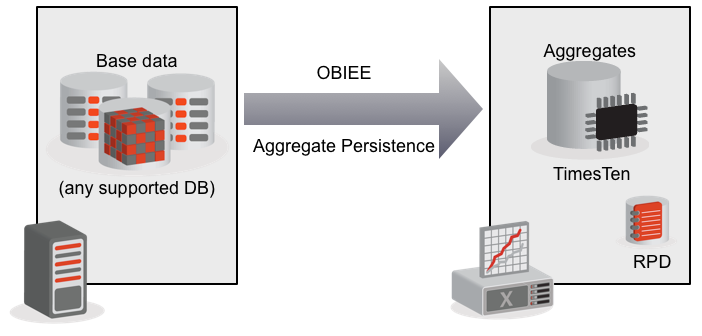
Incremental refresh of Exalytics aggregates using native BI Server capabilities

One of the key design features of the Exalytics In-Memory Machine is the use of aggregates (pre-calculated summary data), held in the TimesTen In-Memory database. Out of the box (“OotB”) these aggregates are built through the OBIEE tool, and when the underlying data changes they must be rebuilt from scratch.
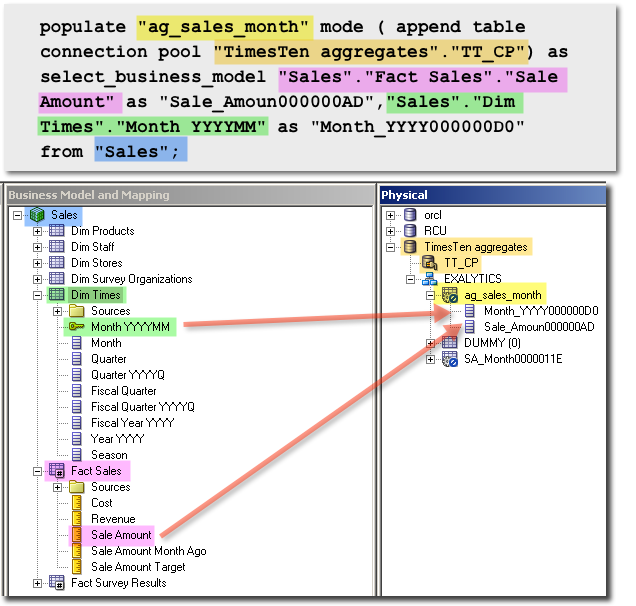
For OBIEE (Exalytics or not) to make use of aggregate tables in a manner invisible to the user, they must be mapped into the RPD as additional Logical Table Sources for the respective Logical Table in the Business Model and Mapping (BMM) layer. OBIEE will then choose the Logical Table Source that it thinks will give the fastest response time for a query, based on the dimension level at which the query is written.
OBIEE’s capability to load aggregates is provided by the Aggregate Persistence function, scripts for which are generated by the Exalytics Summary Advisor, or the standard tool’s Aggregate Persistence Wizard. The scripts can also be written by hand.
- It uses the existing metadata model of the RPD to understand where to get the source data for the aggregate from, and how to aggregate it. Because it uses standard RPD metadata, it also means that any data source that is valid for reporting against in OBIEE can be used as a source for the aggregates, and OBIEE will generate the extract SQL automagically. The aggregate creation process becomes source-agnostic. OBIEE will also handle any federation required in creating the aggregates. For example, if there are two source systems (such as Sales, and Stock) but one target aggregate, OBIEE will manage the federation of the aggregated data, just as it would in any query through the front-end.
- All of the required RPD work for mapping the aggregate as a new Logical Table Source is done automagically. There is no work on the RPD required by the developer.
- It cannot do incremental refresh of aggregates. Whenever the underlying data changes, the aggregate must be dropped and rebuilt in entirety. This can be extremely inefficient if only a small proportion of the source data has changed, and can ultimately lead to scalability and batch SLA issues.
- Each time that the aggregate is updated, the RPD is modified online. This can mean that batch times take longer than they need to, and is also undesirable in a Production environment.
- Loading TimesTen aggregates through bespoke ETL, in tools such as GoldenGate and ODI. TimesTen supports a variety of interfaces - including ODBC and JDBC - and therefore can be loaded by any standard ETL tool. A tool such as GoldenGate can be a good way of implementing a light-touch CDC solution against a source database.
