Oracle AutoML UI at a glance


At the RMOUG 2023 training days, I co-presented a paper with my colleague Hannah Patrick titled "Data Science - Your Path to Predictive Analytics".
Today I'd like to share with you an overview of the part of the paper that focused on the Oracle AutoML User Interface. We will automatically train 5 models on a table with 130k+ wine reviews, in order to find the best model to predict if a bottle of wine is going to be 'Good' or 'Bad'. Finally, we will expose the model as a RESTful web service.
So, what is Oracle AutoML?
Well, it's a "platform" that Oracle has provided us with to quickly get up and running to create models against our dataset, without requiring advanced data science expertise (that requirement might come later). It's a part of the Oracle Machine Learning (OML) offering. With AutoML we can easily prepare the data, choose which algorithms we want, select features (i.e. columns), and train multiple models at once to generate accurate predictions. The AutoML platform uses AI/ML to automate the entire process, making it faster and more efficient to get started on generating predictions.
The Oracle AutoML platform also includes ways to evaluate different models against your data, deploy them to production and monitor their performance. The underlying Python package, called oracle-ads (try pip install oracle-ads today!) , provides a wide range of ML algorithms, Random Forest, Neural Networks, Natural Language Processing and more.
OML AutoML User Interface (UI) makes getting up and running with machine learning quick and easy on an Autonomous Data Warehouse (ADW) instance. It gives us an easy to use interface that automates repetitive and time consuming tasks that are normally left to expert data scientists, while simplifying machine learning for regular users, often referred to as "citizen data scientists". OML AutoML UI accelerates the machine learning process from model building to model deployment.
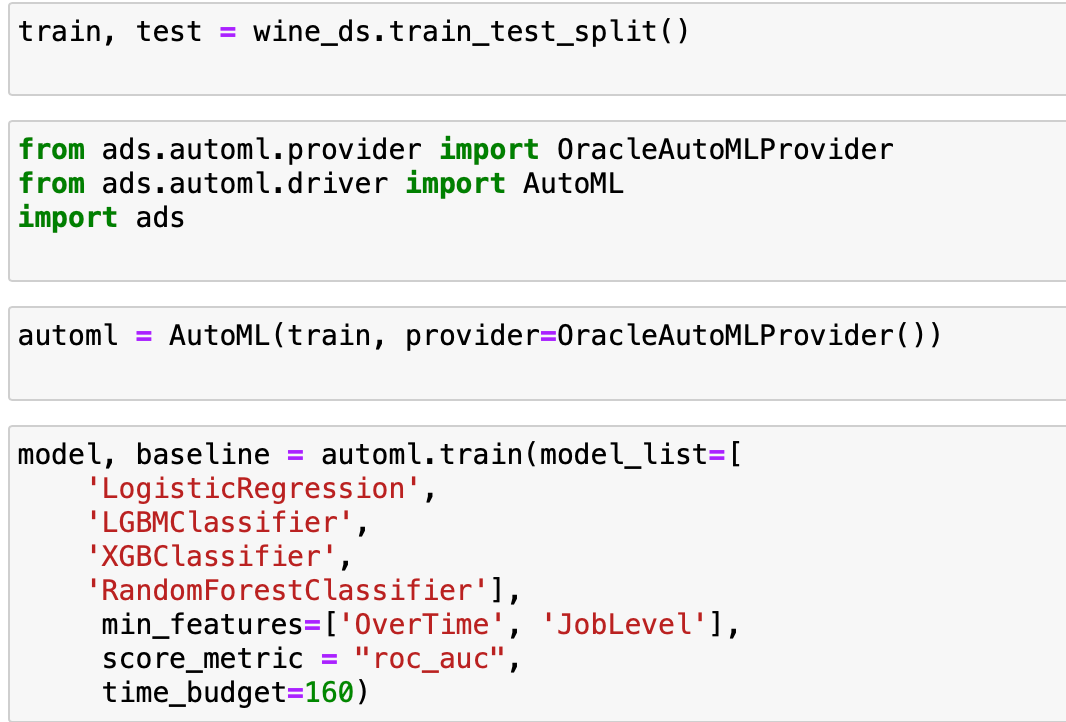
AutoML and Python
The AutoML Python libraries are provided in the oracle-ads (Accelerated Data Science) package. We won't really go in to that here, but it's important to know where to find the gritty details, once you want to expand on what the automatically generated models bring to the table.
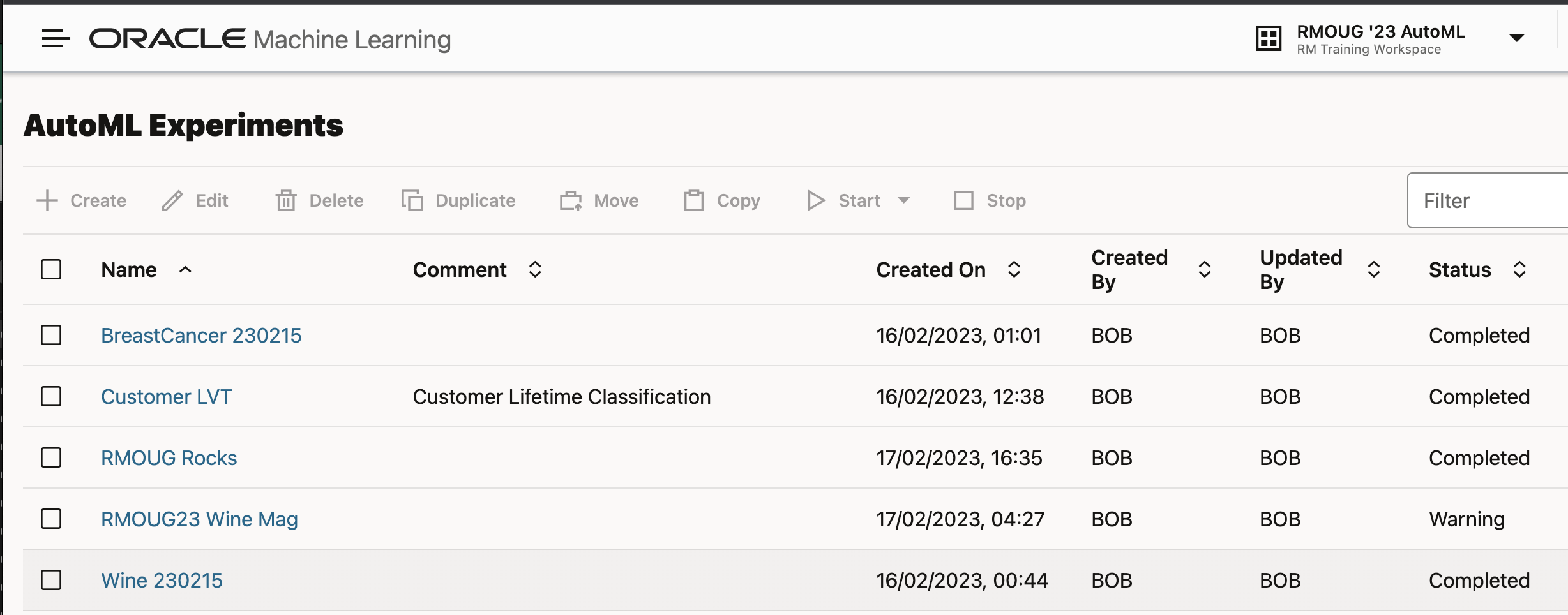
AutoML Experiments
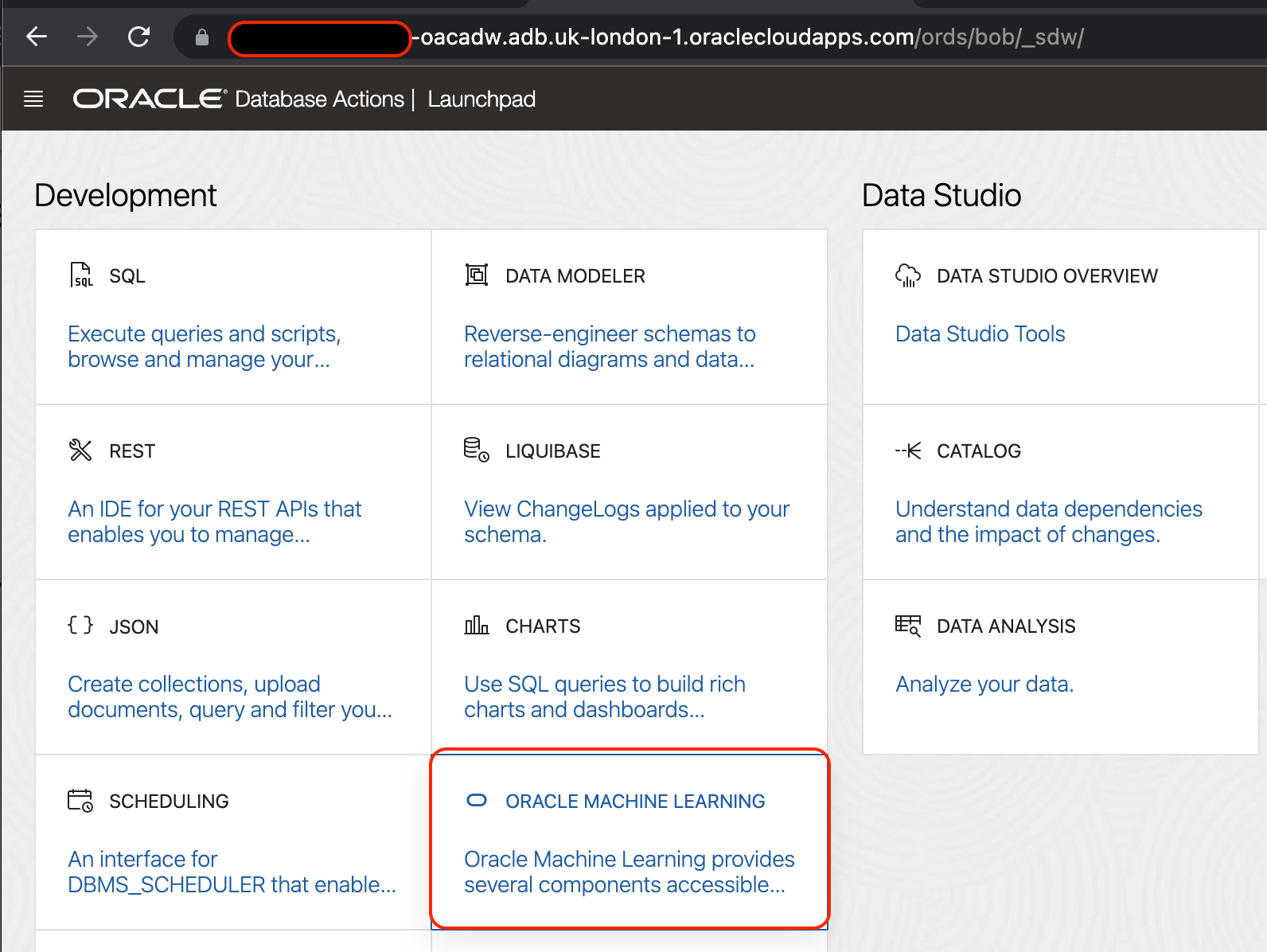
The AutoML UI provides us with a wizard-like driven approach to create multiple prediction models against the same dataset. To start a new experiment, navigate to Machine Learning tile on the ADW Database Actions page, or simply point your browser to https://yourinstance-name.adb.<your-region>.oraclecloudapps.com/oml/
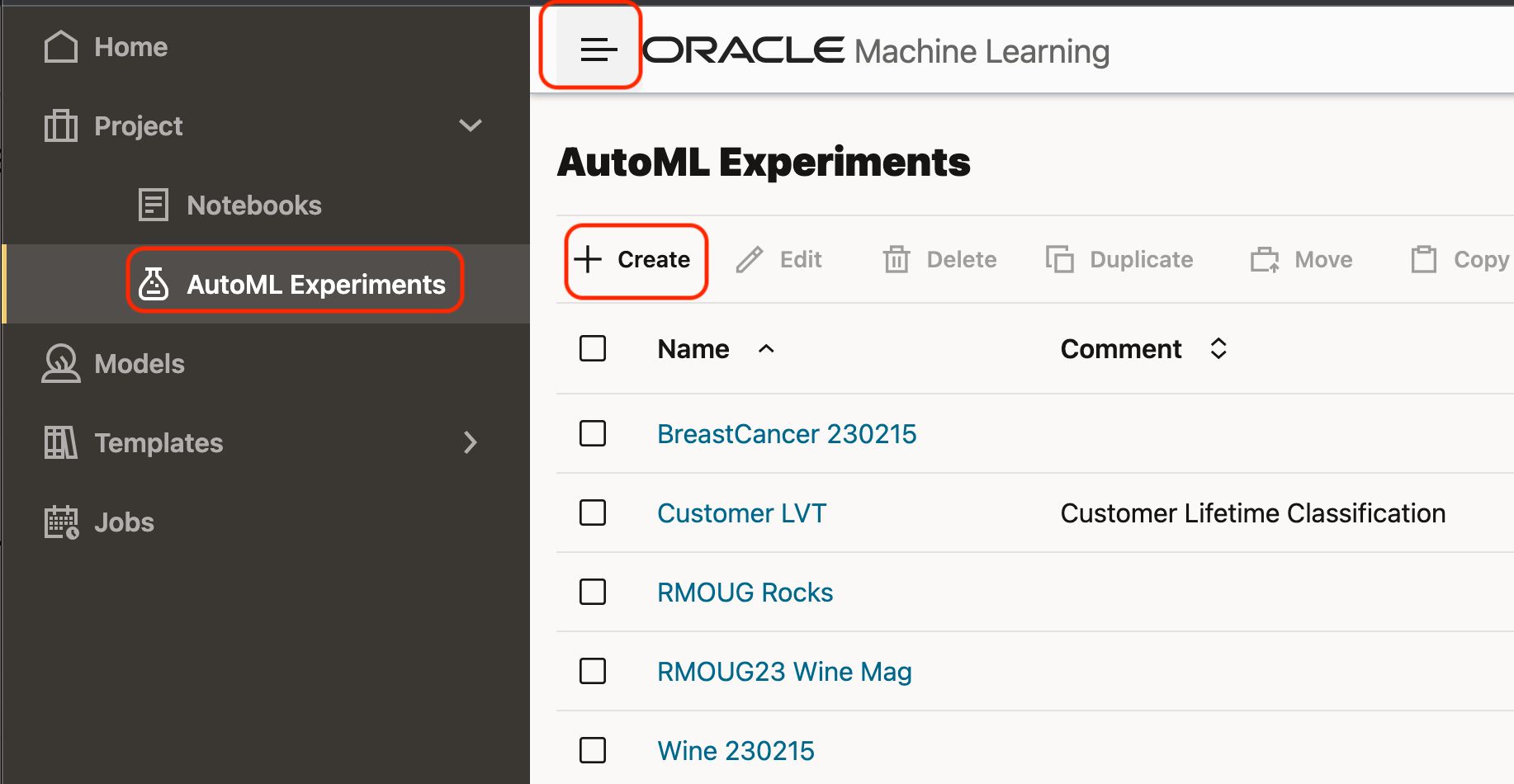
To create a new experiment, navigate to the "Hamburger" icon and then select "AutoML Experiments", and then click the "+" icon to create a new experiment.
