Game of Thrones Series 8: Real Time Sentiment Scoring with Apache Kafka, KSQL, Google's Natural Language API and Python


Hi, Game of Thrones aficionados, welcome to GoT Series 8 and my tweet analysis! If you missed any of the prior season episodes, here are I, II and III. Finally, after almost two years, we have a new series and something interesting to write about! If you didn't watch Episode 1, do it before reading this post as it might contain spoilers!
Let's now start with a preview of the starting scene of Episode 2:

If you followed the previous season blog posts you may remember that I was using Kafka Connect to source data from Twitter, doing some transformations with KSQL and then landing the data in BigQuery using Connect again. On top of it, I was using Tableau to analyze the data.

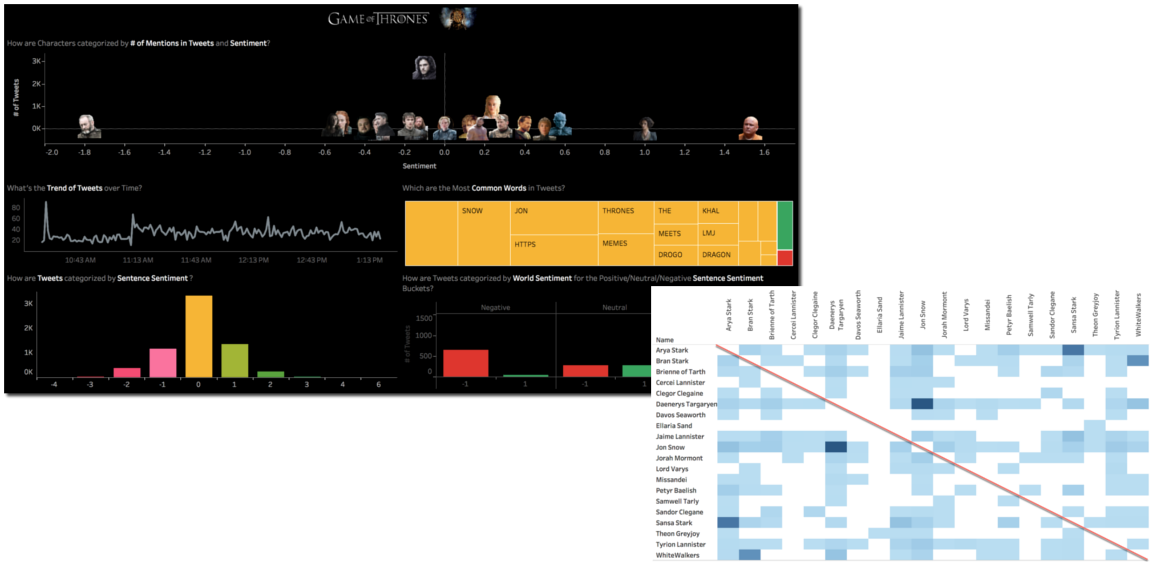
The above infrastructure was working fine and I have been able to provide insights like the sentiment per character and the "game of couples" analysing how a second character mentioned in the same tweet could change the overall sentiment.
The sentiment scoring was however done at visualization time, with the data extracted from BigQuery into Tableau at tweet level, scored with an external call to R, then aggregated and finally rendered.

