Introduction to Oracle Machine Learning on ADB


Oracle Machine Learning or OML is a collaborative user interface that enables data scientists to perform machine learning within the Oracle Autonomous Database (ADB).
OML is packaged with Oracle Autonomous Database (ADB) meaning if you already have Oracle Autonomous Data Warehouse or Oracle Autonomous Transaction Processing you could start using OML notebooks on your data straight away.
For an ADB user to access OML, an administrator needs to enable this. We have detailed the steps to do this in one of our Tuesday Tips, that can be found here.
OML has a web based interface, from which you can create workspaces, projects, and notebooks to manage your work. The notebooks are Apache Zeppelin based, and can be used for the creation of scripts, data analytics, visualisations and explorations; as well as building, evaluating, and deploying machine learning models in the ADB.
You can create private or shared templates that can be used for repeatable tasks by yourself or other OML users. OML also has the ability to schedule notebooks for repeatable tasks.
Another key tool available to you in OML is the Auto ML UI, which my colleague Borkur wrote about in this blog post. You can use these AutoML features in the notebooks directly, and there are many examples in the OML templates that detail how this can be done. You can also create a notebook from one of your AutoML experiments that would contain the code needed to recreate your models.
OML currently provides support for 4 languages: SQL, PL/SQL, Python and R. Using these languages and Oracle Advanced Analytics Machine Learning algorithms, you can implement in-database machine learning, meaning you do not need to move your data elsewhere.
OML Basics
When you sign into OML you are taken to the home page, from here you can see a range of quick links to key interfaces such as SQL Scripts, notebooks, jobs and examples; as well as a list of your recently used notebooks.
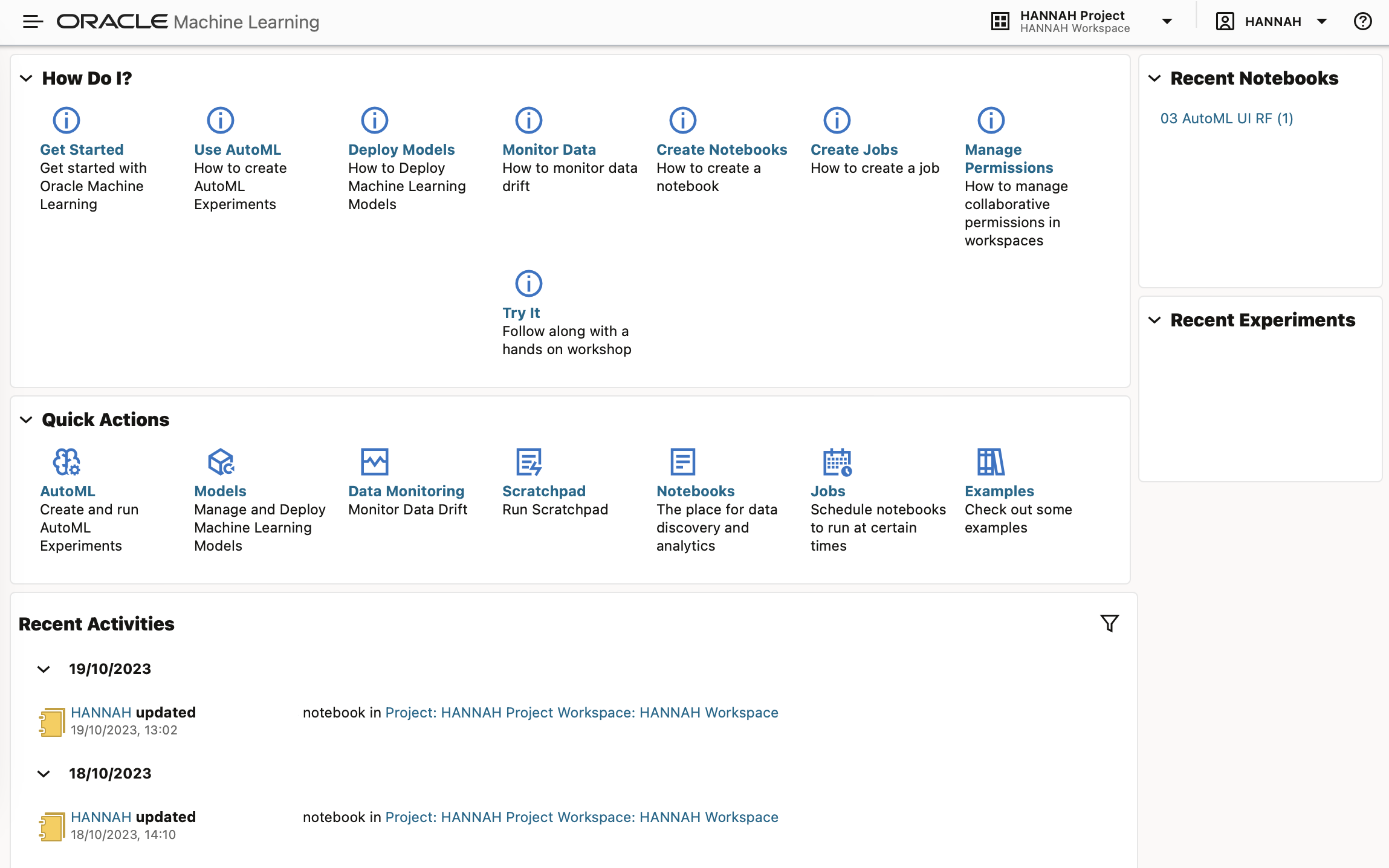
As I mentioned above, OML is structured with Workspaces, Projects, and Notebooks. Workspaces contain projects, and projects contain notebooks. A Workspace can have more than one Project within it, and a Project can have many associated Notebooks.