1. We select the table or view that contains our training dataset and indicate which column is our prediction target. The Case ID is an optional configuration that should indicate a unique identifier for each observation (row) in our dataset. This will be excluded in the ML training, but can be useful later on, if we want to link the results back to the original dataset.
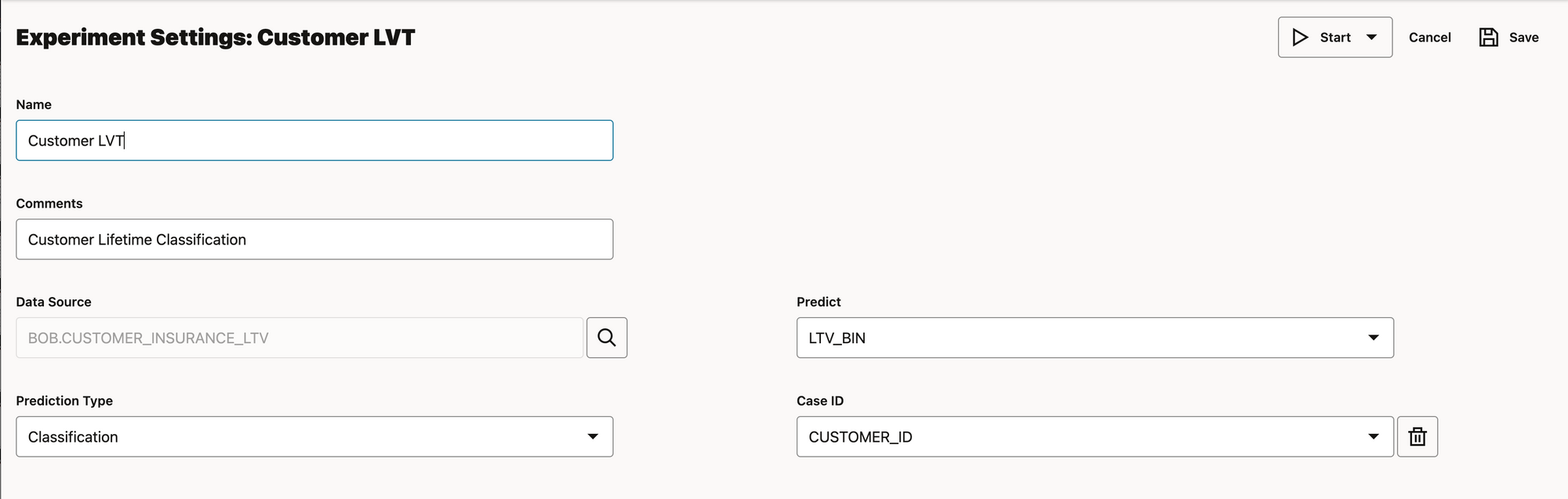
2. Next we indicate which features (columns) are to be considered for the trianing and which ones are not to be included.
Say we want to predict if a bottle of wine is going to be good or bad. We have a table with wine reviews and points awarded to each wine. We have decided that any wine getting 90/100 points is 'Good' and everything else is 'Bad' (Although I'd suspect my friend Paul Shilling might put the threshold at around 50/100 ;) )
Our table already contains the Points column, as well as the Wine_Score column. We must exclude the Points column from consideration. It makes no sense to include it as part of the input features, as if we knew the Points, we wouldn't need a model to determine the quality! Makes sense?