- Loading TimesTen aggregates directly using TimesTen’s Load from Oracle functionality, taking advantage of Aggregate Persistence to do the aggregate mapping work in the RPD
Refreshing aggregates using native OBIEE functionality alone
Here I present another alternative method for refreshing Exalytics aggregates, but using OBIEE functionality alone and remaining close to the OotB method. It is based on Aggregate Persistence but varies in two significant ways :- Incremental refresh of the aggregate is possible
- No changes are made to the RPD when the aggregate is refreshed
- BI Server uses (dare I say, leverages), your existing metadata modelling work which is necessary - regardless of your aggregates - for users to report from the unaggregated data.
- BI Server generates your aggregate refresh ETL code
- If your source systems change, your aggregate refresh code doesn’t need to - just as reports are decoupled from the source system through the RPD metadata layers, so are your target aggregates
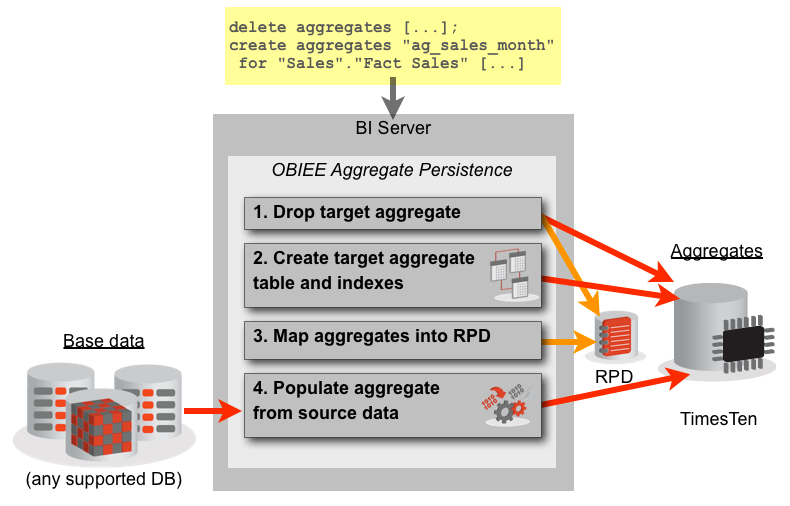
Background, part 1 : Aggregate Persistence - under the covers
When Aggregate Persistence runs, it does several things:- Remove aggregates from physical database and RPD mappings
- Create the physical aggregate tables and indexes on the target database, for the fact aggregate and supporting dimensions
- Update the RPD Physical and Logical (BMM) layers to include the newly built aggregates
- Populate the aggregate tables, from source via the BI Server to the aggregate target (TimesTen)
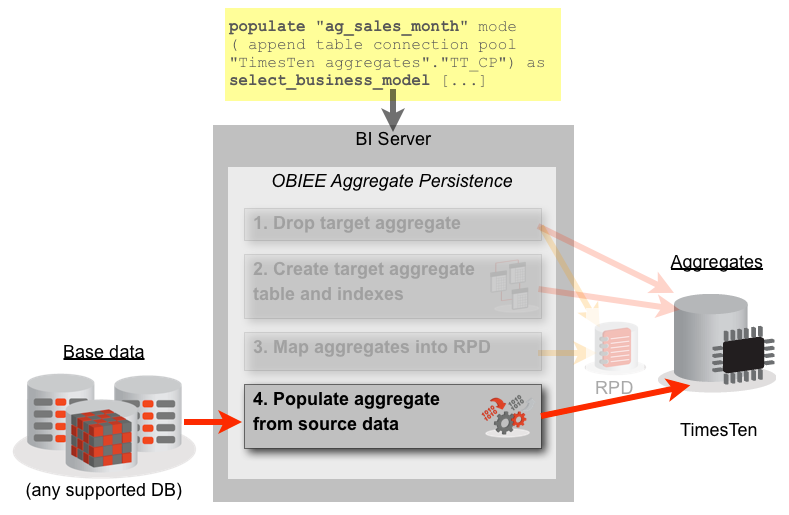
The command to tell the BI Server to do this is the populate command, which can be found from close inspection of the nqquery.log during execution of normal Aggregate Persistence:
populate "ag_sales_month" mode ( append table connection pool "TimesTen aggregates"."TT_CP") as
select_business_model "Sales"."Fact Sales"."Sale Amount" as "Sale_Amoun000000AD","Sales"."Dim Times"."Month YYYYMM" as "Month_YYYY000000D0"
from "Sales";
This populate <table> command can be sent by us directly to the BI Server (exactly in the way that a standard create aggregate Aggregate Persistence script would be - with nqcmd etc) and causes it to load the specified table (using the specified connection pool) using the logical SQL given. The re-creation of the aggregate tables, and the RPD mapping, doesn't get run:
nqquery.log file it follows this pattern:

nqcmd, or just by extracting it from the nqquery.log.
