Enhanced Usage Tracking for OBIEE - Now Available as Open Source!

Introduction
OBIEE provides Usage Tracking as part of the core product functionality. It writes directly to a database table every Logical Query that hits the BI Server, including details of who ran it, when, and information about how it executed including for how long, how many rows, and so on. This in itself is a veritable goldmine of information about your OBIEE system. All OBIEE deployments should have Usage Tracking enabled, for supporting performance analysis, capacity planning, catalog rationalisation, and more.
What Usage Tracking doesn't track is interactions between the end user and the Presentation Services component. Presentation Services sits between the end user and the BI Server from where the actual queries get executed. This means that until a user executes an analysis, there's no record of their actions in Usage Tracking. There is this audit data available, but you have to manually enable and collect it, which can be tricky. This is where Enhanced Usage Tracking comes in. It enables the collection and parsing of every click a user makes in OBIEE. For an overview of the potential of this data, see the article here and here.
Today we're pleased to announce the release into open-source of Enhanced Usage Tracking! You can find the github repository here: https://github.com/RittmanMead/obi-enhanced-usage-tracking.
Highlights of the data that Enhanced Usage Tracking provides includes:
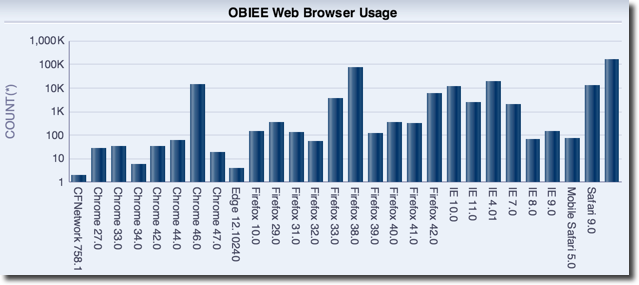
- Which web browsers do people use? Who is accessing OBIEE with a mobile device?
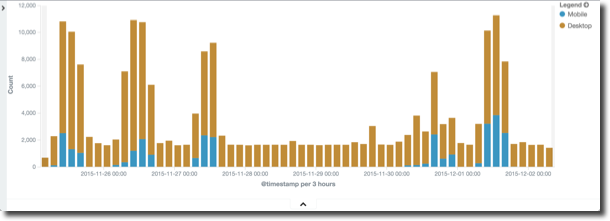
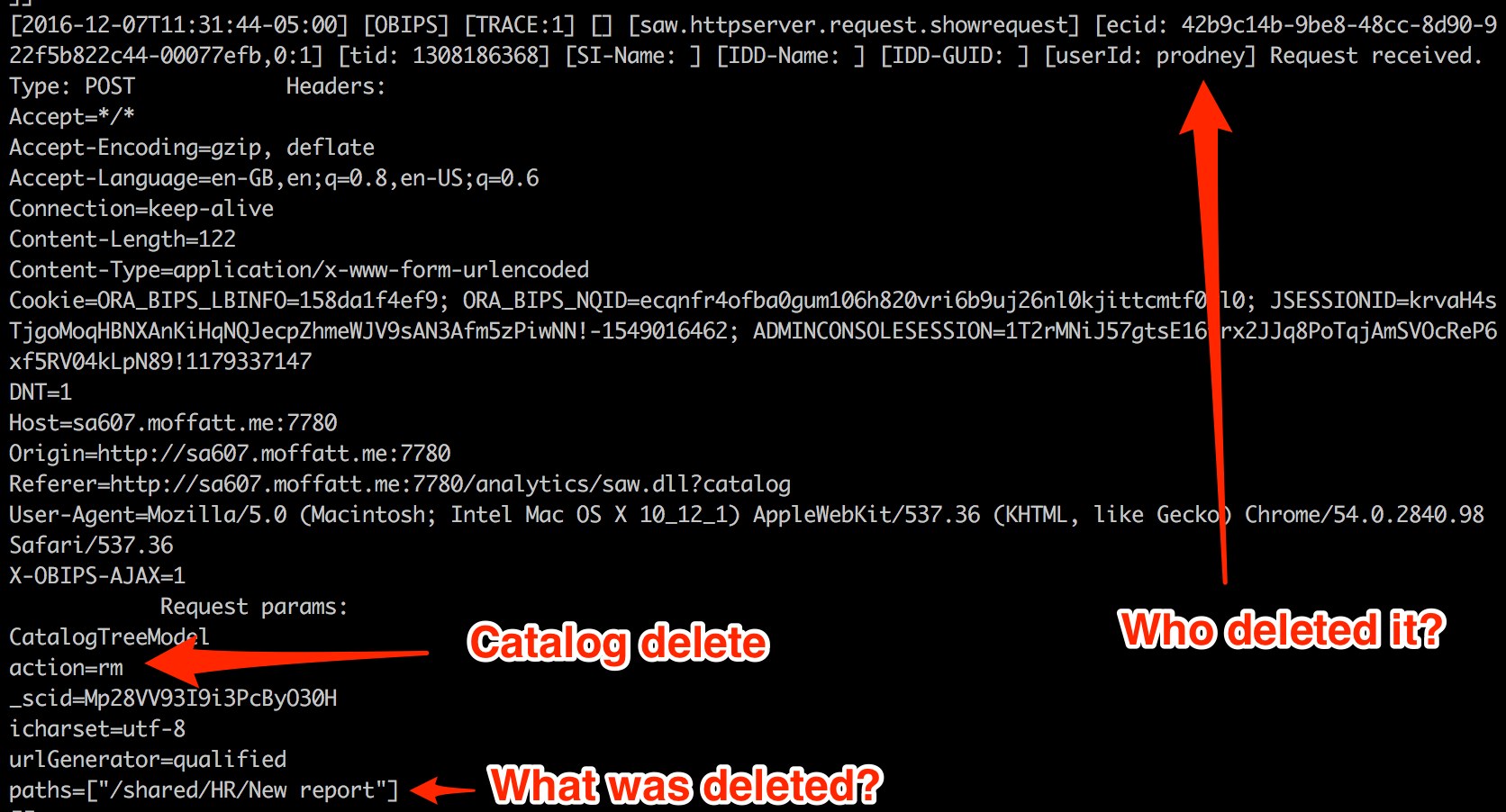
- Who deleted a catalog object? Who moved it?

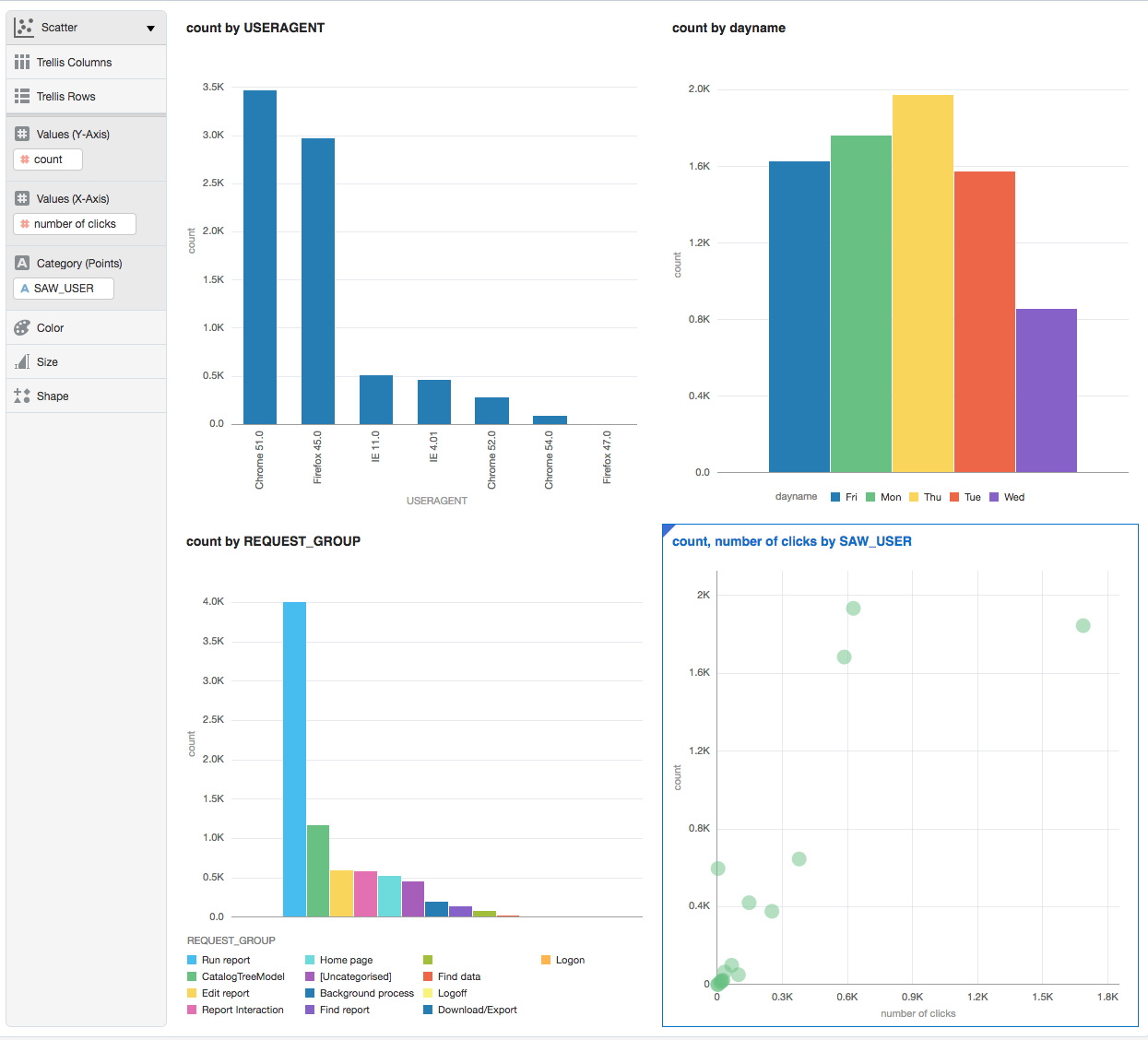