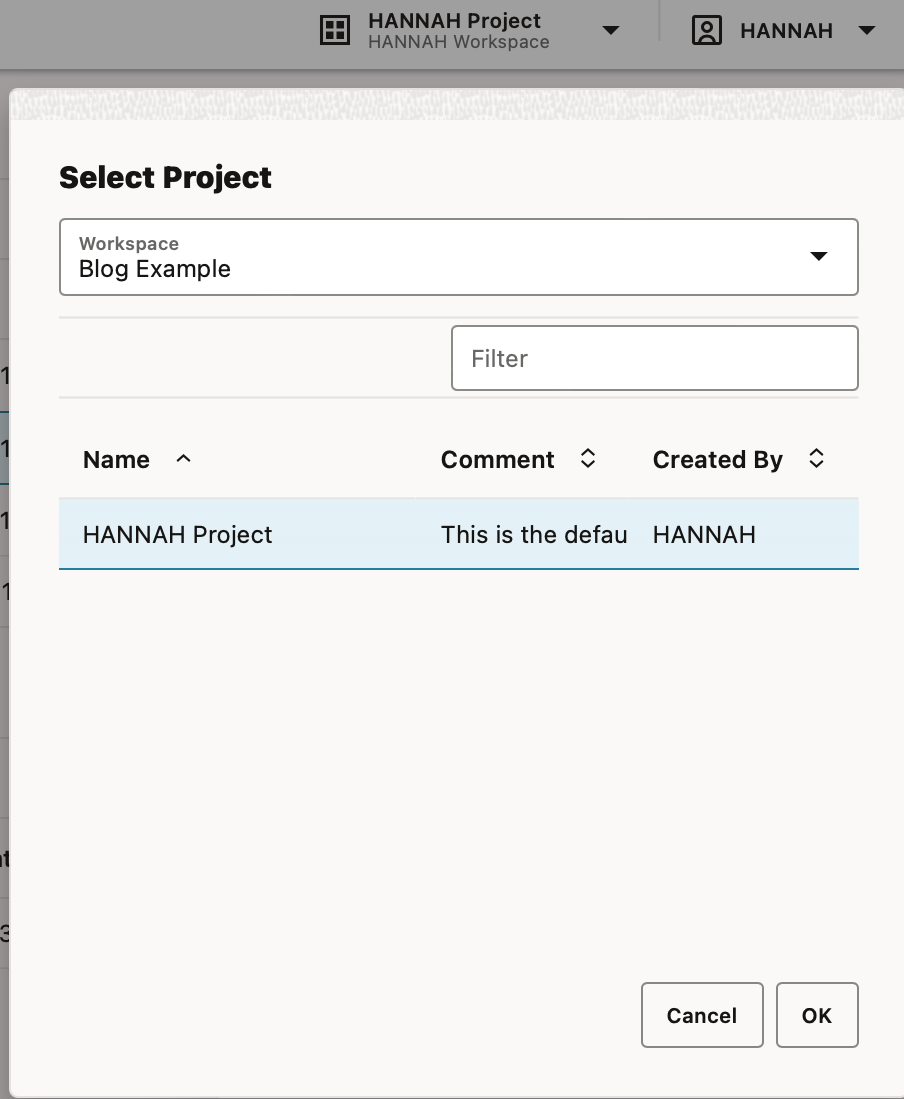
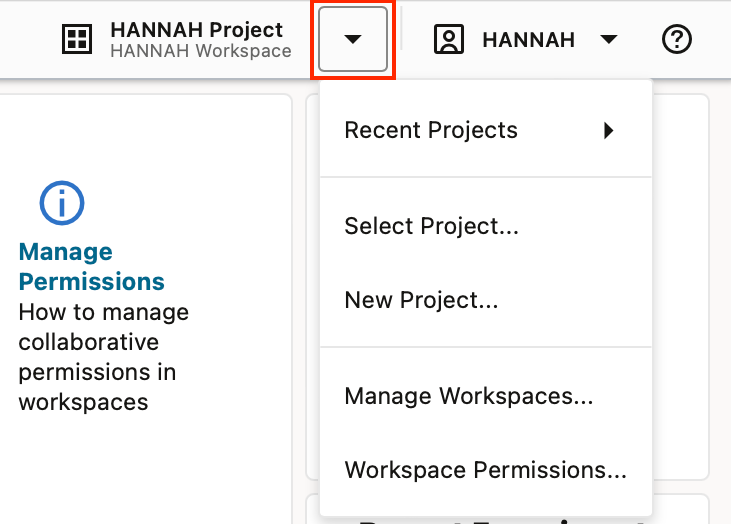
When you first log in, you are provided a default Workspace and Project, which are both created by the OML service. Whenever you are logged into OML you are associated with a Workspace and Project, if you log out and back in, these will be set automatically to those that were last used. You can easily create additional Workspaces and Projects, and switch between these in the top right hand corner of the browser page.