Background, part 2 : Secret Sauce - INACTIVE_SCHEMAS
So, we have seen how we can take advantage of Aggregate Persistence to tell the BI Server to load an aggregate, from any source we’ve modelled in the RPD, without requiring it to delete the aggregate to start with or modify the RPD in any way.Now, we need the a bit of secret sauce to complete the picture and make this method a viable one.
In side-stepping the full Aggregate Persistence sequence, we have one problem. The Logical SQL that we use in the populate statement is going to be parsed by the BI Server to generate the select statement(s) against the source database. However, the BI Server uses its standard query parsing on it, using the metadata defined. Because the aggregates we are loading are already mapped into the RPD then by default the BI Server will probably try to use the aggregate to satisfy the aggregate populate request (because it will judge it the most efficient LTS) – thus loading data straight from the table that we are trying to populate!
The answer is the magical INACTIVE_SCHEMAS variable. What this does it tell OBIEE to ignore one or more Physical schemas in the RPD, and importantly, any associated Logical Table Sources. INACTIVE_SCHEMAS is documented as part of the Double Buffering. It can be used in any logical SQL statement, so is easily demonstrated in an analysis (using Advanced SQL Clauses -> Prefix):
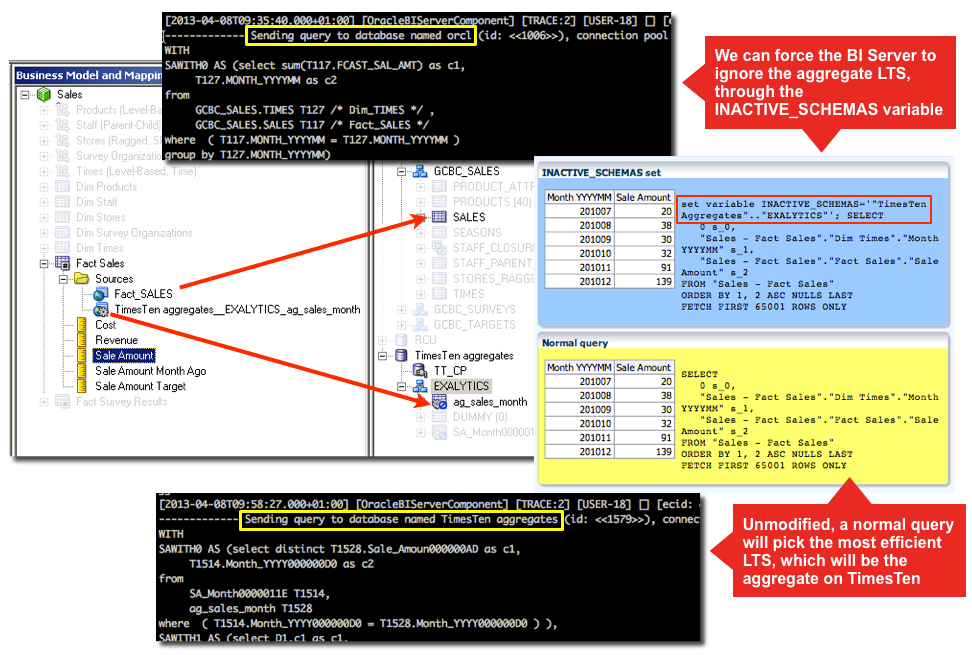
So when we specify the populate command to update the aggregate, we just include the necessary INACTIVE_SCHEMAS prefix:
SET VARIABLE INACTIVE_SCHEMAS='"TimesTen Aggregates".."EXALYTICS"':
populate "ag_sales_month" mode ( append table connection pool
"TimesTen aggregates"."TT_CP") as
select_business_model "Sales"."Fact Sales"."Sale Amount" as "Sale_Amoun000000AD","Sales"."Dim Times"."Month YYYYMM" as "Month_YYYY000000D0"
from "Sales";
The final part of the puzzle - Incremental refresh
So, we have a way of telling BI Server to populate a target aggregate without rebuilding it, and we have the workaround necessary to stop it trying to populate the aggregate from itself. The last bit is making sure that we only load the data we want to. If we execute the populate statement as it stands straight from thenqquery.log of the initial Aggregate Persistence run then we will end up with duplicate data in the target aggregate. So we need to do one of the following :
- Truncate the table contents before the
populate - Use a predicate in the
populateLogical SQL so that only selected data gets loaded
execute physical to get the BI Server to run a command against the target database, for example:
execute physical connection pool "TimesTen Aggregates"."TT_CP" truncate table ag_sales_month
select_business_model "Sales"."Fact Sales"."Sale Amount" as "Sale_Amoun000000AD","Sales"."Dim Times"."Month YYYYMM" as "Month_YYYY000000D0"
from "Sales"
where "Dim Times"."Month YYYYMM" = VALUEOF("THIS_MONTH")
SET VARIABLE DISABLE_CACHE_HIT=1, DISABLE_CACHE_SEED=1, DISABLE_SUMMARY_STATS_LOGGING=1,
INACTIVE_SCHEMAS='"TimesTen Aggregates".."EXALYTICS"';
populate "ag_sales_month" mode ( append table connection pool
"TimesTen aggregates"."TT_CP") as
