GoldenGate and Oracle Data Integrator - A Perfect Match... Part 3: Real-time ETL Challenges

I've finally had the chance to sit down and properly closeout this series on GoldenGate and Oracle Data Integrator. Since the last post, I’ve actually presented this topic on three different occasions. Once at each of the Rittman Mead BI Forums, in both Brighton and Atlanta, as a part of the ODI Masterclass, and once in New Orleans at KScope13. Hopefully you were able to attend one of these sessions and learn a few new things about data integration.
In the previous post, “GoldenGate and Oracle Data Integrator – A Perfect Match… Part 2: Replicate to Staging and Foundation”, I described the setup and configuration of GoldenGate via ODI 11g at a high level. Now we have the GoldenGate parameter files configured, replication is active from the source to both Staging and Foundation layer schemas, and the ODI Change Data Capture (CDC) framework is in place. In this, the final post in the series, I will switch the focus to ODI Change Data Capture (CDC), walking through several options to using change data in downstream ETL processes.

Real-Time ETL Using Oracle Data Integrator CDC
ETL mappings, built as Interfaces in Oracle Data Integrator 11g, are developed to populate the Access and Performance layer. Remember from previous posts that this layer is where the traditional star schemas are built and accessed by reporting and analytical tools, such as OBIEE. The Interfaces will use the ODI Change Data Capture (CDC) framework to flow data captured in the change tables through to the target. To recap, ODI CDC is setup to identify, capture, and deliver changes made to data in the source database. When Journalizing is started on a Model, not only are the GoldenGate parameter files created, but also the ODI CDC Framework is generated. The CDC framework includes the following:- Journals - tables (prefixed with J$) that hold references to the change records and the change type (insert/update/delete)