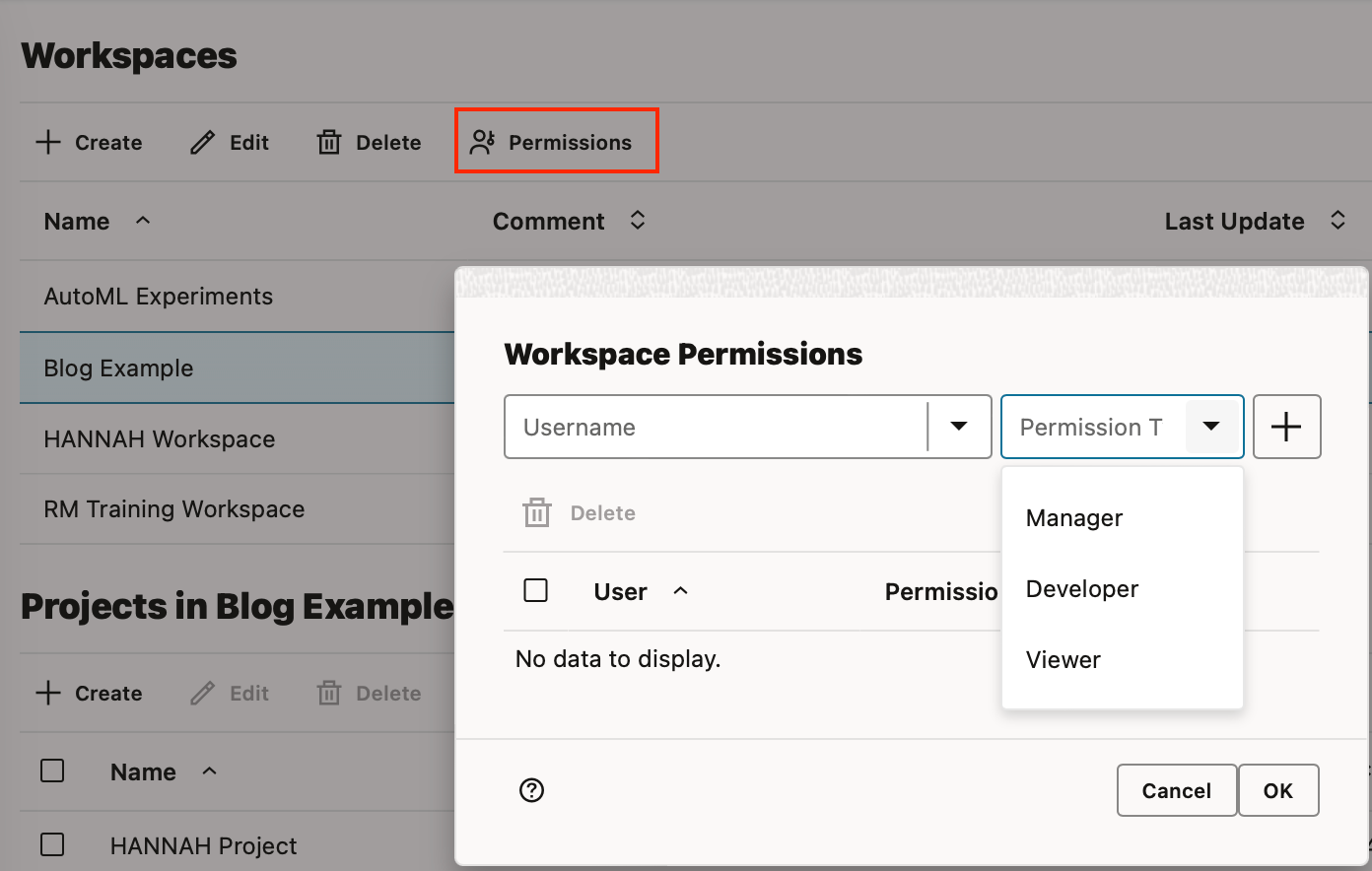
In “manage workspaces” you can create, edit, delete and change the permissions of a workspace.
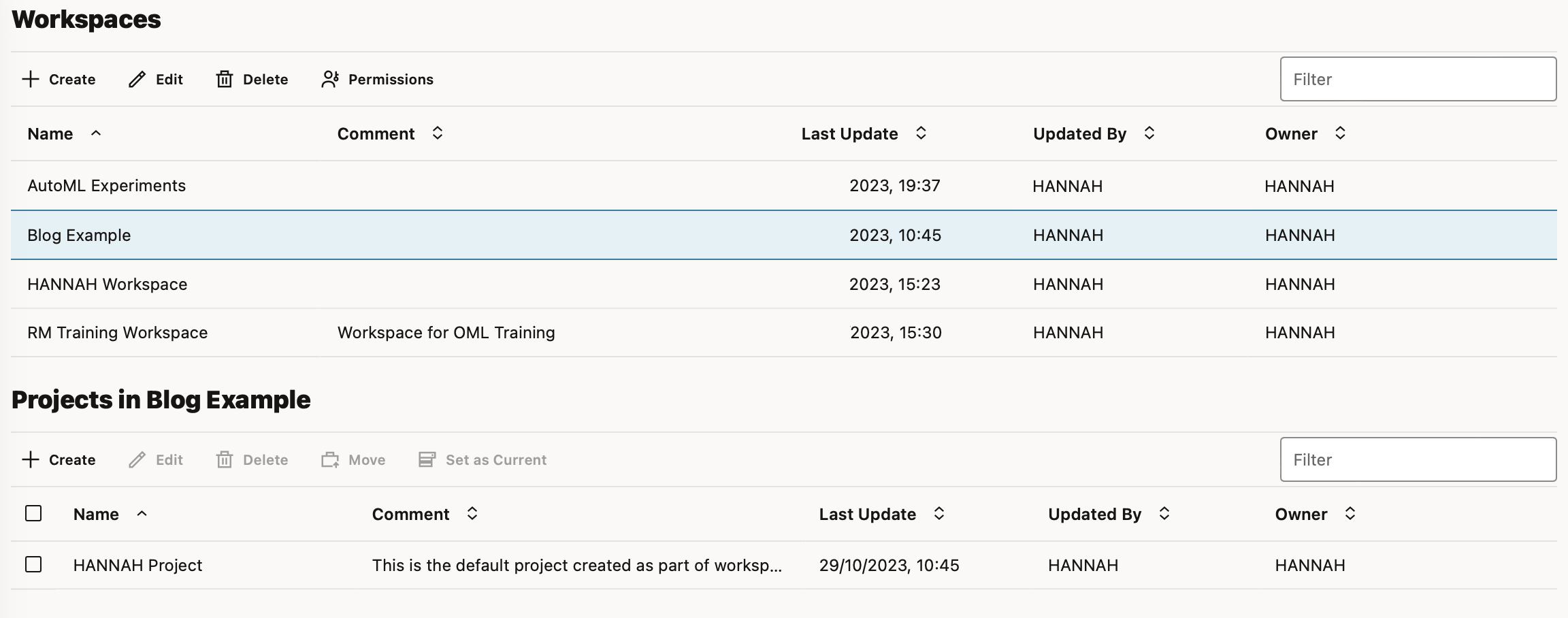
When you wish to work collaboratively with other OML users you can provide them access to an entire workspace. Available permissions include viewer, developer, or manager of the workspace.