select_business_model "Sales"."Fact Sales"."Sale Amount" as "Sale_Amoun000000AD","Sales"."Dim Times"."Month YYYYMM" as "Month_YYYY000000D0"
from "Sales"
where "Dim Times"."Month YYYYMM" = VALUEOF("THIS_MONTH");
execute physical:
execute physical connection pool "TimesTen Aggregates"."TT_CP" delete from ag_sales_month where Month_YYYY000000D0 = VALUEOF(THIS_MONTH);
Step-by-step
The method I have described above is implemented in two parts:- Initial build- only needs doing once
- Create Aggregate Persistence scripts as normal (for example, with Summary Advisor)
- Execute the Aggregate Persistence script to :
- Build the aggregate tables in TimesTen
- Map the aggregates in the RPD
- Create custom populate scripts:
- From
nqquery.log, extract the fullpopulatestatement for each aggregate (fact and associated dimensions) - Amend the INACTIVE_SCHEMAS setting into the
populatescript, specifying the target TimesTen database and schema.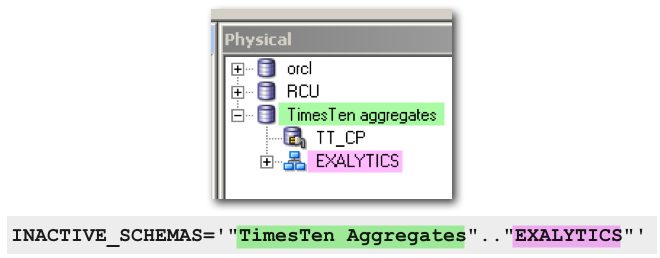
- For incremental refresh, add a
WHEREclause to thepopulatelogical SQL so that it only fetches the data that will have changed. Repository variables are useful here for holding date values such as current date, week, etc. - If necessary, build an
execute physicalscript to clear down all or part of the aggregate table. This is run prior to thepopulatescript to ensure you do not load duplicate data
- From
- Aggregate refresh - run whenever the base data changes
- Optionally, execute the
execute physicalscript to prepare the aggregate table (by deleting whatever data is about to be loaded) - Execute the custom
populatescript from above. Because the aggregates are being built directly from the base data (as enforced byINACTIVE_SCHEMAS) the refresh scripts for multiple aggregates could potentially be run in parallel (eg using xargs). A corollary of this is that this method could put additional load on the source database, because it will be hitting it for every aggregate, whereas vanilla Aggregate Persistence will build aggregates from existing lower-level aggregates if it can.
- Optionally, execute the
Summary
This method is completely valid for use outside of Exalytics too, since only the Summary Advisor is licensed separately. Aggregate Persistence itself is standard OBIEE functionality. For Exalytics deployed in an environment where aggregate definitions and requirements change rapidly then this method would be less appropriate, because of the additional work required to modify the scripts. However, for an Exalytics deployment where aggregates change less frequently, it could be very useful.The approach is not without drawbacks. Maintaining a set of custom populate commands has an overhead (although arguably no more so than a set of Aggregate Persistence scripts), and the flexibility comes at the cost of putting the onus of data validity on the developer. If an aggregate table is omitted from the refresh (for example, a support aggregate dimension table) then reports will show erroneous data.
The benefit of this approach is that aggregates can be rapidly built and maintained in a sensible manner. The RPD is modified only in the first step, the initial build. It is then left entirely untouched. This makes refreshes faster, and safer; if it fails there is just the data to tidy up, not the RPD too.