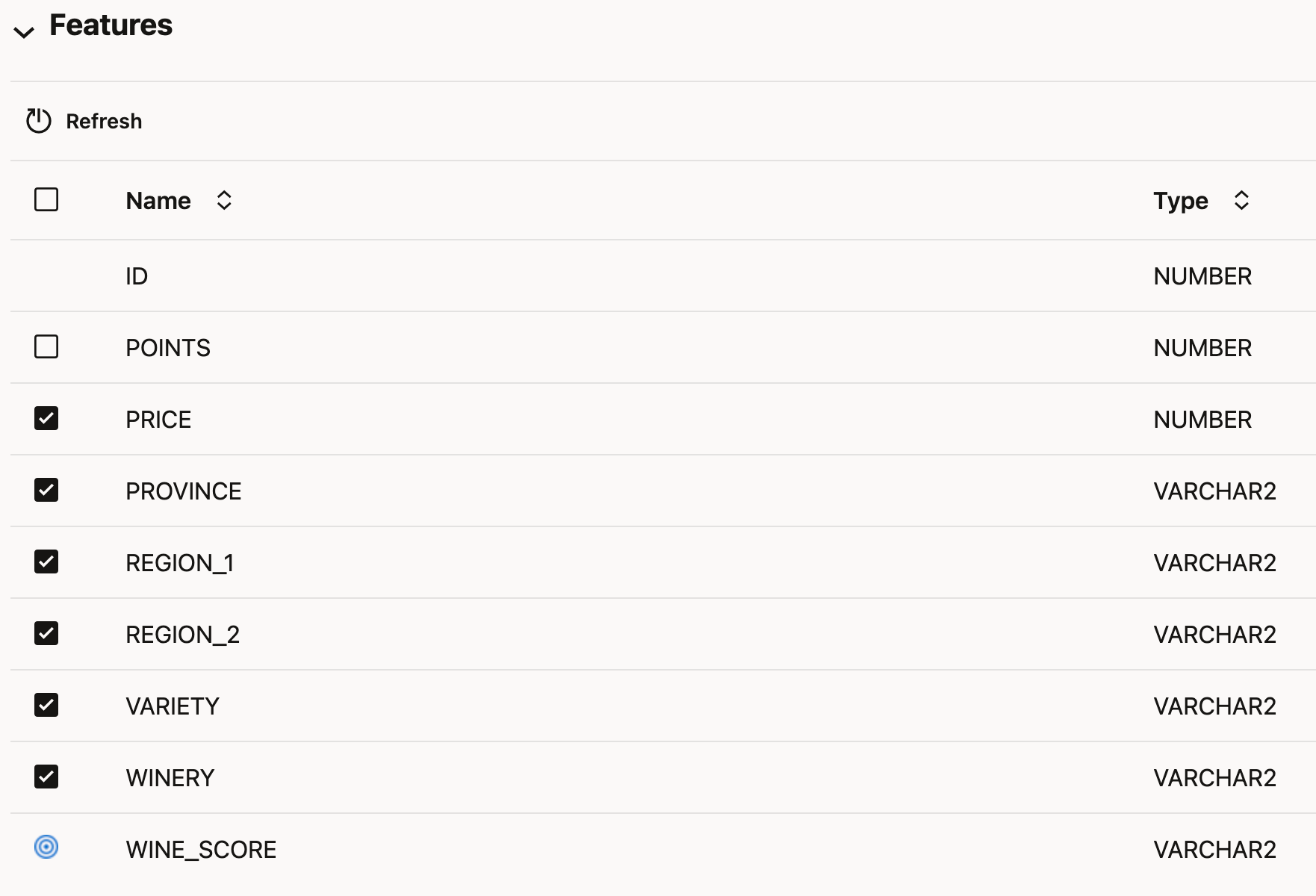
During the experiment run, AutoML will consider these features but eventually drop those it deems of little significance.
3. We then choose the type of prediction, whether it is a classification [discrete] or a regression [continuous]. We then have a set of machine learning algorithms to chose from and include in the experiment. If we already know that, e.g. Neural Networks wouldn't make any sense, we would not waste time and effort to train such a model during our experiment.

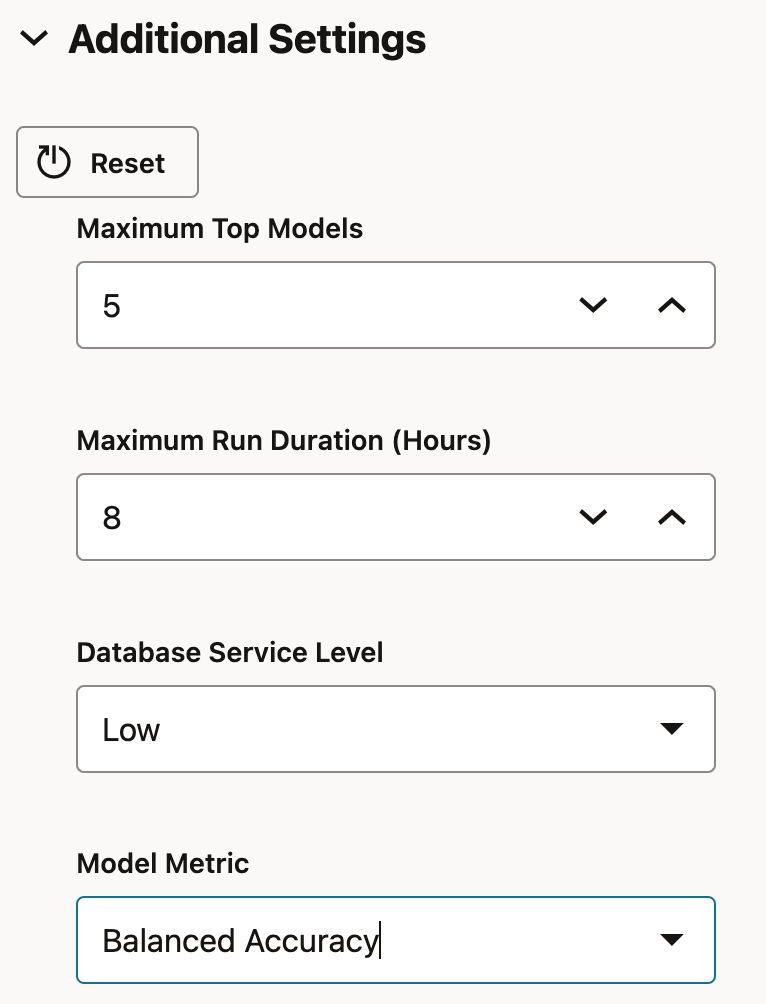
4. Additional Settings includes:
- How many top models we want to see returned
- Maximum runtime duration for the entire expirement
- ADW database service level (low, medium or high) to use to run the experiment and finally
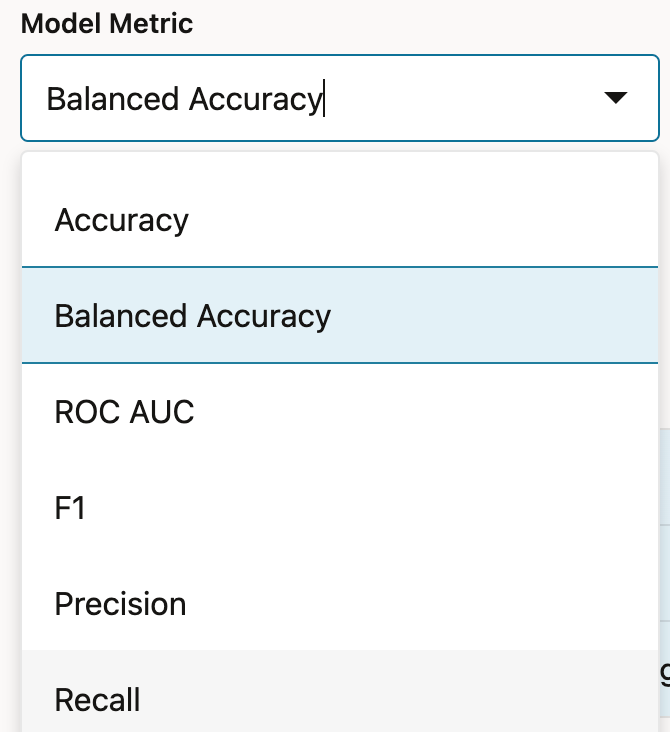
- Which model metric to score the models by
The last setting tells AutoML which result model assessment metric to order the models by, in order to decide which model performed the best.
When we have completed configuring the experiment, it's then time to "Save" and "Run" it. Running the experiment will send the instructions to the ADW to create, train and score each model against the input dataset and return the results ordered by the "Model Metric". An experiment can be run in two different modes; "Fast Results" or "Better Accuracy." The experiment below was run for Fast Results and completed in about 22 minutes on a dataset of just north of 130k rows. Same experiment with Better Accuracy ran in just over 2h.