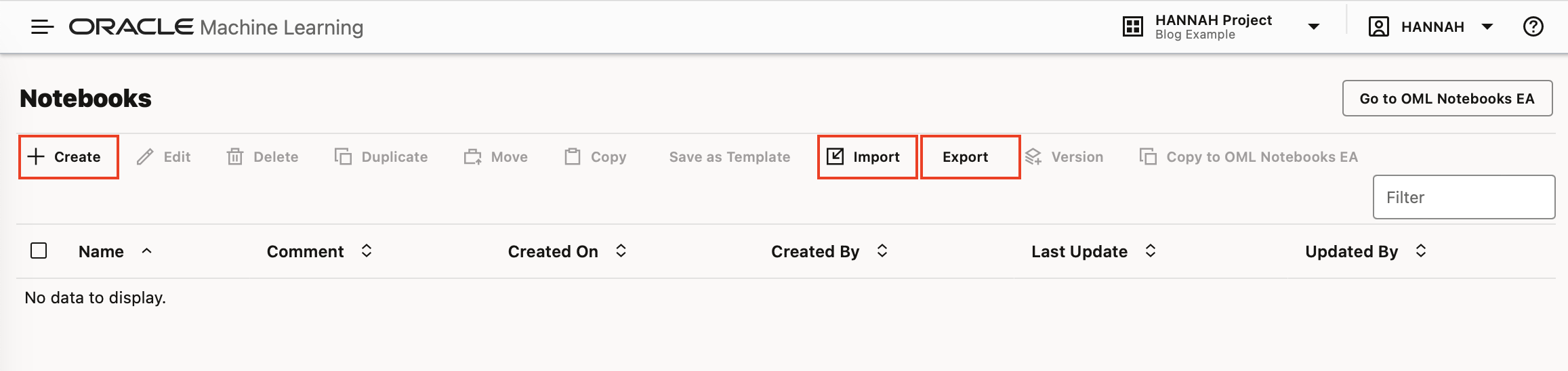
Should you wish to share a notebook with a colleague, but not an entire workspace, you can export a notebook and this can be imported into another user's, or a different workspace and project.
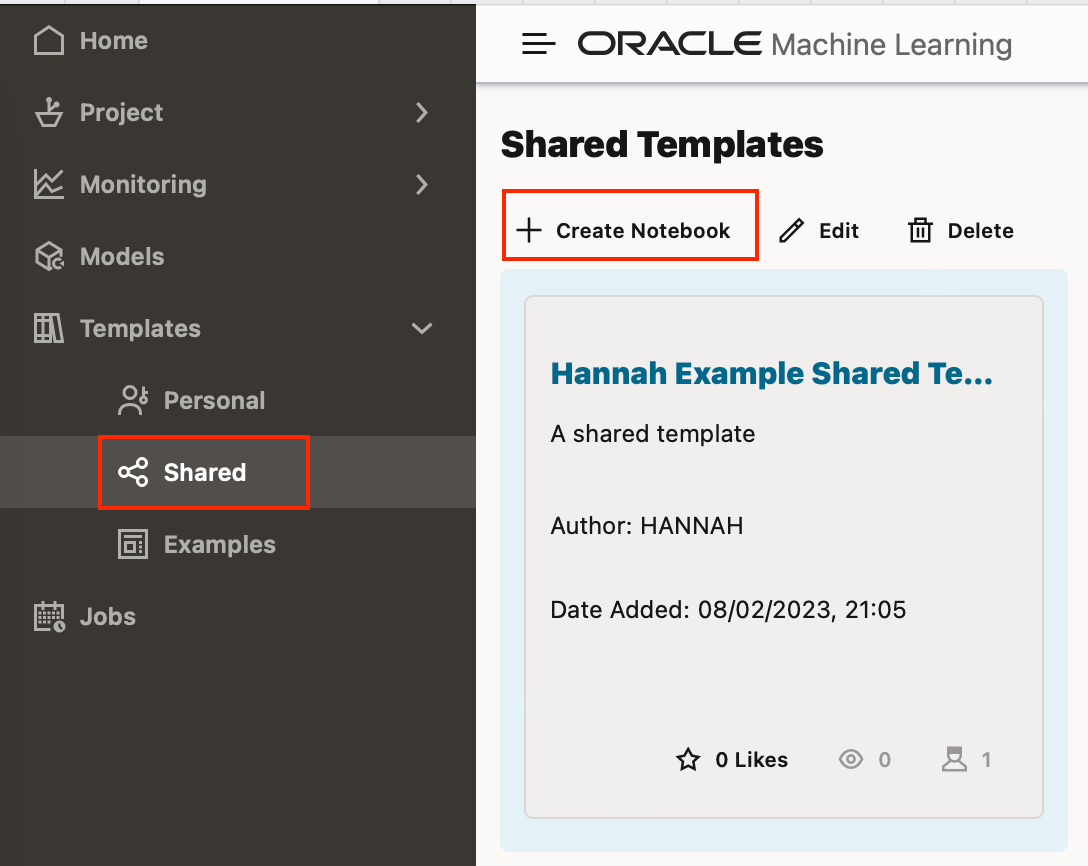
Another way to collaborate between OML users is by using Templates. You can create personal Templates for your own use, or shared Templates that can be seen by all other OML users on the ADB. These Templates are a handy way to shortcut creation of new notebooks in each user's own specified workspace and project, and also to improve consistency and commonality of approaches.