- What dashboards get exported to Excel most frequently, and by whom?

The above visualisations are from both Kibana, and OBIEE. The data from Enhanced Usage Tracking can be loaded into Elasticsearch, and is also available from Oracle tables too, hence you can put OBIEE itself on top of it, or DV:
How to use Enhanced Usage Tracking
See the github repository for full detail on how to install and run the code.
TODO
What's left TODO? Here are a few ideas if you'd like to help build on this tool. I've linked each title to the relevant github issue.
TODO 01
The sawlog is a rich source of lots of data, but the Logstash script has to know how to parse it. It's all down to the grok statement which identifies fields to extract and defined their deliniators. Use grokdebug.herokuapp.com to help master your syntax. From there, the data can be emitted to CSV and loaded into Oracle.
Here's an example of something yet to build - when items are moved and deleted in the Catalog, it is all logged. What, who, and when. The Logstash grok currently scrapes this, but the data isn't included in the CSV output, nor loaded into Oracle.
Don't forget to submit a pull request for any changes to the code that would benefit others in the community!
You'll also find loading the data directly into Elasticsearch easier than redefining the Oracle table DDL and load script each time, since in Elasticsearch the 'schema' can evolve based simply on the data that Logstash sends to it.
TODO 02
Version 5 of the Elastic stack was released in late 2016, and it would be good to test this code with it and update the README section above to indicate if it works - or submit the required changes needed for it to do so.
TODO 03
