBC driver configuration file. A sample one is provided, which you can copy from the default installation path of /opt/mapr/drillodbc/Setup/mapr.drillodbc.ini, or create new. I put it in the default path (~/.mapr.drillodbc.ini).
[Driver]
DisableAsync=0
DriverManagerEncoding=UTF-16
ErrorMessagesPath=/opt/mapr/drillodbc/ErrorMessages
LogLevel=2
LogPath=/tmp/odbc.mapr
SwapFilePath=/tmp
ODBCInstLib=libodbcinst.so
In the above I've changed a few things:
- The most important is
DriverManagerEncoding. If you leave this as the default ofUTF-32OBIEE will crash (SIGSEGV) when you try to query the data in Apache Drill. You can read all about my trials and tribulations trying to figure this out in a separate blog post coming soon. - I've set
LogLevelto 2 andLogPathto a valid path, so that there's some log files to check if things go wrong - Set the
ODBCInstLibtolibodbcinst.sowhich matches the built in DataDirect ODBC Driver Manager library file.
Following the documentation, Configuring Database Connections Using Native ODBC Drivers:
-
Add the necessary environment variables to BI Server. This is done per-component in a
.propertiesfile, which for the BI Server (OBIS / nqsserver) isBI_DOMAIN/config/fmwconfig/bienv/obis/obis.properties, so on SampleApp/app/oracle/biee/user_projects/domains/bi/config/fmwconfig/bienv/OBIS/obis.properties. To this file (which in 12.2.1 is empty by default) we add:MAPRDRILLINI=/home/oracle/.mapr.drillodbc.ini LD_LIBRARY_PATH=/opt/mapr/drillodbc/lib/64 -
Add the Drill DSN to
odbc.iniwhich for OBIEE already exists and is populated with other ODBC configurations. You'll find the file inBI_DOMAIN/config/fmwconfig/bienv/core, which on SampleApp is/app/oracle/biee/user_projects/domains/bi/config/fmwconfig/bienv/core/odbc.ini.-