There are also many example Template notebooks to help you get started, which you can use to create new notebooks. They are pre-populated with examples covering many data wrangling and machine learning tasks in OML4Py, OML4R, SQL and PL/SQL.
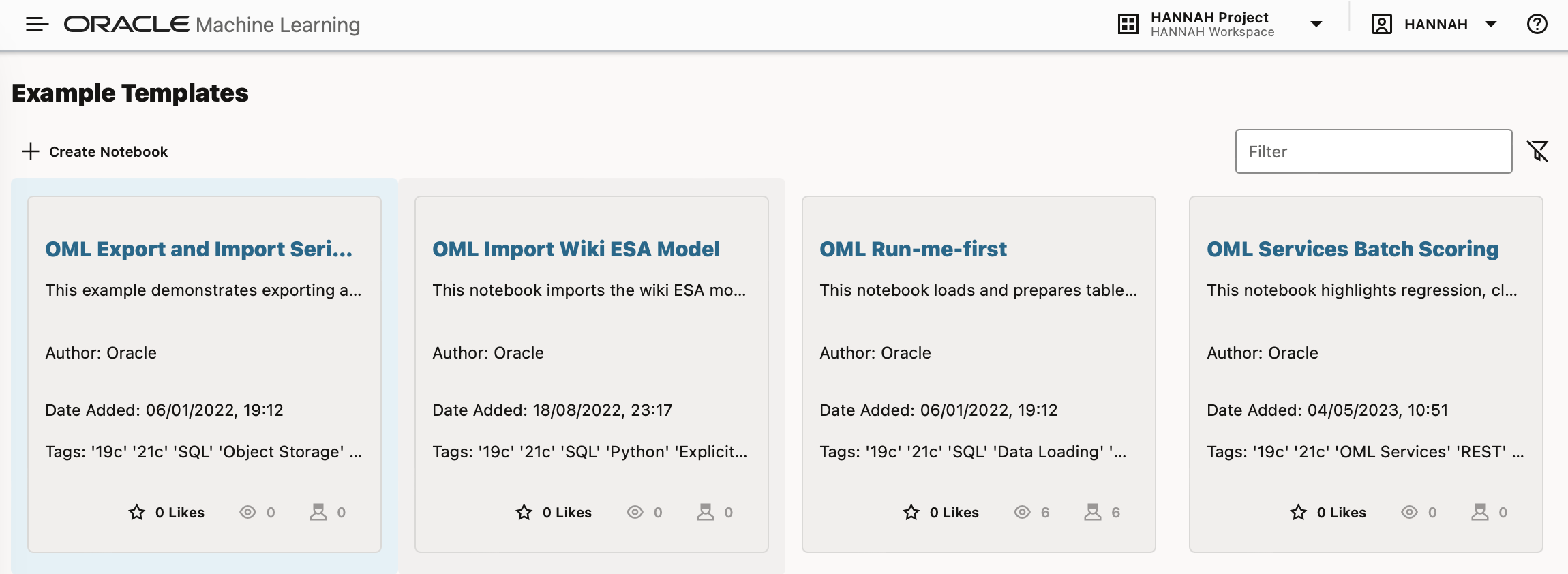
Starting or creating a notebook, either from a template, or from scratch will take a few seconds.