- Journalizing views - (prefixed with JV$, JV$D) provide access to the change data by joining the journal table to the fully replicated table, and are used by IKM’s and LKM’s to access the change rows
- Capture processes - captures changed data from source datastores (in this example, Oracle GoldenGate)
- Subscribers - entities that consume the changed data as a consistent set
Using Journalized Data
Once journalizing is setup and changes are being captured, building an interface for real-time data warehousing is quite simple. Well, sort of simple. Add the journalized Datastore to the Interface as a source and check the “Journalized data only” checkbox. This will change the source of the Interface in the generated code to be the JV$ change view rather than the actual table. The JV$ view will contain only the change rows available within the window after the “extend window” process is called. The Interface is executed and the journal is purged, setting up the process for the next run.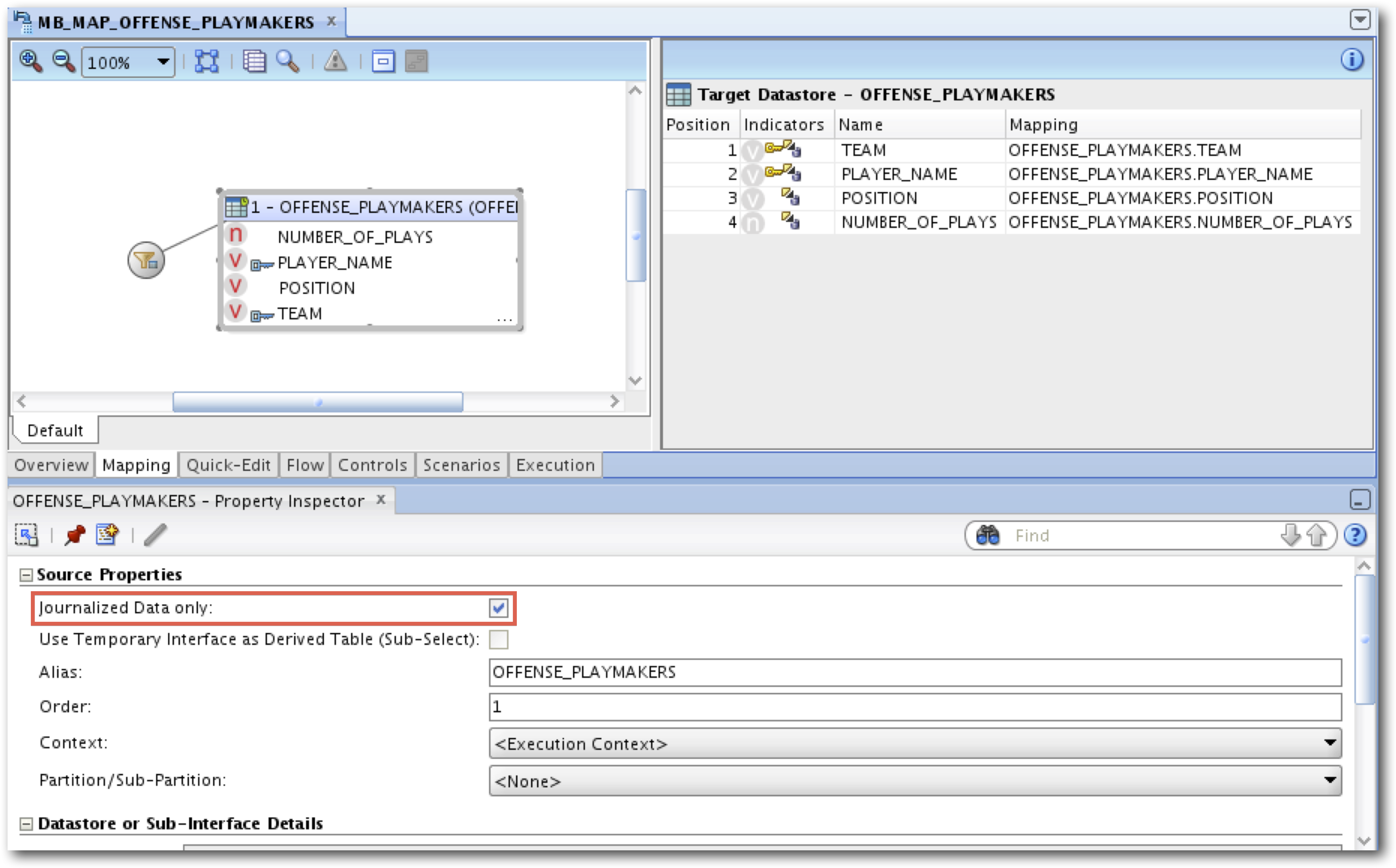
Parent-Child Relationship
Often a join between two source tables is due to a parent-child relationship: Department->Employee, Order->Order Line, etc. In this situation, and with any join really, we want to capture the change data from each individual table and only lookup additional data from the other table via the join when necessary to complete the full record. Unfortunately, this setup is not possible in a single Interface as was just described. So how do we work around it?We must create two Interfaces; both with the exact same logic, source Datastores, and target Datastore. The only difference will be which source Datastore is using the “Journalized data only” option. This approach will ensure that no transaction is left behind and all changes will flow through to the target with the appropriate lookup data filled in for each row.
