Oracle BI EE 11g - Decoding Essbase Connectivity - Part 4 - Logical SQL Generation
In the last 3 posts we saw how BI EE generates the MDX and what major factors influence the MDX generated. As a recap, there are 4 main things that we noticed.
-
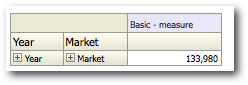
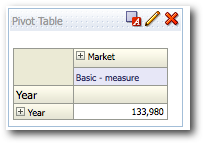
BI EE generates the most optimal MDX as long as we have all the attribute or Hierarchical columns in the Row-Edge of a Pivot.
-
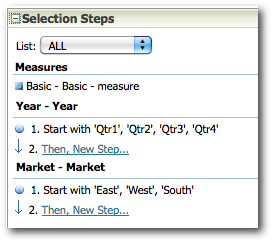
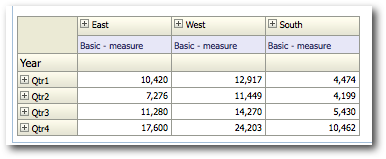
While using Selection Steps, the number of MDX generated can increase proportional to N^M where N is the number of dimensions and M is the average number of selection steps in each dimension.
-
While moving hierarchical columns to the Pivot Column edge and while drilling on the column edge, the number of MDX generated can increase quite a lot
-