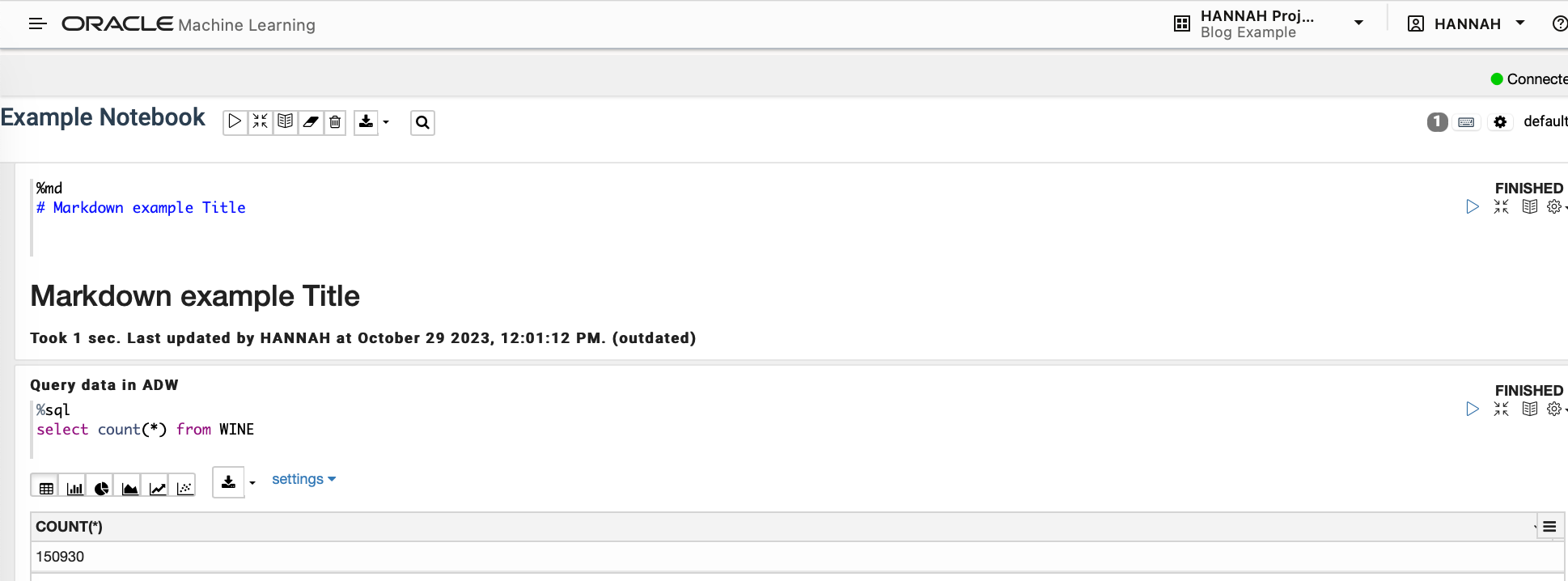
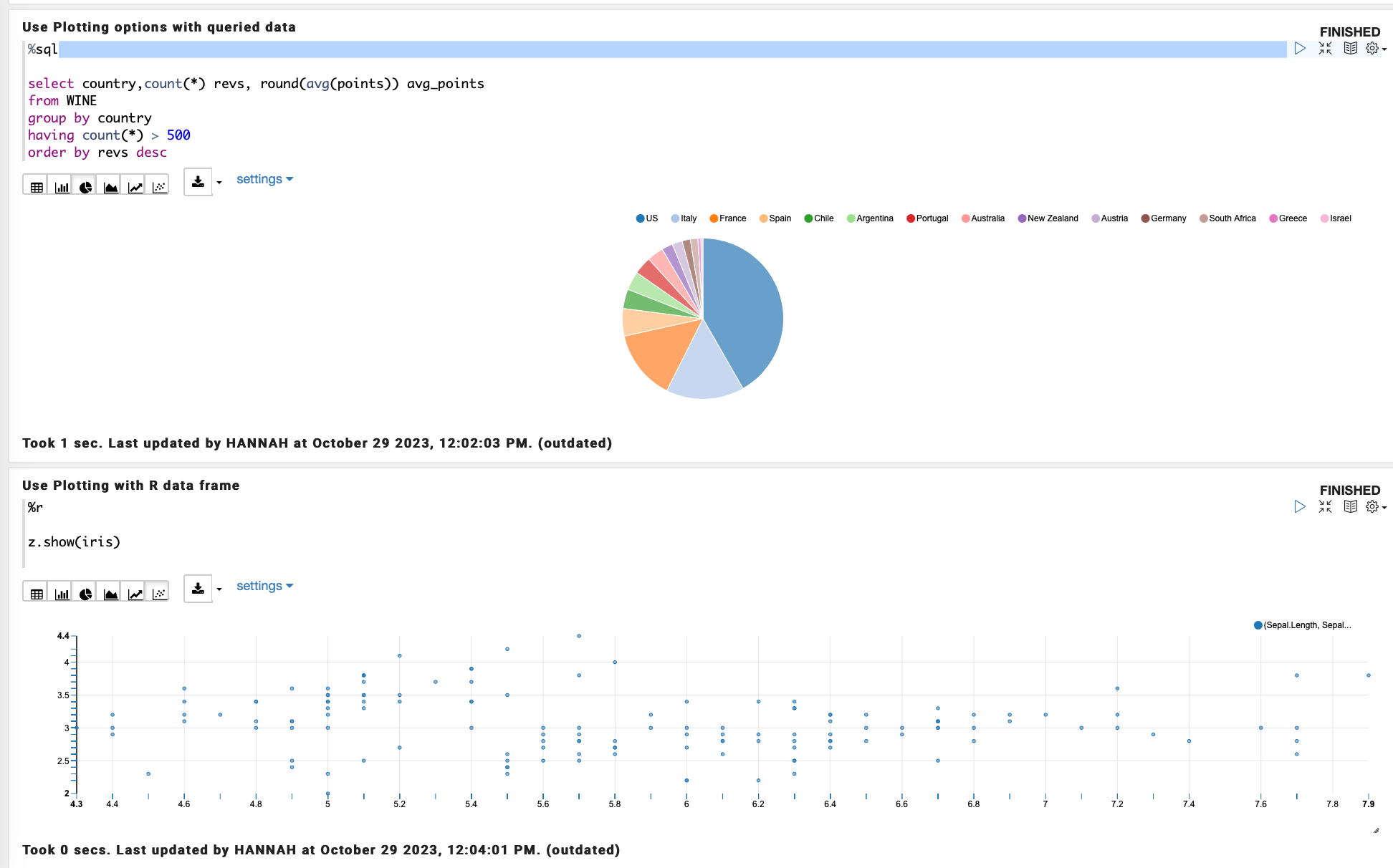
Within the notebook you can specify what kind of code you are running with %language at the top of the code block. This accepts %md for Markdown, %sql for SQL, %script for PL/SQL, %python for Python and %r for R .