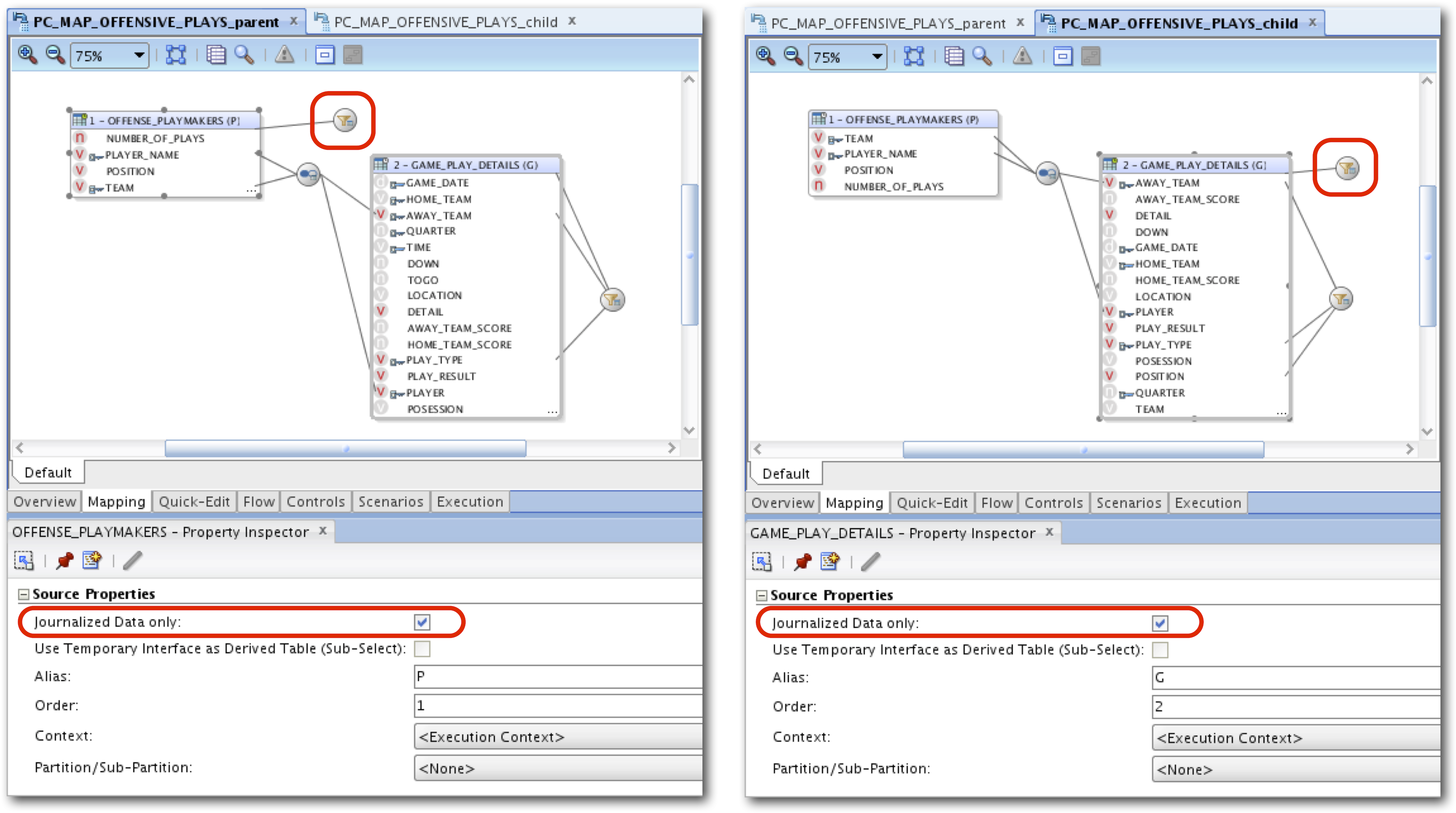
ODI Cookbook Example
There is another workaround, outlined in the new book “Oracle Data Integrator 11g Cookbook”, that takes a similar approach but with potentially less maintenance headaches. This method separates the final interface, and all of its logic, from the activity of ensuring that each table has its changes processed along with the additional lookup data from other supporting tables. I won’t go into details here (the book is well worth the purchase), but I can say this approach does look promising.Subscription Views
A final option for moving data from the change tables through to the target facts and dimensions as quickly as possible can be achieved using