As you might understand the solution was far from optimal since:
- The Sentiment scoring was executed for every query sent to the database, so possibly multiple times per dashboard
- The data was extracted from the source at tweet level, rather than aggregated
The dashboard indeed was slow to render and the related memory consumption huge (think about data volumes being moved around). Furthermore, Sentiment Scores were living only inside Tableau: if any other people/application/visualization tool wanted to use them, they had to recalculate from scratch.
My question was then: where should I calculate Sentiment Scores in order to:
- Do it only once per tweet, not for every visualization
- Provide them to all the downstream applications
The answer is simple, I need to do it as close to the source as possible: in Apache Kafka!
Sentiment Scoring in Apache Kafka
There are a gazillion different ways to implement Sentiment Scoring in Kafka, so I chose a simple method based on Python and Google's Natural Language API.
Google Natural Language API
Google's NL APIs is a simple interface over a pre-trained Machine Learning model for language Analysis and as part of the service it provides sentiment scoring.
The Python implementation is pretty simple, you just need to import the correct packages
from google.cloud import language_v1
from google.cloud.language_v1 import enumsInstantiate the LanguageServiceClient
client = language_v1.LanguageServiceClient()Package the tweet string you want to be evaluated in a Python dictionary
content = 'I'm Happy, #GoT is finally back!'
type_ = enums.Document.Type.PLAIN_TEXT
document = {'type': type_, 'content': content}And parse the response
response = client.analyze_sentiment(document)
sentiment = response.document_sentiment
print('Score: {}'.format(sentiment.score))
print('Magnitude: {}'.format(sentiment.magnitude))The result is composed by Sentiment Score and Magnitude:
- Score indicated the emotion associated with the content as Positive (Value > 0) or Negative (Value < 0)
- Magnitude indicates the power of such emotion, and is often proportional with the content length.
Please note that Google's Natural Language API is priced per document so the more content you send for scoring, the bigger your bill will be!
Creating a Kafka Consumer/Producer in Python
Once we fixed how to do Sentiment Scoring, it's time to analyze how we can extract a tweet from Kafka in Python. Unfortunately, there is no Kafka Streams implementation in Python at the moment, so I created an Avro Consumer/Producer based on Confluent Python Client for Apache Kafka. I used the jcustenborder/kafka-connect-twitter Connect, so it's always handy to have the Schema definition around when prototyping.
Avro Consumer
The implementation of an Avro Consumer is pretty simple: as always first importing the packages
from confluent_kafka import KafkaError
from confluent_kafka.avro import AvroConsumer
from confluent_kafka.avro.serializer import SerializerErrorthen instantiating the AvroConsumer passing the list of brokers, group.id useful, as we'll see later, to add multiple consumers to the same topic, and the location of the schema registry service in schema.registry.url.
c = AvroConsumer({
'bootstrap.servers': 'mybroker,mybroker2',
'group.id': 'groupid',
'schema.registry.url': 'http://127.0.0.1:8081'})Next step is to subscribe to a topic, in my case got_avro
c.subscribe(['got_avro'])and start polling the messages in loop
while True:
try:
msg = c.poll(10)
except SerializerError as e:
print("Message deserialization failed for {}: {}".format(msg, e))
break
print(msg.value())
c.close()In my case, the message was returned as JSON and I could extract the tweet Text and Id using the json package
text=json.dumps(msg.value().get('TEXT'))
id=int(json.dumps(msg.value().get('ID')))Avro Producer
The Avro Producer follows a similar set of steps, first including needed packages
from confluent_kafka import avro
from confluent_kafka.avro import AvroProducerThen we define the Avro Key and Value Schemas, in my case I used the tweet Id as key and included the text in the value together with the sentiment score and magnitude.
key_schema_str = """
{
"namespace": "my.test",
"name": "value",
"type": "record",
"fields" : [
{
"name" : "id",
"type" : "long"
}
]
}
"""
value_schema_str = """
{
"namespace": "my.test",
"name": "key",
"type": "record",
"fields" : [
{
"name" : "id",
"type" : "long"
},
{
"name" : "text",
"type" : "string"
},
{
"name" : "sentimentscore",
"type" : "float"
},
{
"name" : "sentimentmagnitude",
"type" : "float"
}
]
}
"""Then it's time to load the Key and the Value
value_schema = avro.loads(value_schema_str)
key_schema = avro.loads(key_schema_str)
key = {"id": id}
value = {"id": id, "text": text,"sentimentscore": score ,"sentimentmagnitude": magnitude}Creating the instance of the AvroProducer passing the broker(s), the schema registry URL and the Key and Value schemas as parameters
avroProducer = AvroProducer({
'bootstrap.servers': 'mybroker,mybroker2',
'schema.registry.url': 'http://schem_registry_host:port'
}, default_key_schema=key_schema, default_value_schema=value_schema)And finally produce the event defining as well the topic that will contain it, in my case got_avro_sentiment.
avroProducer.produce(topic='got_avro_sentiment', value=value, key=key)
avroProducer.flush()The overall Producer/Consumer flow is needless to say, very easy

