Agile Data Warehousing with Exadata and OBIEE: Puzzle Pieces
In the previous post, I laid the groundwork for describing Extreme BI: a combination of Exadata and OBIEE delivered with an Agile spirit. I discussed that the usual approach to Agile data warehousing is not Agile at all due to the violation of it's main principle: working software delivered iteratively.
If you haven't already deduced from my first post -- or if you haven't already seen me speak on this topic -- what I am recommending is bypassing, either temporarily or permanently, the inhibitors specific to data warehousing projects which limit our ability to deliver working software quickly. Specifically, I'm recommending that we wait to build and populate physical star schemas until a later phase, if at all. Remember the two reasons that we build dimensional models: model simplicity and performance. With our Extreme BI solution, we have tools to counter both of those reasons. We have OBIEE 11g, with a rich metadata layer that presents our underlying data model, even if it is transactional, as a star schema to the end user. This removes our dependency on a simplistic physical model to provide a simplistic logical model to end users. We also have Exadata, which delivers world-class performance against any type of model, and can bridge the performance gap afforded by star schemas. With these tools at our disposal, we can postpone the long process of building dimensional models, at least for the first few iterations. This is the only way to get working software in front of the end user in a single iteration, and, as I will argue, this is the best way to collaborate with an end user and deliver the content they are expecting.
Of the puzzle pieces we need to deliver this model, the first is the Oracle Next-Generation Reference DW Architecture (we need an acronym for that), which Mark has already written about in-depth here. As you browse through this post, pay special attention to his formulation of the foundation layer, which is the most important layer for delivering Extreme BI.
[caption id="attachment_9672" align="aligncenter" width="663" caption="Oracle Next-Generation Reference DW Architecture"] [/caption]
[/caption]
Foundation Layer
This is our "process-neutral" layer, which means simply that it isn't imbued with requirements about what users want and how they want it. Instead, the foundation layer has one job and one job only: tracking what happened in our source systems. Typically, the foundation layer logical model looks identical to the source systems, except that we have a few additional metadata columns on each record such as commit timestamps and Oracle Database system change numbers (SCN's). There are other, more complex solutions for modeling the foundation layer when the 3NF from the source system or systems is not sufficient, such as data vault. Our foundation layer is generally "insert-only", meaning we track all history so that we are insulated from changing user requirements in the near and distant futures.UPDATE: Kent Graziano, a major data vault evangelist, has started blogging. Perhaps with some pressure from the public, we could "encourage" him to blog on what data vault would look like in a standard foundation layer.
Capturing Change
Also required for delivering Extreme BI is a process for capturing change from the source systems and rapidly applying it to the foundation layer, which I described briefly in one of my posts on real-time data warehousing. We have a bit of a tug-of-war at this point between Oracle Streams and Oracle GoldenGate. GoldenGate is the stated platform of the future because it’s a simple, flexible, powerful and resilient replication technology. However, it does not yet have powerful change data capture functionality specific to data warehouses, such as easy subscriptions to raw changed data, or support for multiple subscription groups. You can, in general, work around these limitations using the INSERTALLRECORDS parameter and some custom code (perhaps fodder for a future blog post). Regardless of the technology, Extreme BI requires a process for capturing and applying source system changes quickly and efficiently to the foundation layer on the Exadata Database Machine.Extreme Performance