There's lots of possibilities for this data. Auditing who did what, when, is useful (e.g. who deleted a report?). Taking it a step further, are there patterns in user behaviour? Certain patterns of clicks that could be identified to highlight users who are struggling to find the data that they want? For example, opening lots of presentation folders in the Answers editor before adding columns to the analysis? Can we extend that to identify users who are struggling to use the tool and are going to "churn" (stop using it) and thus contact them before they do so to help resolve any issues they have?
TODO 04
At the moment the scripts are manual to invoke and run. It would be neat to package this up into a service (or set of services) that could run automagically at server boot.
Until then, using GNU screen is a handy hack for setting scripts running and being able to disconnect from the server without terminating them. It's like using nohup ... &, except you can reconnect to the session itself as and when you want to.
TODO 05
Click events have defined 'Request' types, and these I have roughly grouped together into 'Request Groups' to help describe what the user was doing (e.g. Logon / Edit Report / Run Report). Not all requests have been assigned to request groups. It would be useful to identify all request types, and refine further the groupings.
TODO 06
At the moment only clicks in Presentation Services are captured and analysed. I bet the same can be done for Data Visualization/Visual Analyzer too ...
Problems?
Please raise any issues on the github issue tracker. This is open source, so bear in mind that it's no-one's "job" to maintain the code - it's open to the community to use, benefit from, and maintain.
If you'd like specific help with an implementation, Rittman Mead would be delighted to assist - please do get in touch to discuss our rates.