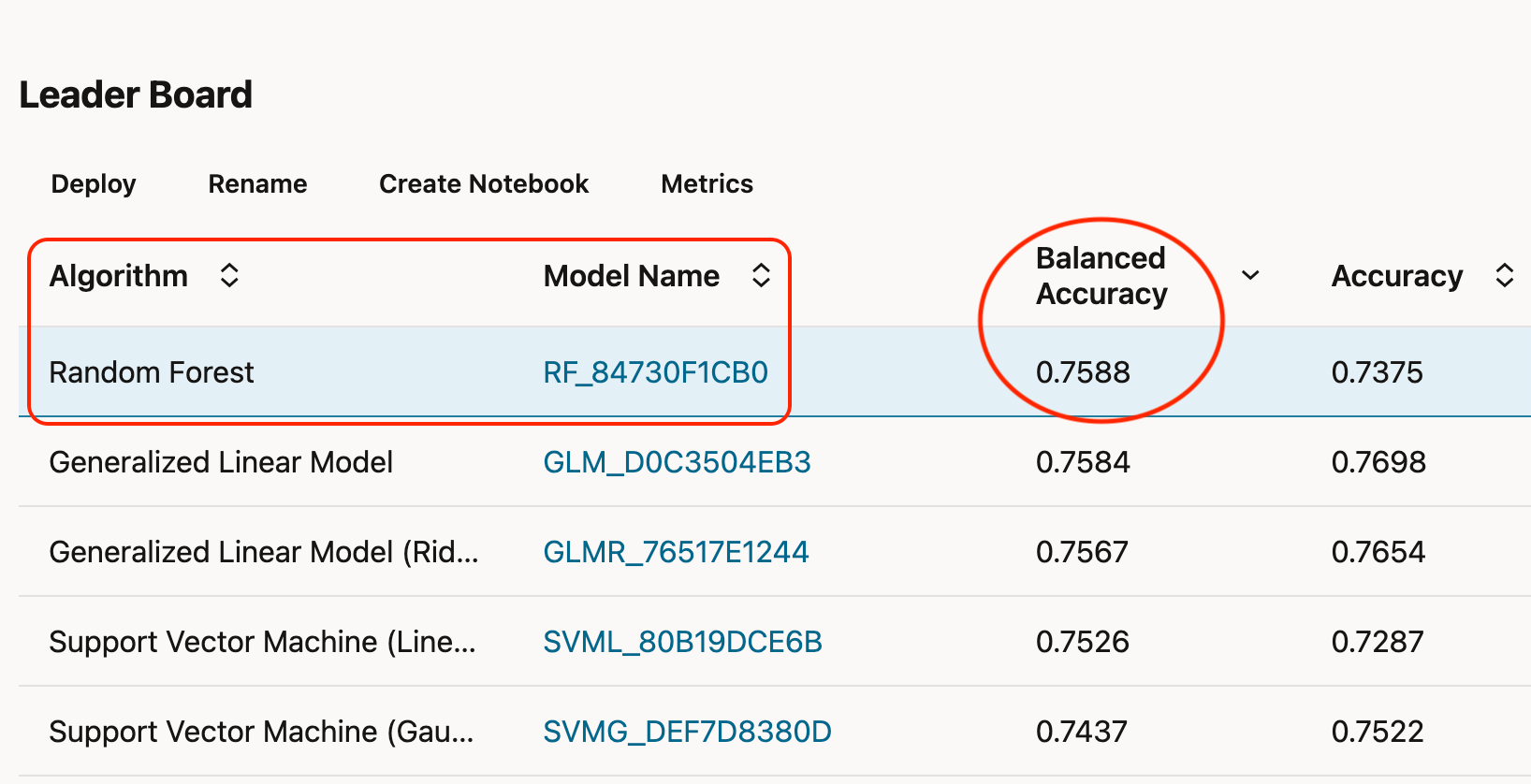
Each model's detailed performance can be viewed, and its confusion matrix reviewed. The 6 features AutoML chose for this model can be seen below. This means, in order to run a new prediction on a wine, we must provide it with these 6 columns. Keep this in mind later on, when we start sending a JSON payload to the model deployment.
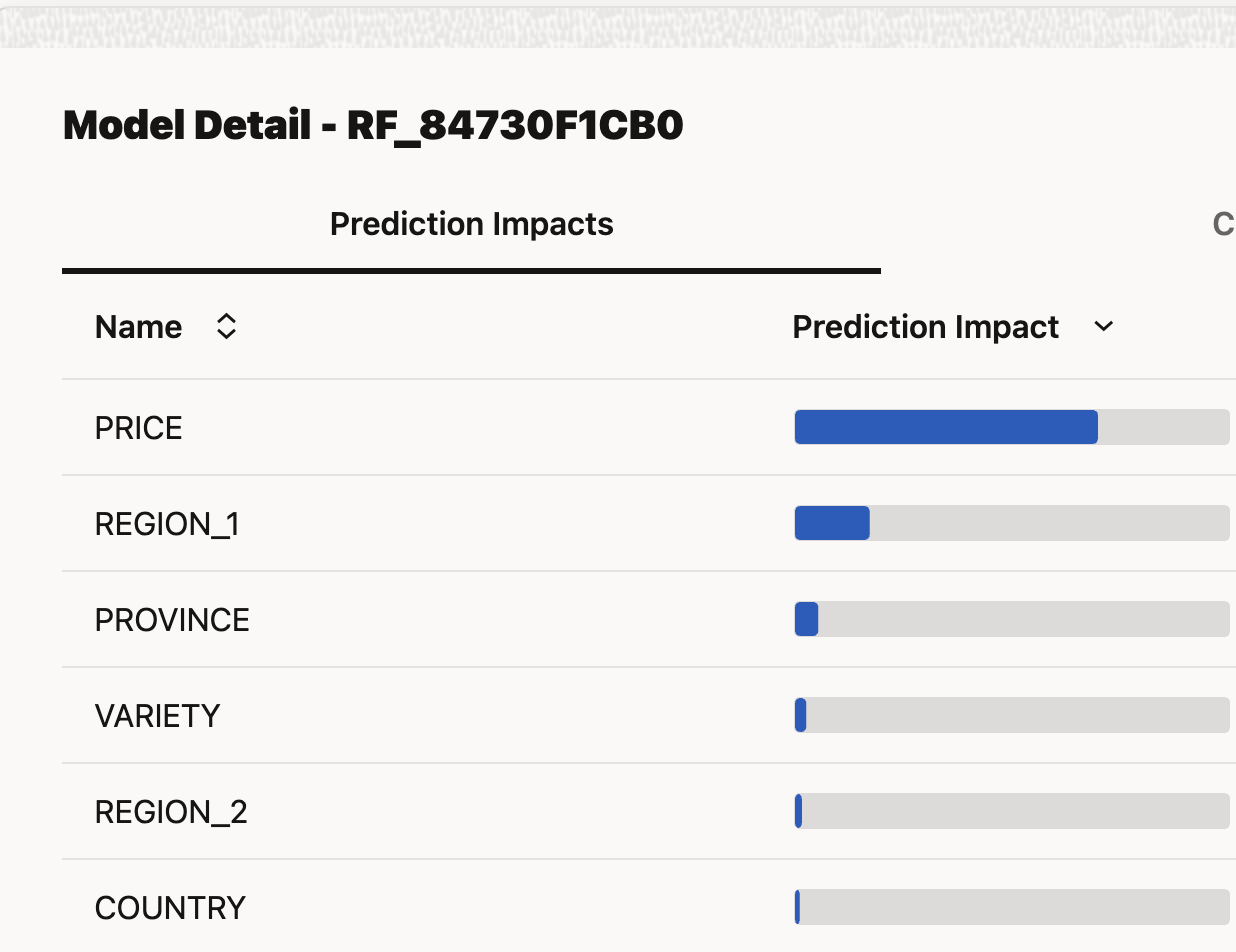
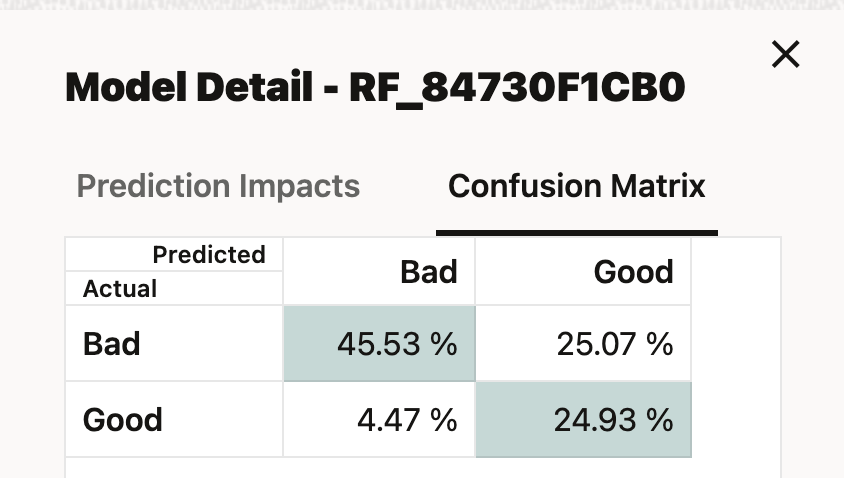
A confusion matrix is a summary of how the "predicted" values measure up against the "actual" values of your data. It allows you to easily visualise the number of correct and incorrect predictions, broken down by the class values (here, Good and Bad). The matrix shows you whether the model is "confusing" the two classes.
When a wine was ranked Bad in our training data, our model predicted 45.5% to be Bad and (wrongly) 25.5% to be Good
When a wine was ranked Good in our training data, our model predicted (wrongly) 4.5% to be Bad and 24.9% to be Good