Add to the
[ODBC Data Sources]sectionDrillDSN=MapR Drill ODBC Driver 64-bit -
Add a section to the bottom of the file:
[DrillDSN] Driver=/opt/mapr/drillodbc/lib/64/libmaprdrillodbc64.so AuthenticationType=No Authentication Description=Drill ODBC Driver ConnectionType=Direct HOST=localhost PORT=31010
-
Now restart the BI Server:
/app/oracle/biee/user_projects/domains/bi/bitools/bin/stop.sh -i obis1 && /app/oracle/biee/user_projects/domains/bi/bitools/bin/start.sh -i obis1
On a Windows machine I installed the MapR Drill ODBC driver too and created a DSN of the same name as in my odbc.ini file above. In the Administration Tool I set up a new Database (type: ODBC Basic) and associated connection pool (ODBC 2.0) pointing to DrillDSN.
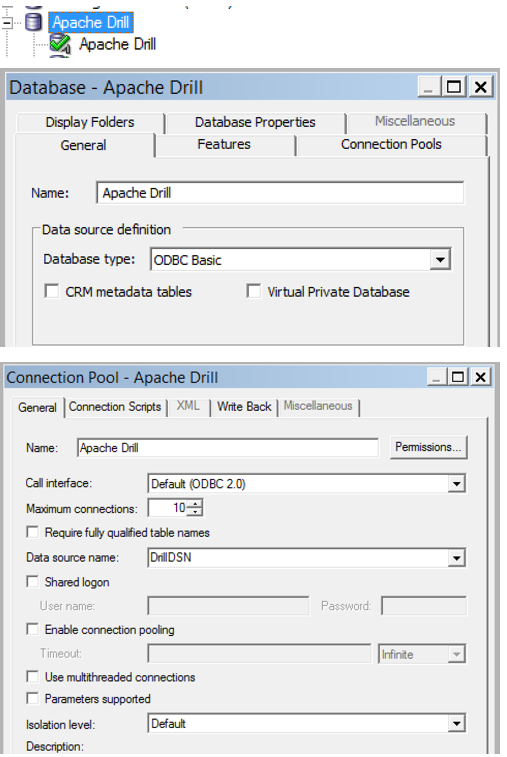