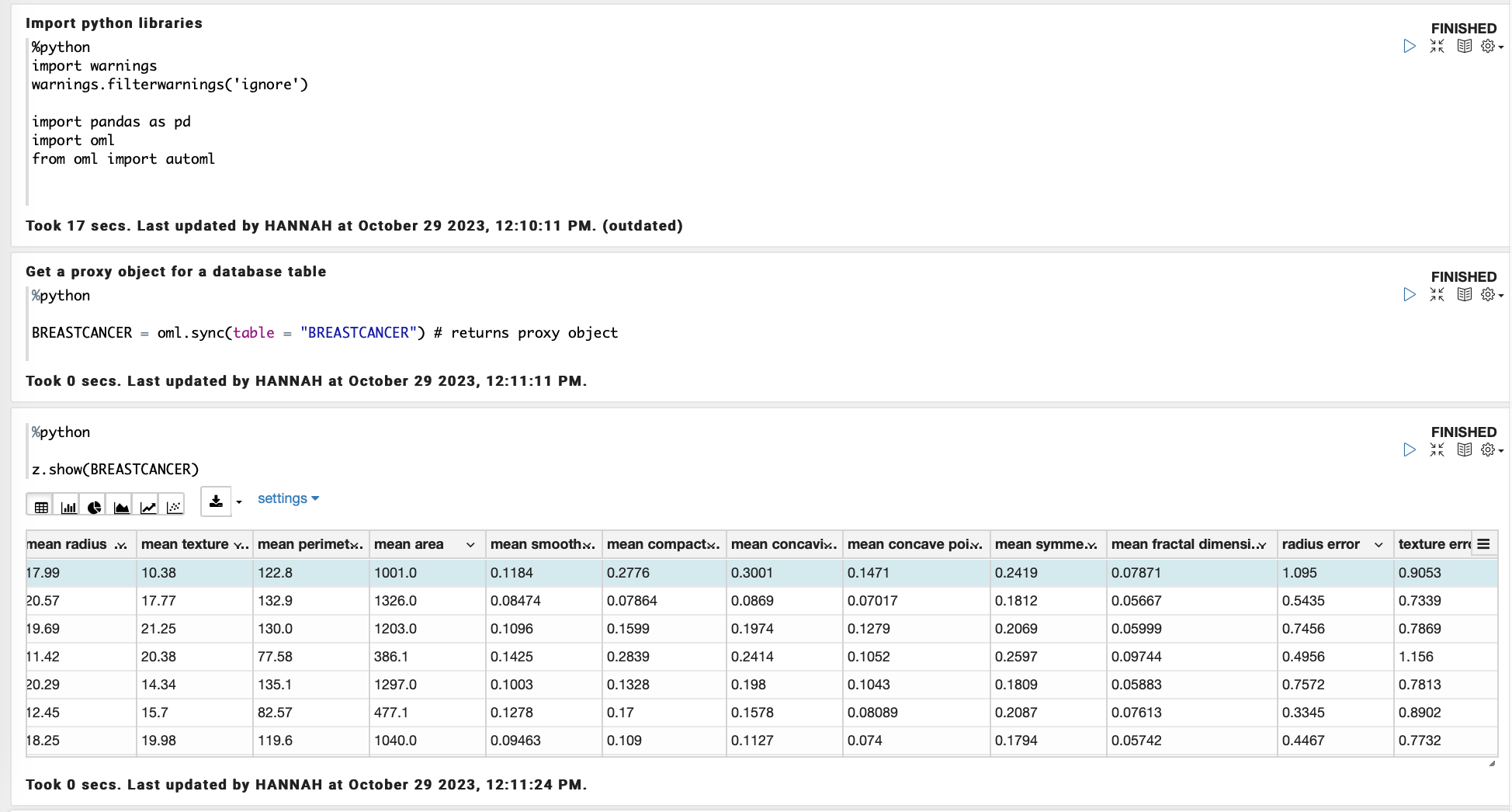
To use OML4Py, you must import the “oml” module into the notebook.
This library does quite a few different things, but in essence it is what enables OML users to run python commands on data stored in an oracle ADW. This enables you to take advantage of the parallel processing and scaleability of the autonomous data warehouse, as opposed to extracting the data and running python natively.
The library supports a whole range of other tasks too, including; data manipulation and processing, In-database machine learning, and Oracle's AutoML features.
The equivalent library for OML4R is “ORE”, which allows you to run R commands on database tables and views in an ADB, and similarly utilise Oracle's AutoML capabilities.
OML Jobs enables you to create schedules to execute notebooks. You can create, view, schedule, and manage these from the jobs tab.