AutoML Algorithms
Depending on if we are doing a Classification (binary or multi-class) or Regression experiment, we have a slightly different set of ML algorithms to choose from. We won't go in to details of each of these here, but below is the list of currently supported algorithms.
- Classification
Decision Tree
Generalized Linear Model
Generalized Linear Model (Ridge Regression)
Neural Network
Random Forest
Support Vector Machine (Linear)
Support Vector Machine (Gaussian) - Regression
Generalized Linear Model
Generalized Linear Model (Ridge Regression)
Neural Network
Support Vector Machine (Gaussian)
Support Vector Machine (Linear)
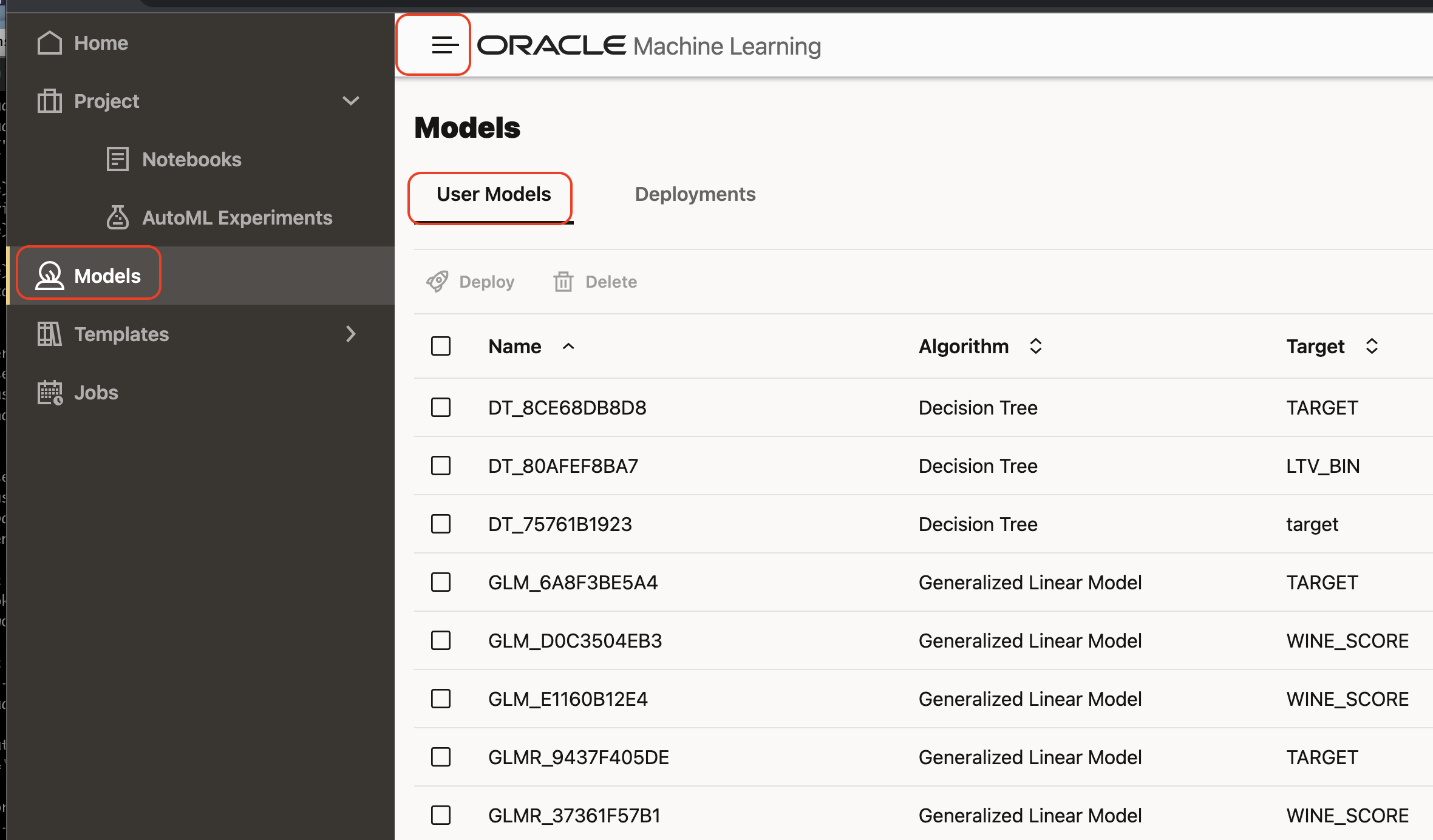
Models
Every AutoML experiment run will save each trained model in to the ADW model catalog. These are represented as tables and views in your database schema and can be loaded in to any other Python or R notebooks and projects, using the ADS package.