Now to try it out! In Answers I build a Direct Database Request:
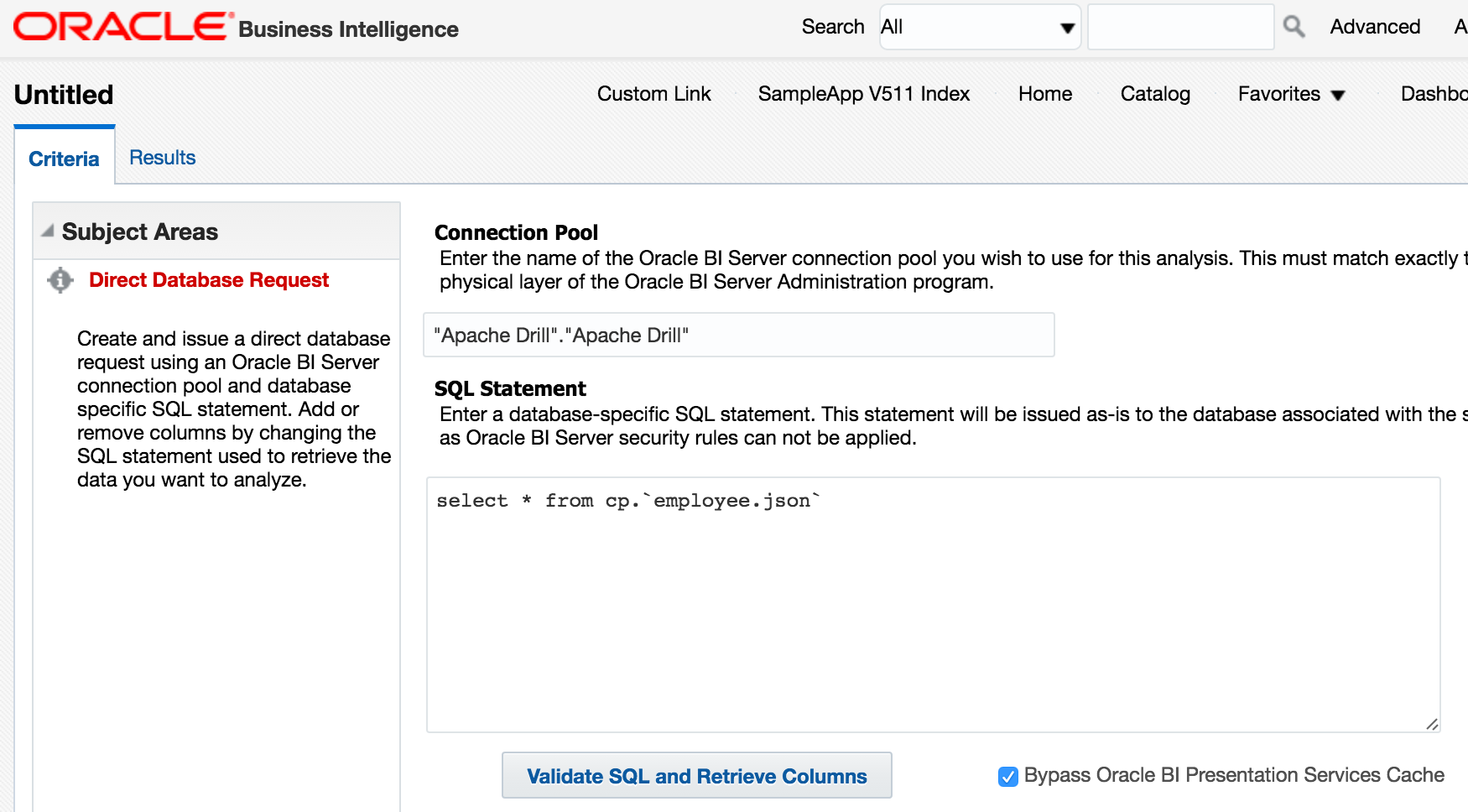
and run it
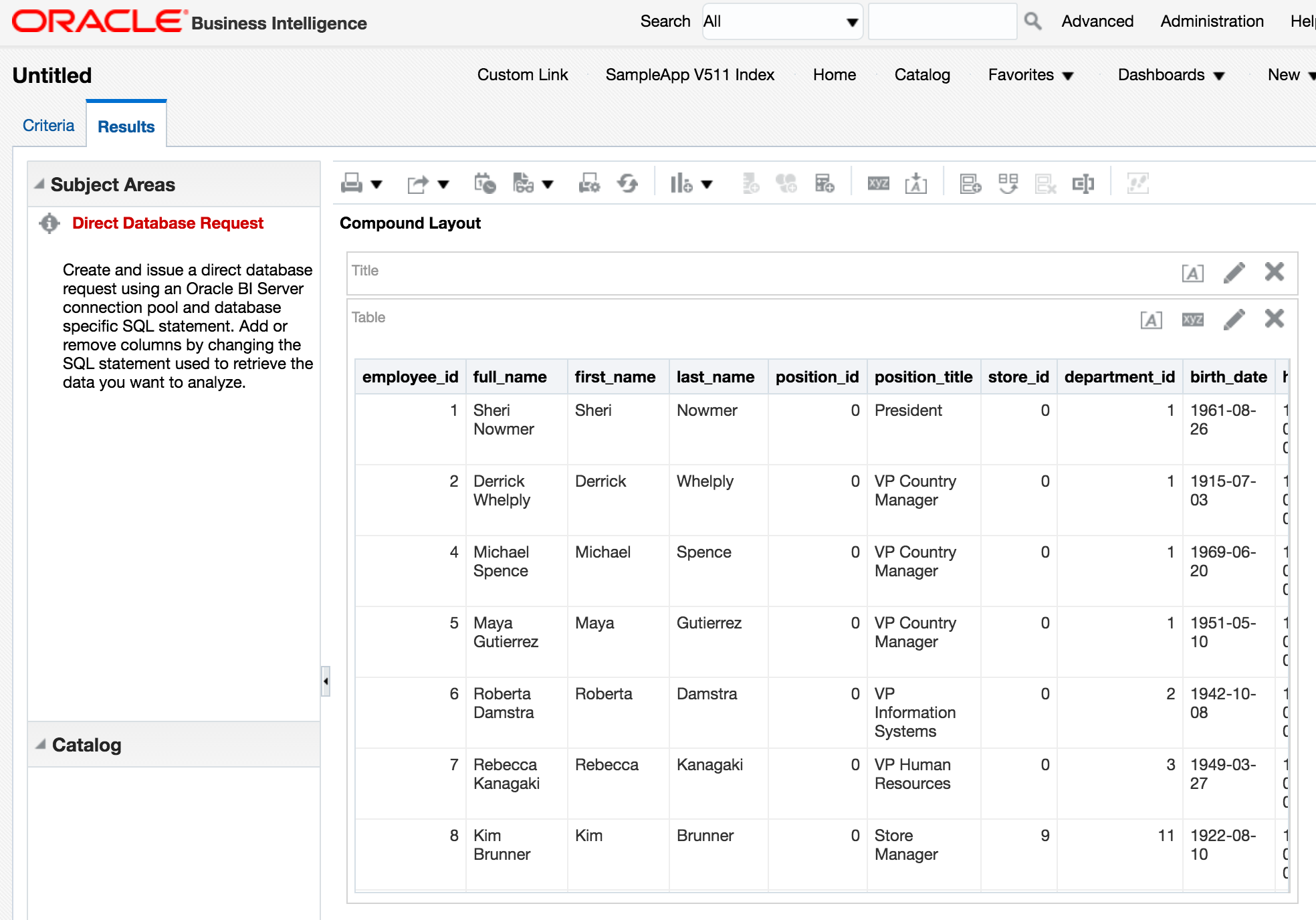
Nice. We can query data held in HDFS too, again with a Direct Database Request:
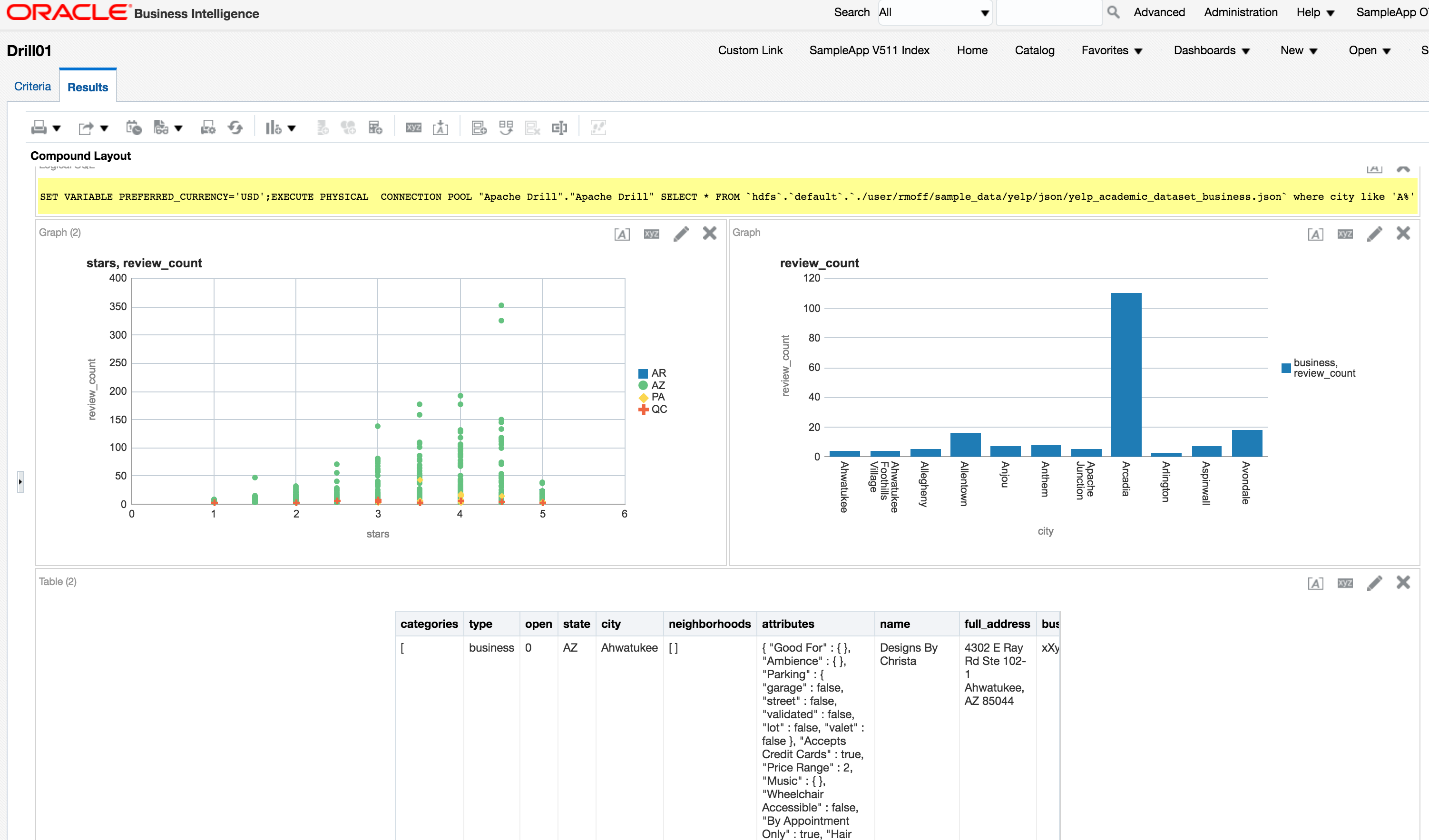
Exploring Drill data with OBIEE
So the above DDR prove the connectivity works. But as any ful kno, DDR is at best a 'tactical' solution, at worst, a complete hack and maintenance nightmare. Let's use the force luke, or at least, the RPD. The first obvious thing to do is Import Metadata from the connection pool that we've defined. But doing this, there's no objects shown:
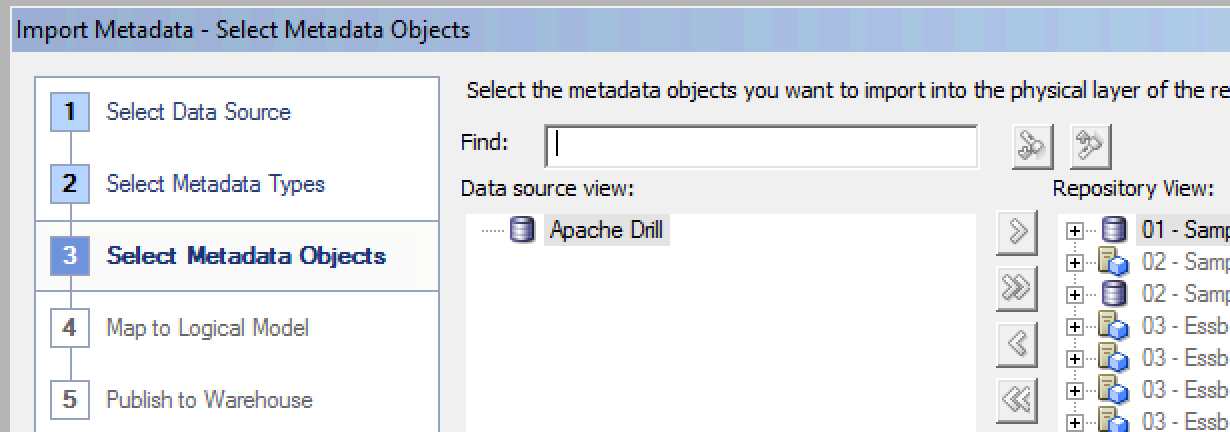
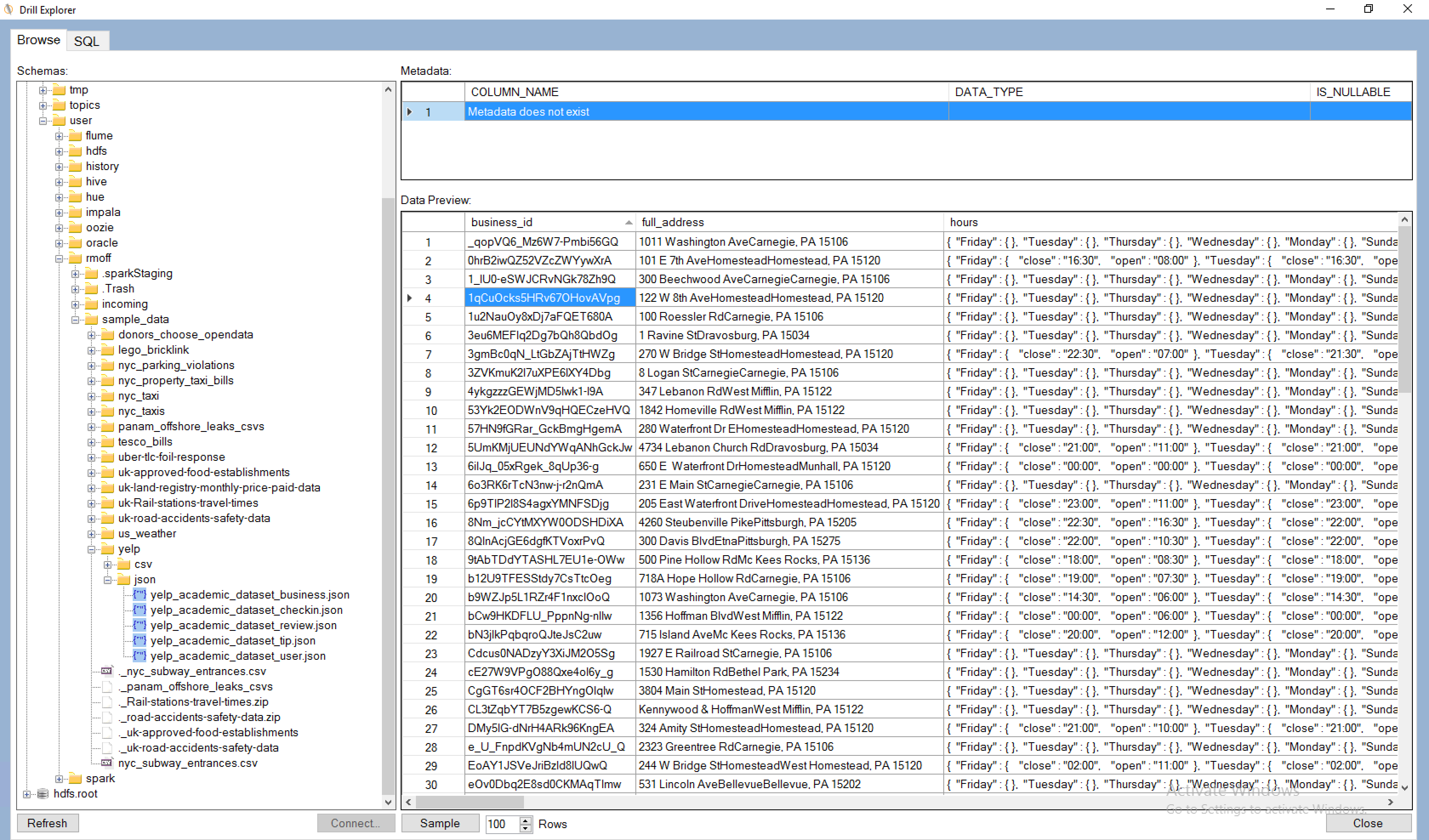
That's because 'tables' in Drill are not quite as clearly defined as in a standard RDBMS. A table could be a single file, multiple files matching a pattern, or