Although I'll drill into more detail in the next post, the reason we need Extreme Performance is to offset the performance gains we usually get from star schemas, since we won't be building those, at least not in the initial iterations. Although Rittman Mead has deployed a variant of this methodology sans Exadata using a powerful Oracle Database RAC instead, there is no substitute for Exadata. Although the hardware on the Database Machine is superb, it's really the software that is a game-changer. The most extraordinary features include smart scan and storage indexes, as well as hybrid columnar compression, which Mark talks about here and references an article by Arup Nanda found here. For years now, with standard Oracle data warehouses, we've pushed the architecture to it's limits trying to reduce IO contention at the cost of CPU utilization, using database features such as partitioning, parallel query and basic block compression. But Exadata Storage can eliminate the IO boogeyman using combinations of these standard features plus the Exadata-only features to elevate the query performance against 3NF schemas on par with traditional star schemas and beyond.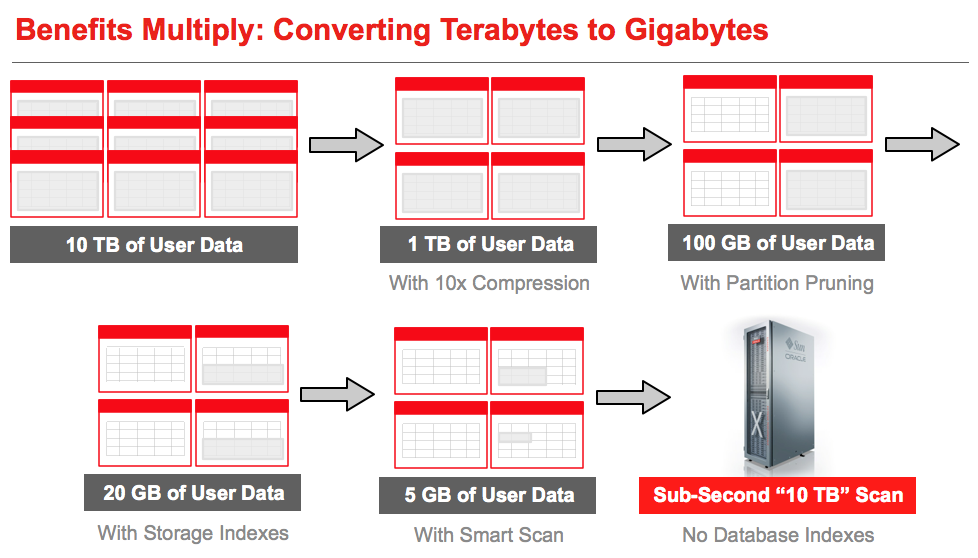
Extreme Metadata
Extreme performance is only half the battle... we also need Extreme Metadata to provide us the proper level of abstraction so that report and dashboard developers still have a simplistic model to report against. This is what OBIEE 11g brings to the table. We have also delivered a variant of this methodology without OBIEE, using Cognos instead, which has a metadata layer called Framework Manager. As with Exadata, the BI Server has no equal in the metadata department, so my advice... don't substitute ingredients.Consider, for a moment, the evolution of dimensional modeling in deploying a data warehouse. Not too long ago, we had to solve most data warehousing issues with the logical model because BI tools were simplistic. Generally... there was no abstraction of the physical into the logical, unless you categorize the renaming of columns as abstraction. As these tools evolved, we often found ourselves with a choice: solve some user need in the logical model, or solve it with the feature set of the BI tool. The use of aggregation in data warehousing is a perfect example of this evolution. Designing aggregate tables used to be just another part of the logical modeling exercise, and were generally represented in the published data model for the EDW. But now, building aggregates is more of a technical implementation than a logical one, as either the BI Server or the Oracle Database can handle the transparent navigation to aggregate tables.
The metadata that OBIEE provides adds two necessary features for Agile delivery. First, we are able to report against complex transactional schemas, but still expose those schemas as simplified dimensional models. This allows us to bypass the complex ETL process at least initially so that we can get new subject areas into the users hands in a single iteration. But OBIEE's capability to map multiple Logical Table Sources (LTS's) for the same logical table makes it easy to modify -- or "remap" -- the source of our logical tables over time. So, in later iterations, if we decide that it's necessary to embark upon complex ETL processes to complete user stories, we can do this in the metadata layer without affecting our reports and dashboards, or changing the logical model that report developers are used to seeing.
[caption id="attachment_9754" align="aligncenter" width="602" caption="Flow of Data Through the Three-Layer Semantic Model"] [/caption]
[/caption]