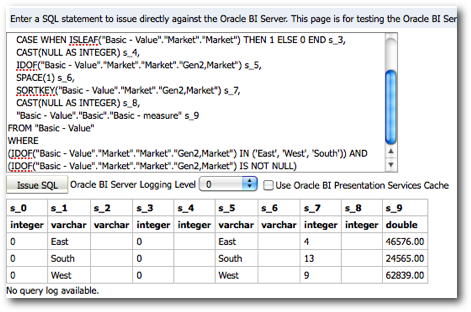
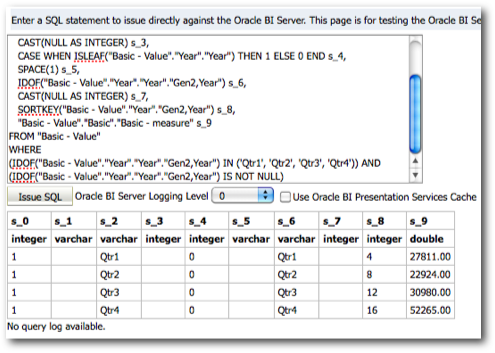
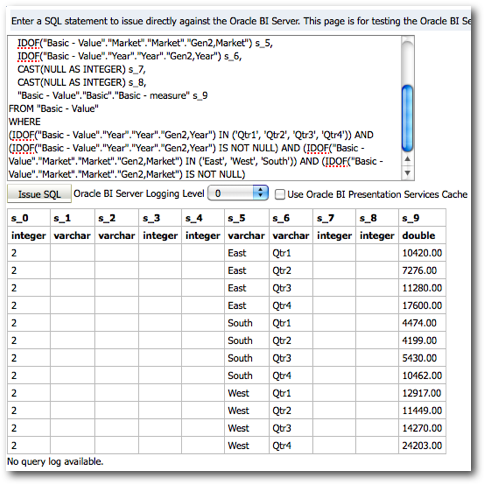
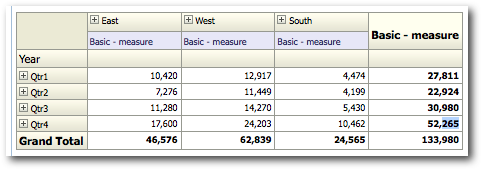
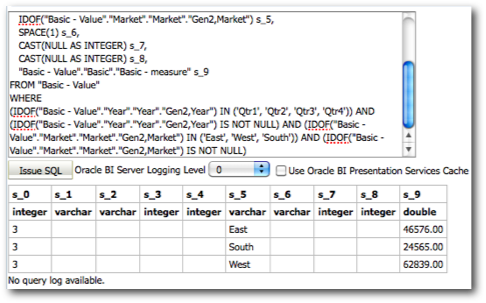
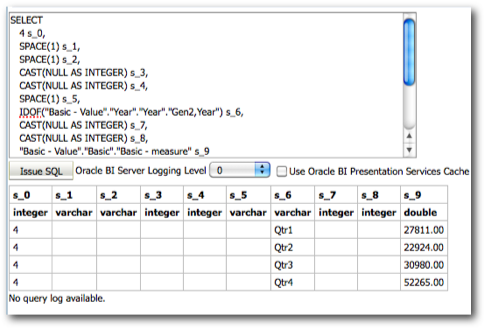
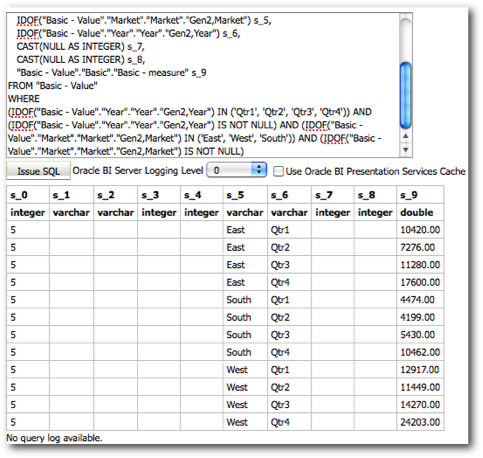
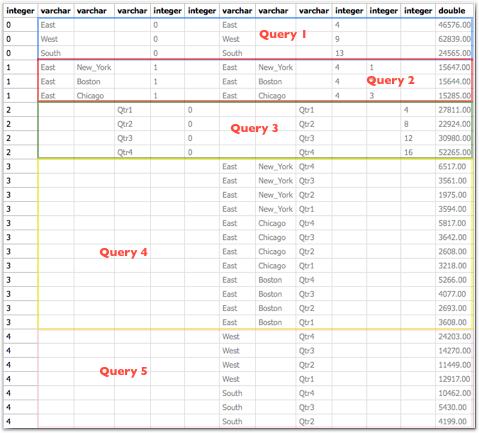
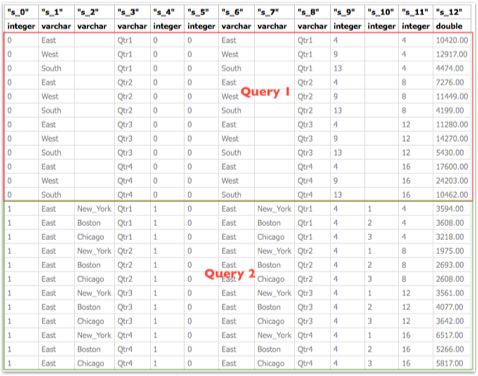
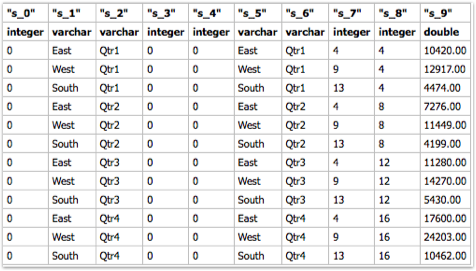
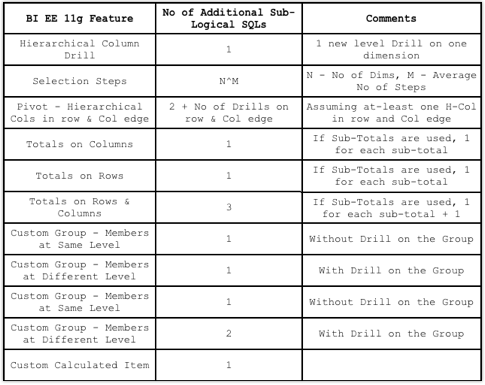
Every MDX generated will have a corresponding Sub-Logical SQL combined to the main Logical SQL through UNION ALL
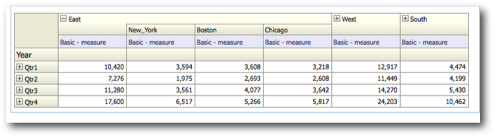
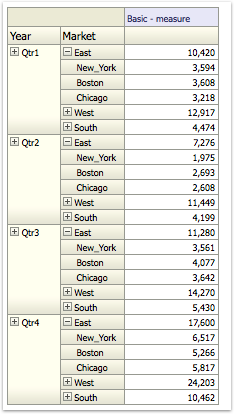
The last point above is very important as the performance of a given BI EE report going against Essbase is determined by that. We start off with decoding how and why BI EE generates so many Sub-Logical SQLs (for the same Case 2 we discussed in the last post)