even literally a table if connecting Drill to an RDBMS. So to expose a set of data through Drill, we define a view. This is where Drill Explorer comes in as it gives a simple GUI over the available files
from where you can use the SQL tab and Create As option to create a view
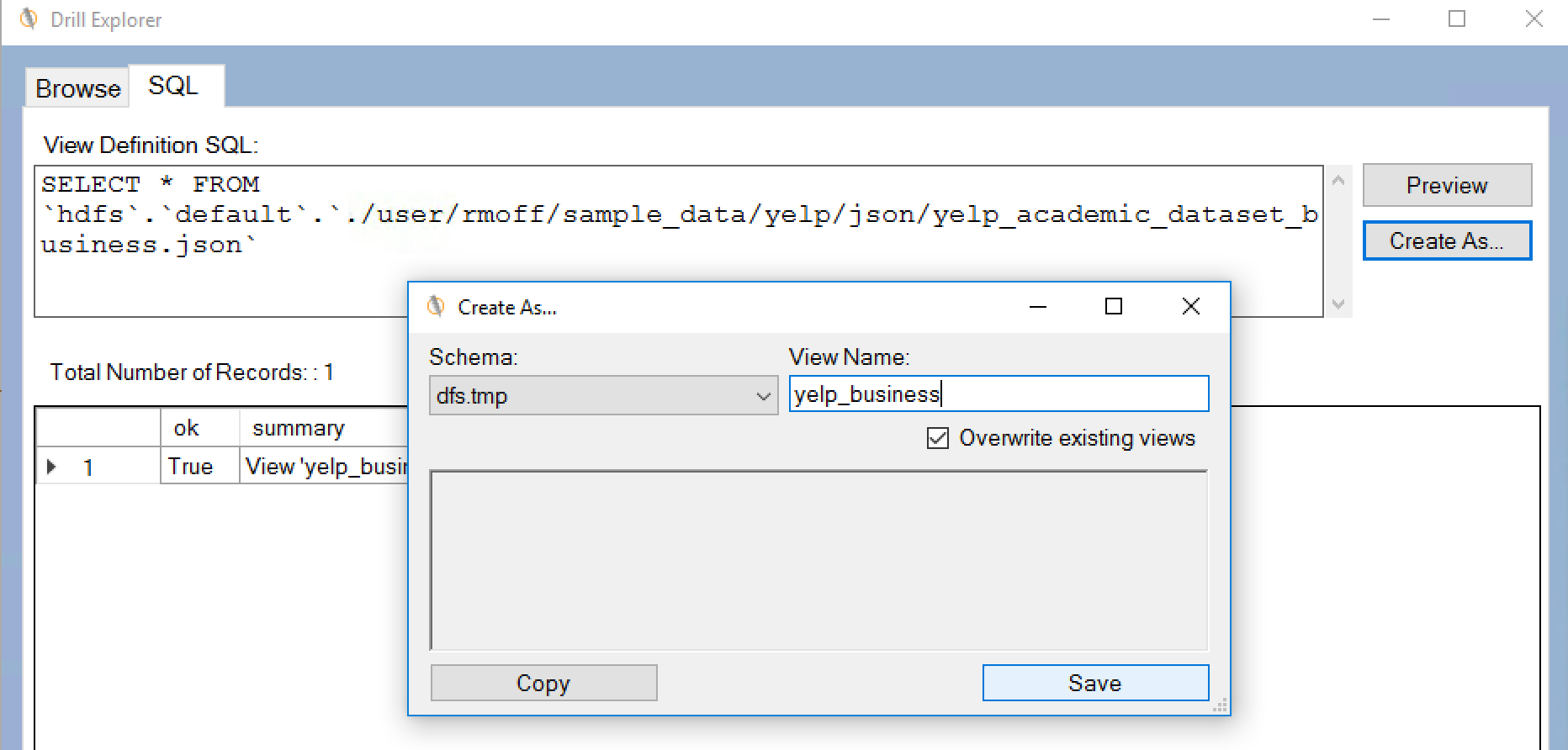
Having done this, launch the Import Metadata dialog again (right click the Connection Pool and select Import Metadata), and make sure you tick Views on the Metadata types to view. Now you'll see the object. Unfortunately, it just has a single column - *. I've not figured out yet how - if if it's possible - to get a view to explode out all columns in the underlying select clause. Import the view:
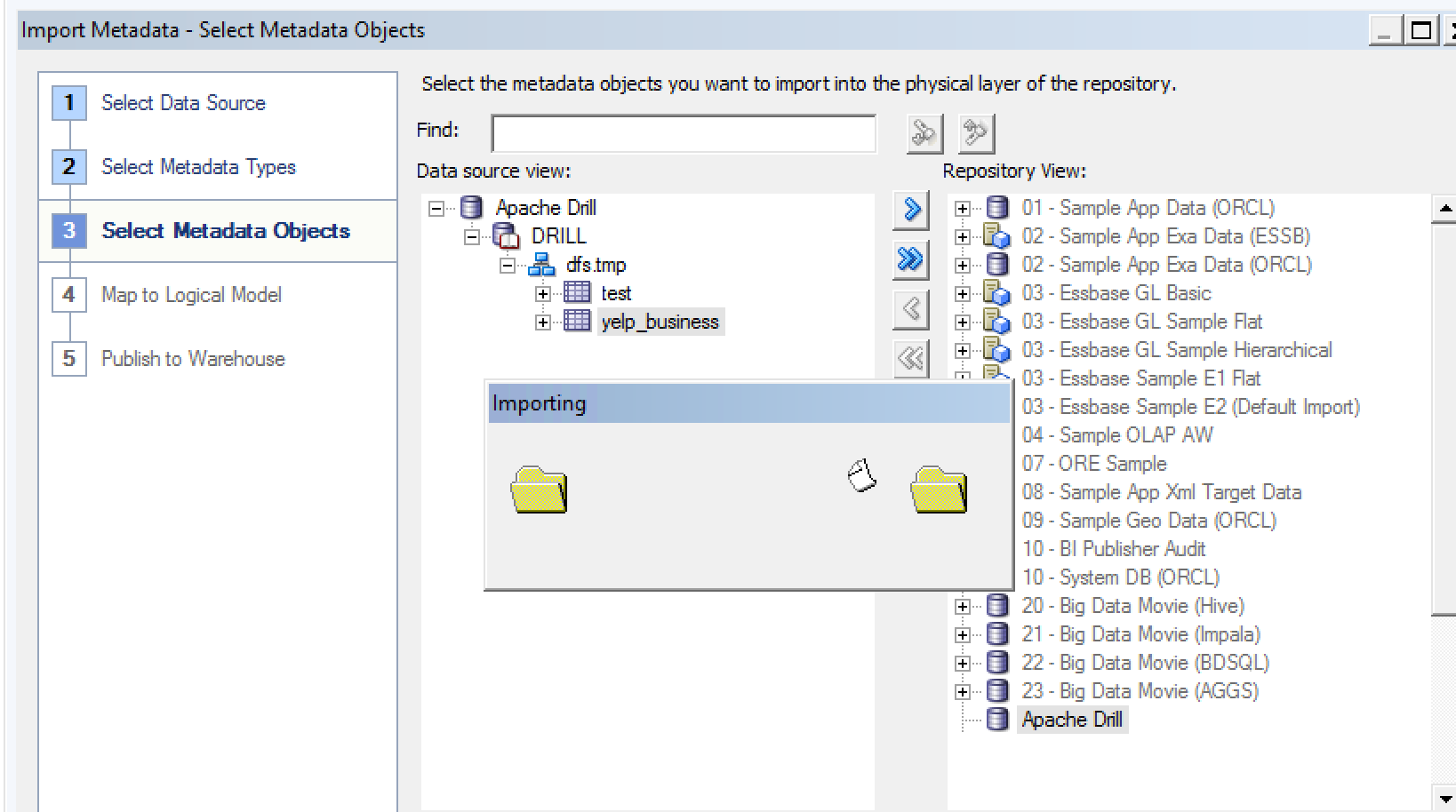
You'll get an error about the * column name, but the table and schema still get brought across.