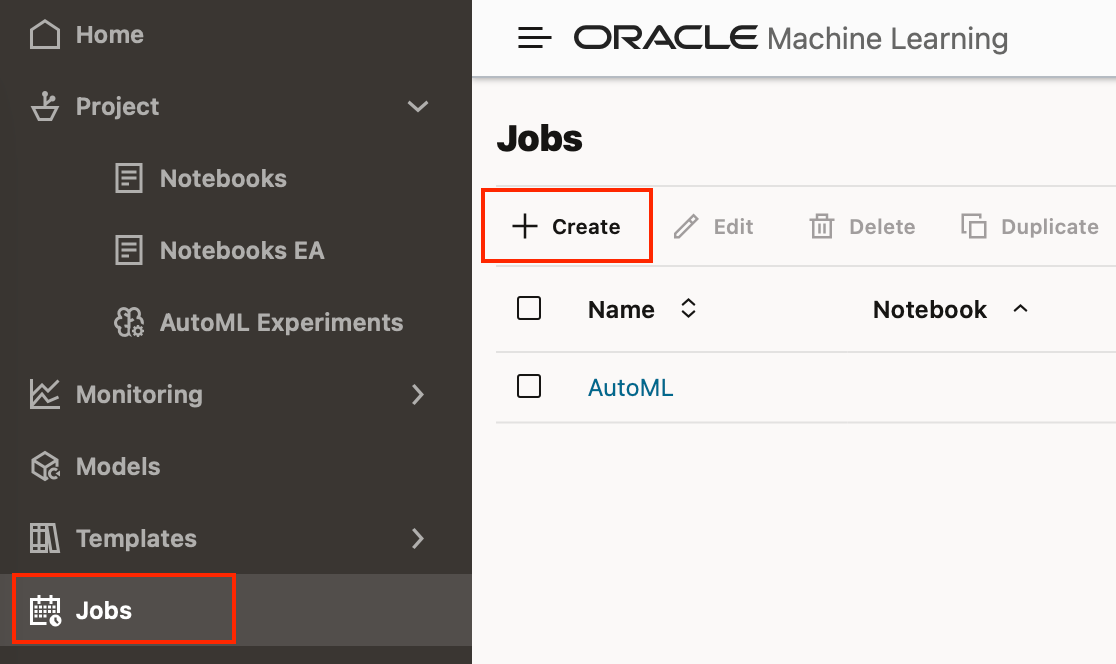
The page also provides information about Jobs created, such as the Job name, Notebook associated with the Job, owner of the Job, the last start date, the next run date of the Job, status of the Job, and the schedule.
When you create a Job you can specify Job start time, frequency of Job run time, the maximum number of runs of the Job, and the maximum failures allowed before the Job schedule is stopped.
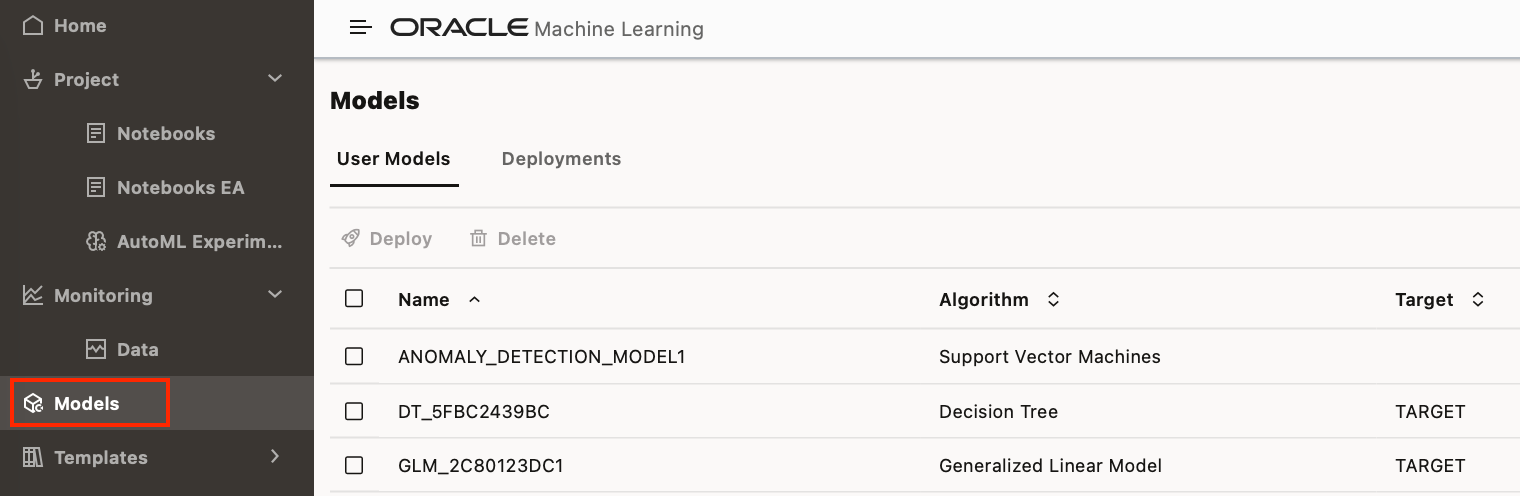
Models created either from notebooks, or from the AutoML UI will be saved to the database. Any Models that are in your user's schema can be viewed, browsed, deleted or deployed from the Models tab in OML.
Models saved to the ADW can also be registered and used in DV data flows if you want to apply them that way.
Any deployed models can be seen under “Deployments”, these are deployed to OML Services and available through a REST API. From the deployments page in OML you can view the REST API URI of the deployed model, as well as additional model metadata.
OML also has Data Monitoring to monitor how your data is changing over time and help you identify dependencies, or data drift.
Summary
I hope this blog has highlighted some of the benefits of using OML such as giving users the ability to execute In-database machine learning algorithms with familiar Python or R code; ensuring there is no need to move data from your ADB, saving time and keeping data secure.
OML helps Data Scientists to work collaboratively using Notebooks in familiar languages SQL, PL/SQL, Python or R. They can schedule Notebooks through OML Jobs, keep track of saved Models, deploy Models to OML Services, and keep track of data changes using OML Data Monitoring.
You should also be aware that from within OML in both OML4Py and OML4R OML users are limited to a set of pre-installed packages. More details of these can be found here.
Only administrators can install additional packages, which can then be accessed by non-administrator users, and loaded into their OML Notebook sessions. This might make OML Notebooks less flexible if you wish to use them as sandbox or exploratory environments.