We can review our models under the Models tab (duh!) in the AutoML UI.
Notebooks
The AutoML UI lets us quickly get started on fine-tuning each model generated during the experiment. Simply select the model, and select Create Notebook. The new notebook will be saved in your OML Project, and can be edited to further develop the model.
Deployments
The AutoML UI also provides a quick and easy way to expose the model as a REST endpoint. Simply select the model and click on Deploy. This will create a RESTful endpoint, accessible from the ADW ORDS interface.
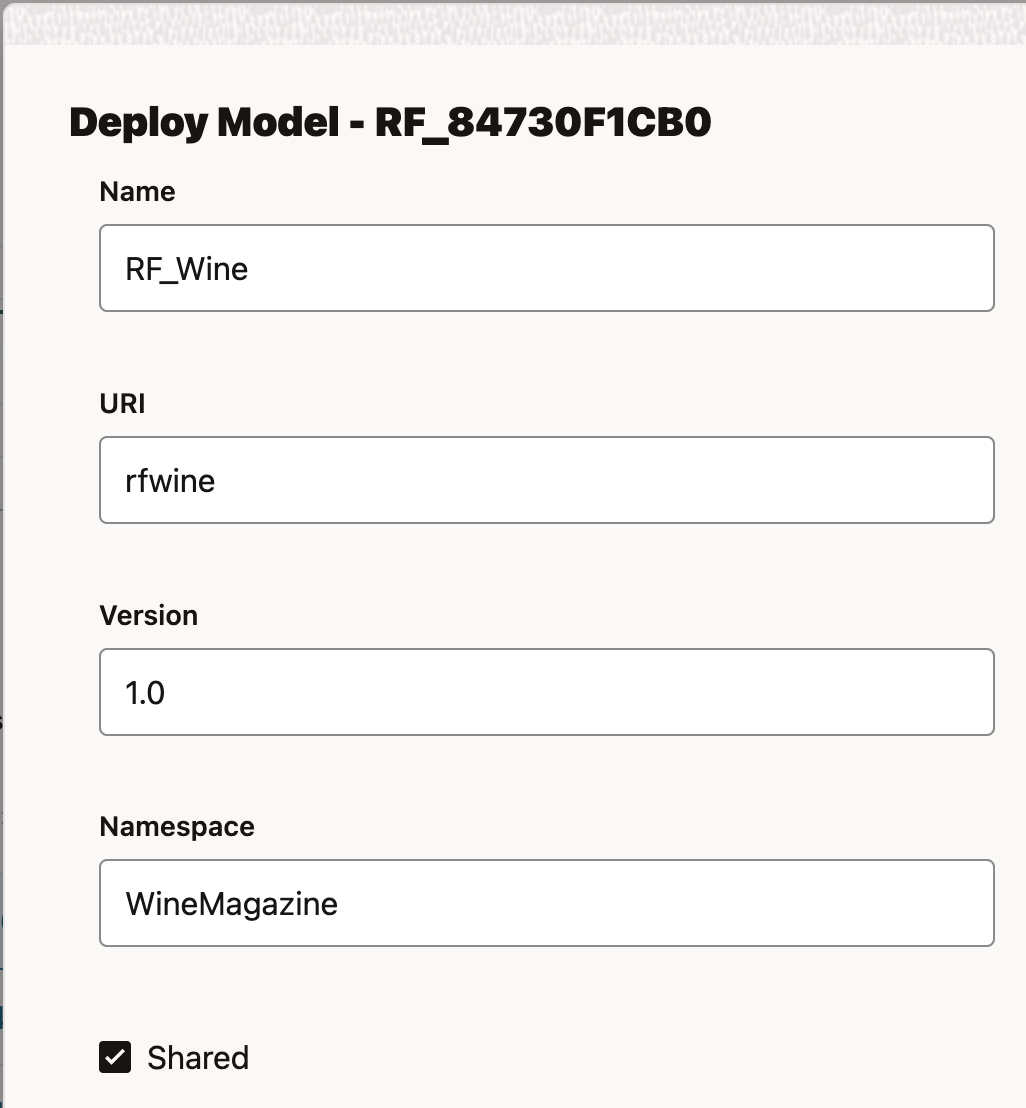
Provide a name, version, and URI. Enable the model deployment by ticking 'Shared'.
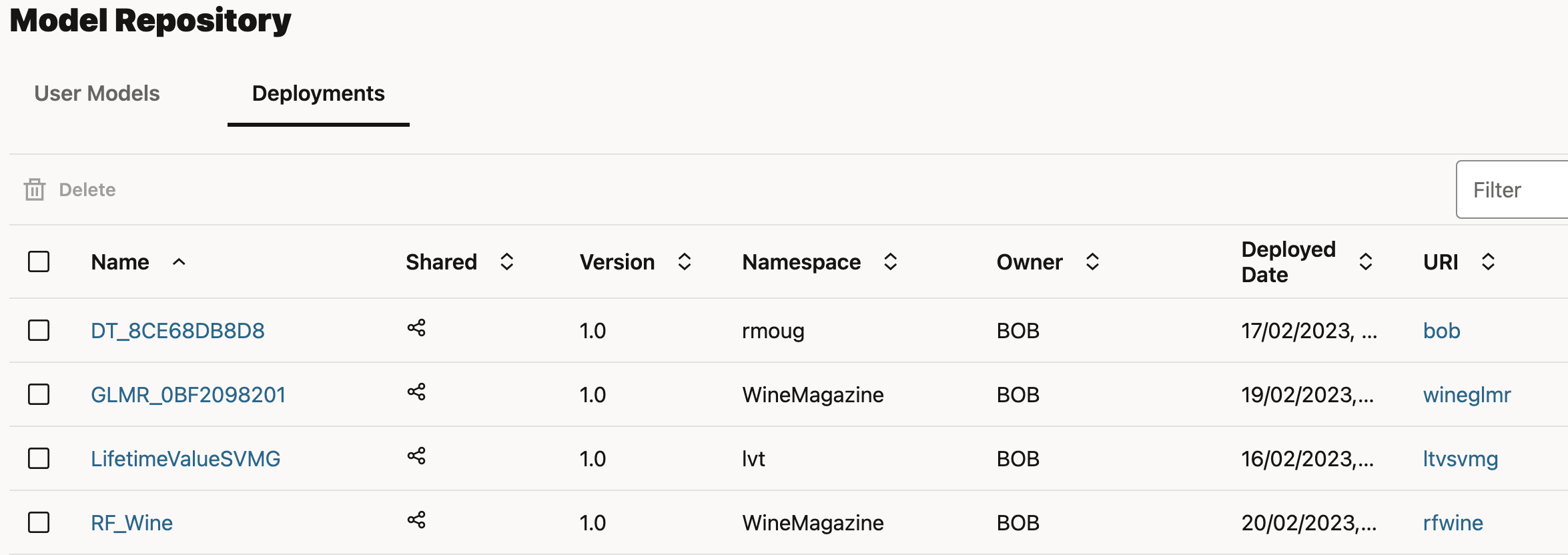
The Model Deployments can be viewed under the Model -> Deployments tab.