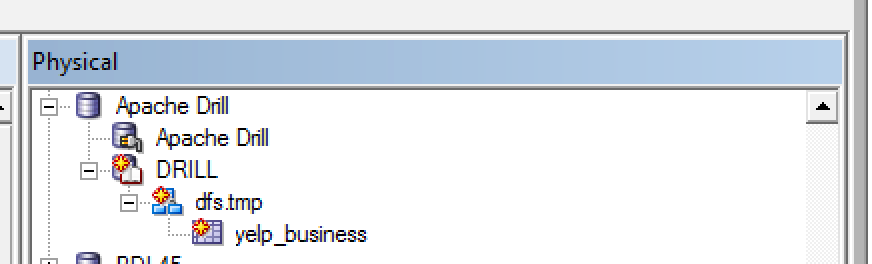
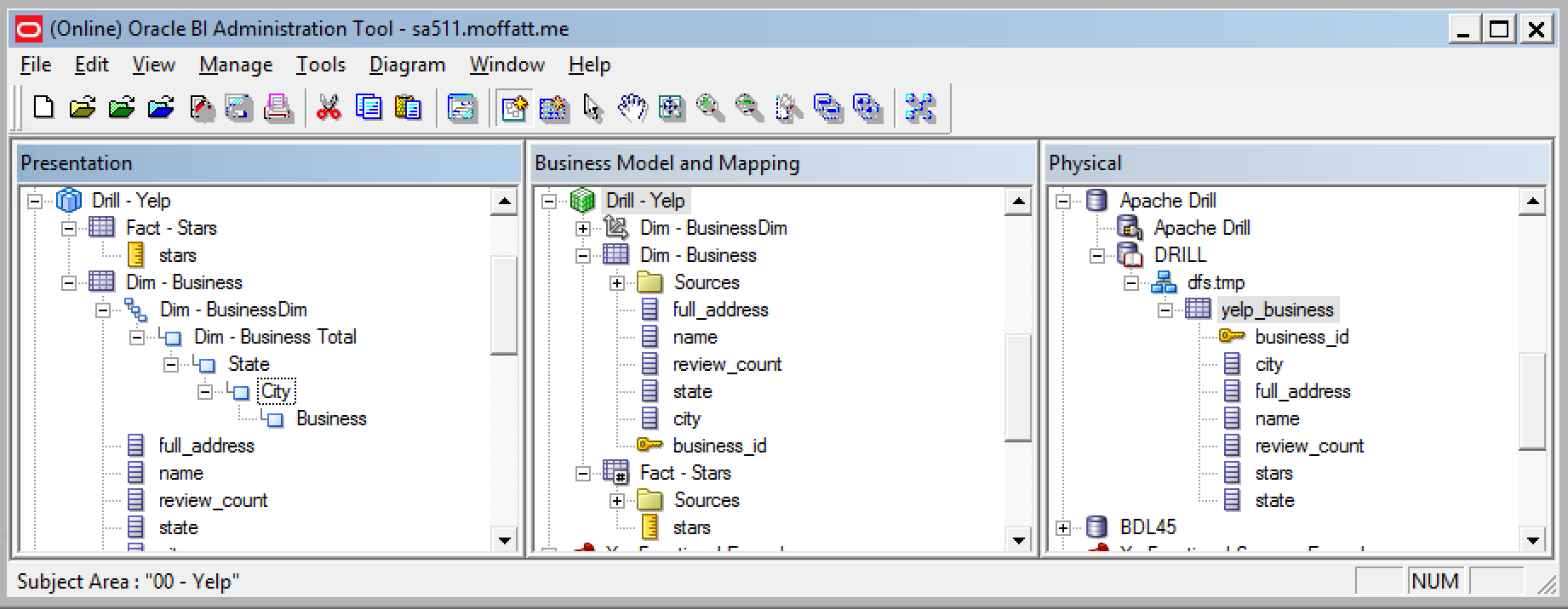
Now the slightly tedious bit - define each physical column, and define the physical and logical model, done very simplistically here:
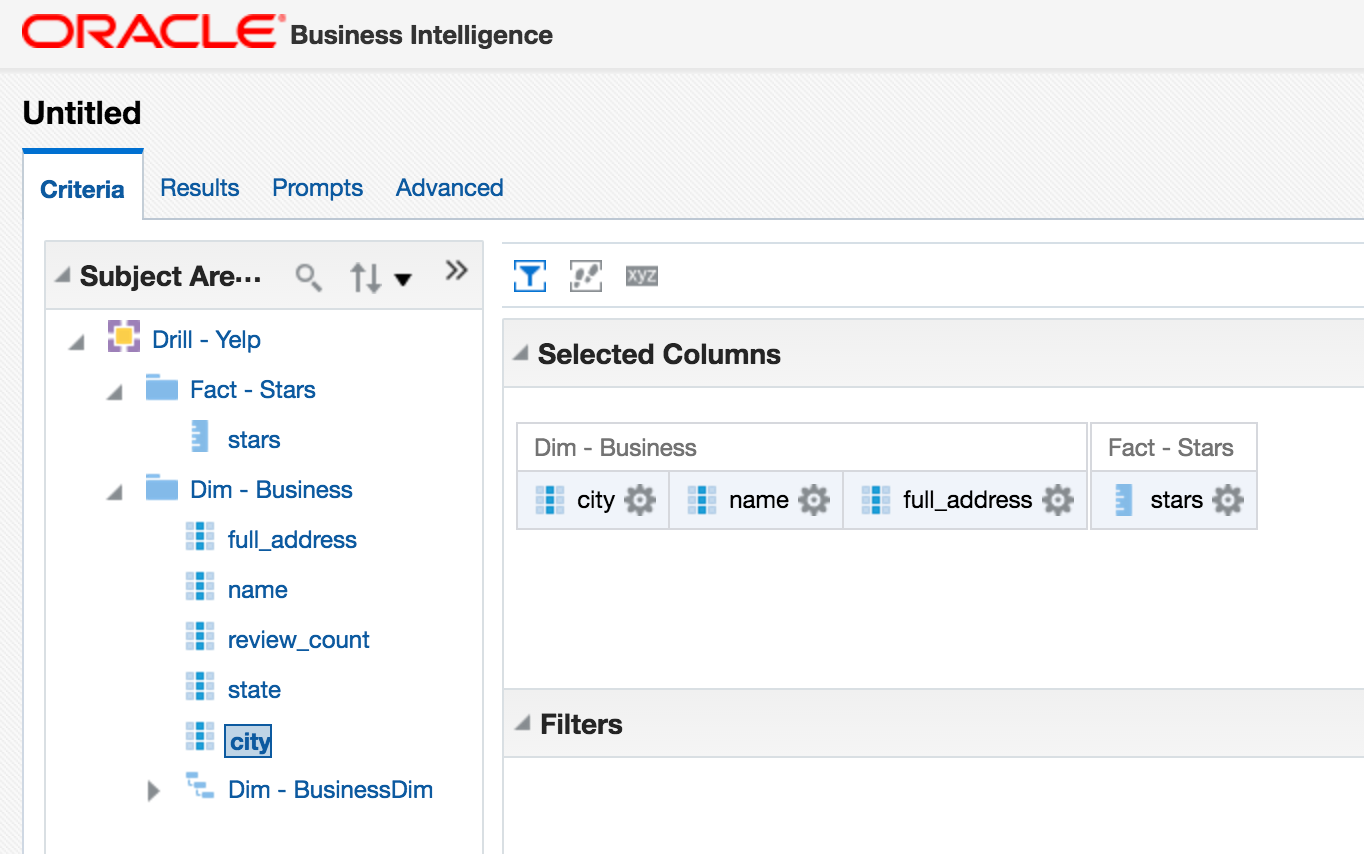
A simple query:
Aaaaaand a simple error:
State: HY000. Code: 16001. [nQSError: 16001] ODBC error state: S1000 code: 1040 message:
[MapR][Drill] (1040) Drill failed to execute the query:
select avg(T29568."stars") as c1, T29568."city" as c2, T29568."full_address" as c3, T29568."name" as c4 from "DRILL"."dfs.tmp"."yelp_business" T29568 group by T29568."city", T29568."full_address", T29568."name" order by 2, 4, 3