And it works!
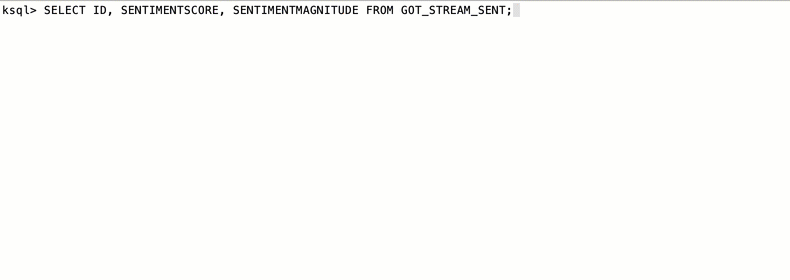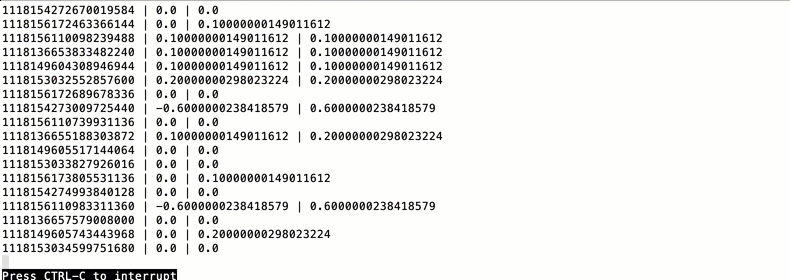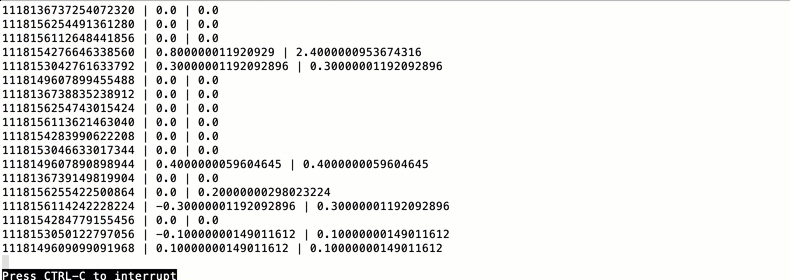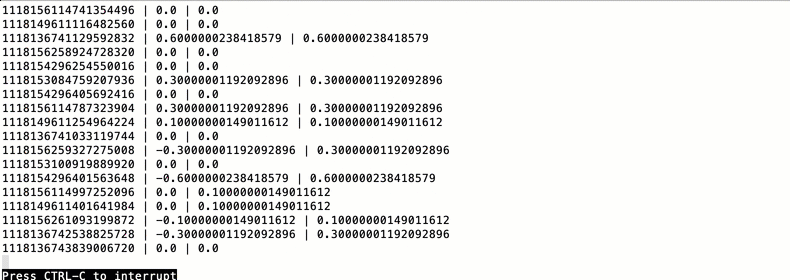
Parallel Sentiment Scoring
One thing I started noticing immediately, however, is that especially on tweeting peaks, the scoring routine couldn't cope with the pace of the incoming tweets: a single python Consumer/Producer was not enough. No problem! With Kafka, you can add multiple consumers to the same topic, right?
Of course Yes! But you need to be careful.
Consumer Groups and Topic Partitions
You could create multiple consumers on different Consumer Groups (defined by the group.id parameter mentioned above), but by doing this you're telling Kafka that those consumers are completely independent, thus Kafka will send each one a copy of every message. In our case, we'll simply end up scoring N times the same message, one for each consumer.
If, on the other hand, you create multiple consumers with the same consumer group, Kafka will treat them as unique consuming process and will try to share the load amongst them. However, it will do so only if the source topic is partitioned and will exclusively associate each consumer to one (or more) topic partitions! To read more about this check the Confluent documentation.
The second option is what we're looking for, having multiple threads reading from the same topic and splitting the tweet workload, but how do we split an existing topic into partitions? Here is where KSQL is handy! If you don't know about KSQL, read this post!
With KSQL we can define a new STREAM sourcing from an existing TOPIC or STREAM and the related number of partitions and partition key (the key's hash will be used to assign deterministically a message to a partition). The code is the following
CREATE STREAM <NEW_STREAM_NAME>
WITH (PARTITIONS=<NUMBER_PARTITIONS>)
AS SELECT <COLUMNS>
FROM <EXISTING_STREAM_NAME>
PARTITION BY <PARTITION_KEY>;Few things to keep in mind:
- Choose the number of partitions carefully, the more partitions for the same topic, the more throughput but at the cost of extra complexity.
- Choose the
<PARTITION_KEY>carefully: if you have 10 partitions but only 3 distinct Keys, then 7 partitions will not be used. If you have 10 distinct keys but 99% of the messages have just 1 key, you'll end up using almost always the same partition.
Yeah! We can now create one consumer per partition within the same Consumer Group!
Joining the Streams
As the outcome of our process so far we have:
- The native
GOT_AVROStream coming from Kafka Connect, which we divided into 6 partitions using the tweetidas Key and namedGOT_AVRO_PARTITIONED. - A
GOT_AVRO_SENTIMENTStream that we created using Python and Google's Natural Language API, withidas Key.
The next logical step would be to join them, which is possible with KSQL by including the WITHIN clause specifying the temporal validity of the join. The statement is, as expected, the following:
SELECT A.ID, B.ID, A.TEXT, B.SENTIMENTSCORE, B.SENTIMENTMAGNITUDE
FROM GOT_AVRO_PARTITIONED A JOIN GOT_AVRO_SENTIMENT B
WITHIN 2 MINUTES
ON A.ID=B.ID;
Please note that I left a two minute window to take into account some delay in the scoring process. And as you would expect I get............ 0 results!

Reading the documentation better gave me the answer: Input data must be co-partitioned in order to ensure that records having the same key on both sides of the join are delivered to the same stream task.
Since the GOT_AVRO_PARTITIONED stream had 6 partitions and GOT_AVRO_SENTIMENT only one, the join wasn't working. So let's create a 6-partitioned version of GOT_AVRO_SENTIMENT.
CREATE STREAM GOT_AVRO_SENTIMENT_PARTITIONED
WITH (PARTITIONS=6) AS
SELECT ID,
TEXT,
SENTIMENTSCORE,
SENTIMENTMAGNITUDE
FROM GOT_AVRO_SENTIMENT
PARTITION BY ID;Now the join actually works!

Next topics are: pushdown to Google's BigQuery and visualization using Google's Data Studio! But this, sadly, will be for another post! See you soon, and enjoy Game of Thrones!