We can now test and run some simple Postman or bash cURL calls to invoke the model! Below is a simple shell script, call_AutoML.sh that allows you to invoke webservice from an exposed endpoint.
#omlserver=https://adw-oml.adb.uk-london-1.oraclecloudapps.com
#omluser=BOB
#omlpassword=MyVoiceIsMyPassp0rt
omlendpoint=${1}
# get bearer token
omltoken=$(curl -s -X POST --header 'Content-Type: application/json' --header 'Accept: application/json' \
-d '{"grant_type":"password", "username":"'${omluser}'", "password":"'${omlpassword}'"}' "${omlserver}/omlusers/api/oauth2/v1/token" \
| jq -r '.accessToken')
# List endpoint attributes. Comment in line below to view the endpoint
#curl -s -X GET "${omlserver}/omlmod/v1/deployment/${omlendpoint}" --header "Authorization: Bearer ${omltoken}" | jq
#Create a payload
DATA=${2}
# Score the payload and print output
curl -s -X POST "${omlserver}/omlmod/v1/deployment/${omlendpoint}/score" \
--header "Authorization: Bearer ${omltoken}" \
--header 'Content-Type: application/json' \
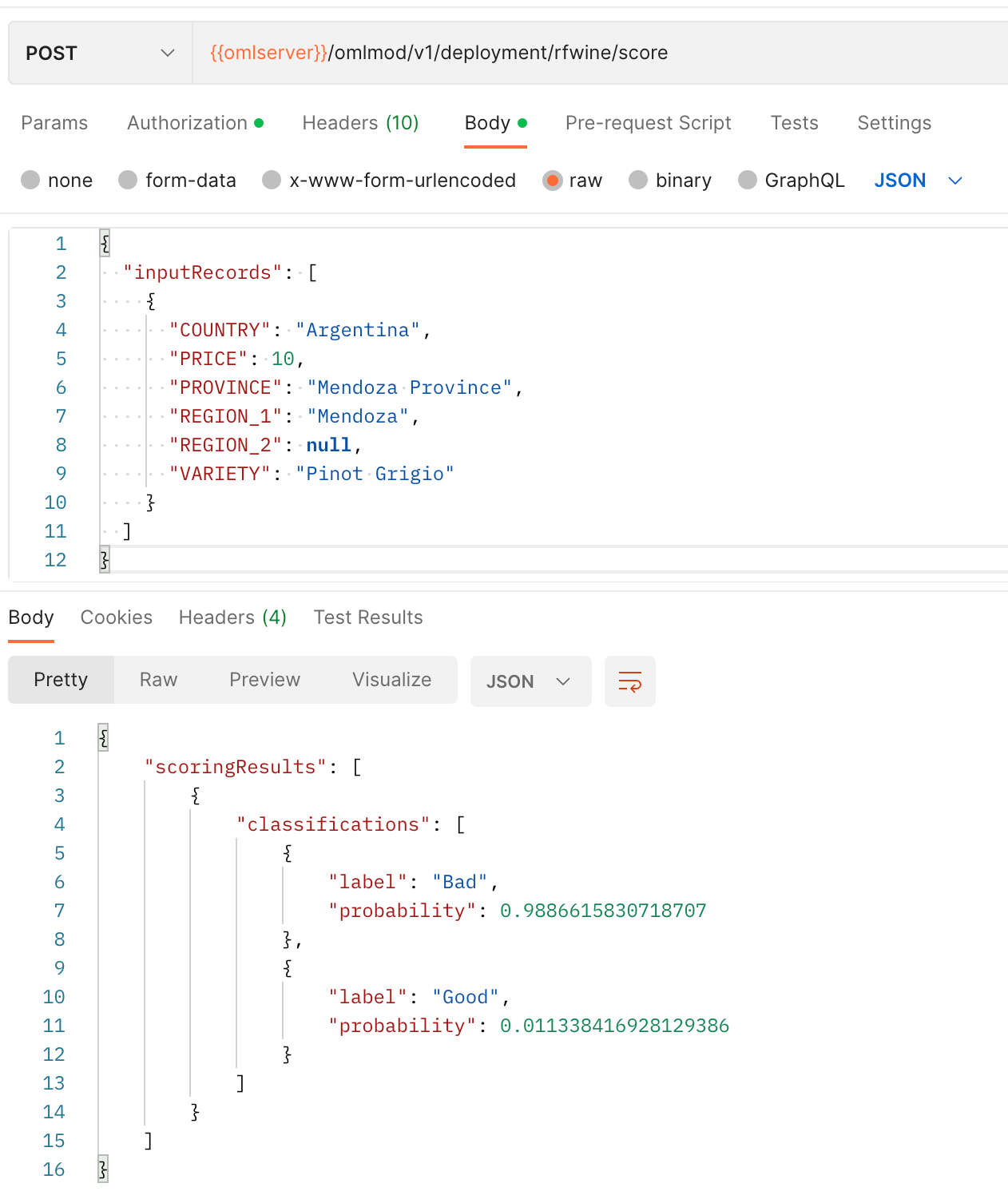
-d @${DATA} | jqLet's create a sample payload to score, single.json . This payload should include the 6 columns that AutoML had picked as the important features for this model.
{
"inputRecords": [
{
"PRICE": 10,
"REGION_1": "Mendoza",
"PROVINCE": "Mendoza Province",
"VARIETY": "Pinot Grigio",
"REGION_2": null,
"COUNTRY": "Argentina"
}
]
}You can now run the scoring against our json, and see that the wine gets 99% chance of being bad and 1% chance of being good.
./call_AutoML.sh rfwine single.json
{
"scoringResults": [
{
"classifications": [
{
"label": "Bad",
"probability": 0.9886615830718707
},
{
"label": "Good",
"probability": 0.011338416928129386
}
]
}
]
}And same in Postman:
Conclusion
In summary, Oracle AutoML provides a user-friendly, automated solution to building and deploying machine learning models, allowing organisations to benefit from the power of machine learning without requiring advanced data science skills. These models can be deployed and exposed as a webservice, at the click of a button.