[30027]Query execution error. Details:[
PARSE ERROR: Encountered ". \"" at line 1, column 33.
Was expecting one of: ")" ... "ORDER" ... "LIMIT" ... "OFFSET" ... "FETCH" ... "," .... (HY000)
Looking at the query being run, OBIEE is using double quotation marks (") to quote identifiers, but Drill requires backtick (`) instead. Heading over to DB Features can fix this:
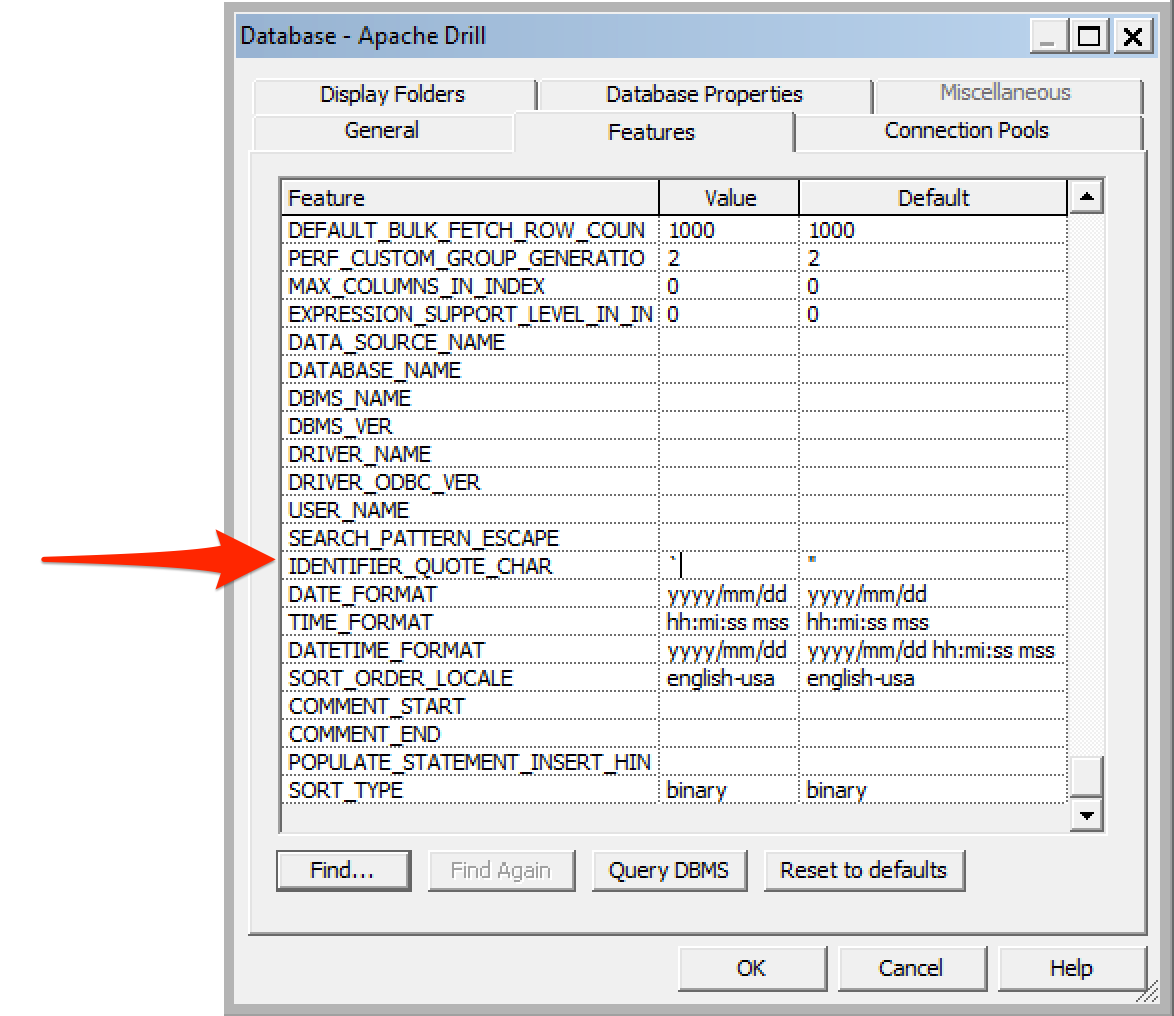
And refreshing the report gives:
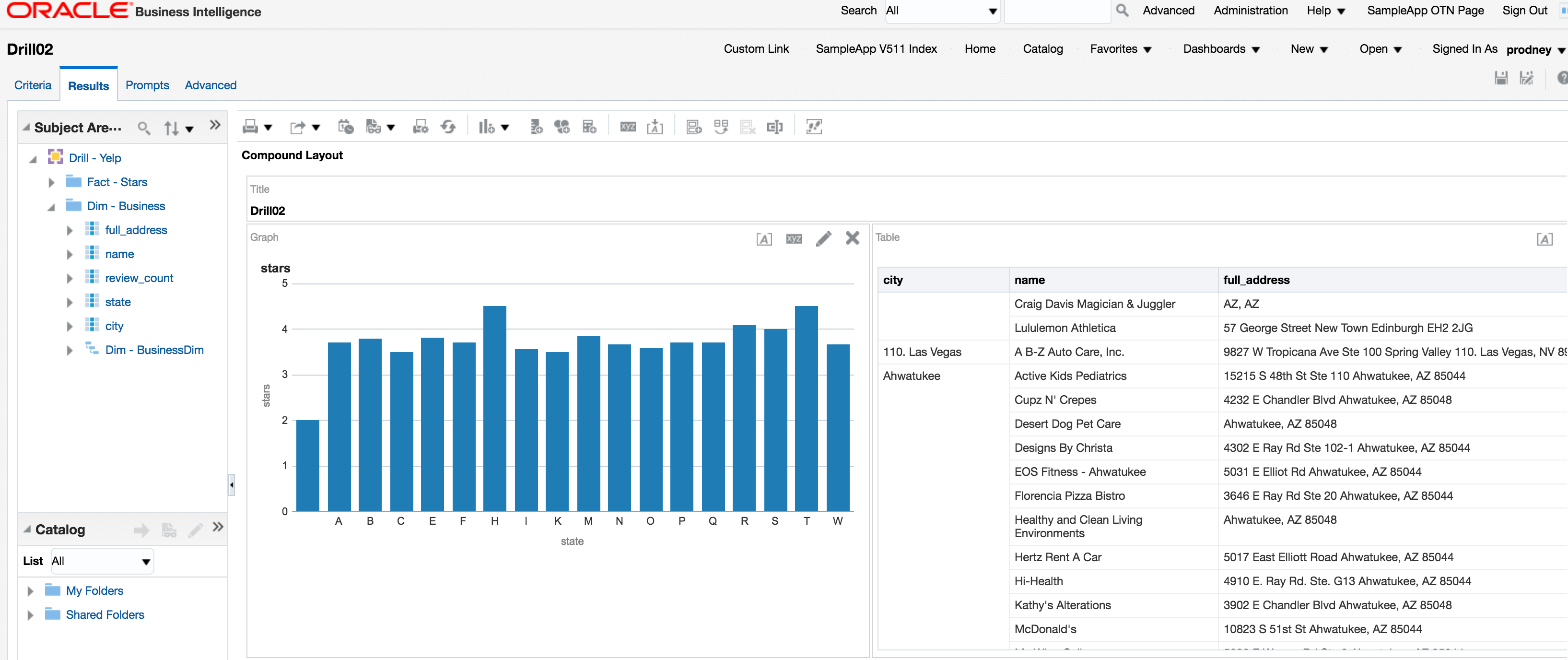
Conclusion
This is the very basics necessary to get up and running with OBIEE and Apache Drill. It would be good to see if there's an optimal, least-friction, way for getting tables in Drill exposed to OBIEE without needing to enter each physical column.
One of the many powerful features of Drill is being able to access nested and array JSON values, which I've discussed in my Introduction to Apache Drill post. The above examples just use root-level attributes, and could easily be expanded out to process some of the nested fields (such as hours in the business data above). For the time being this would be done with DDR, or a Drill view wrapped around it imported into the Physical layer of the RPD.