what we call subscription views. The goal here is to always return a consistent set of data and to let the ETL developer make the choice as to how this is accomplished. In this solution, the “Journalized data only” checkbox is never checked for any of the source Datastores in the Interface. Instead, we create a view for each of the Staging schema tables and include a join to the ODI J$ change table.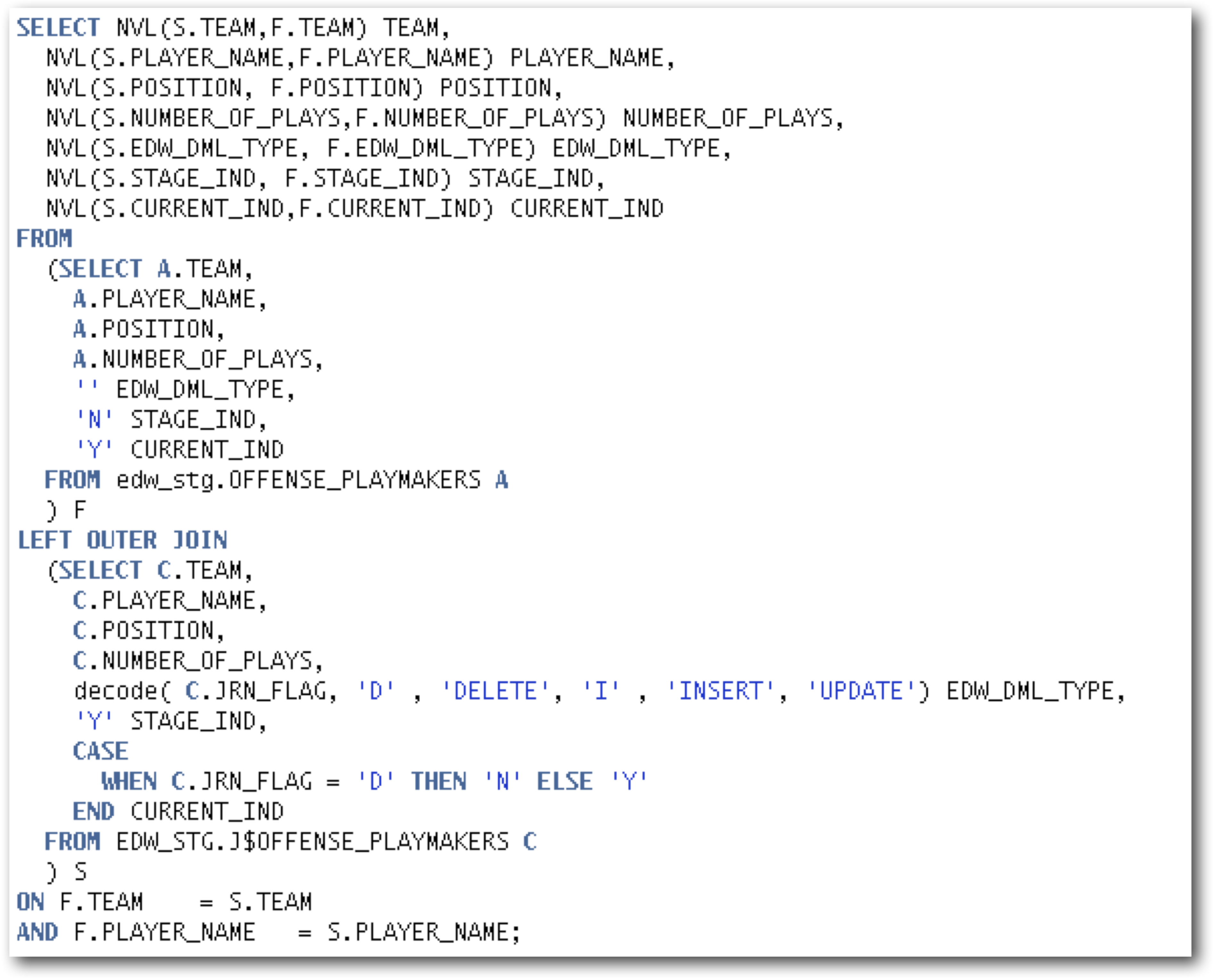
- STAGE_IND – Indicates the rows that are ready to be consumed for the first time. In other words, these rows have not yet been “seen” by the process.
- CURRENT_IND – The most recent version of that row by natural key, which, timing aside, matches the record in the source.
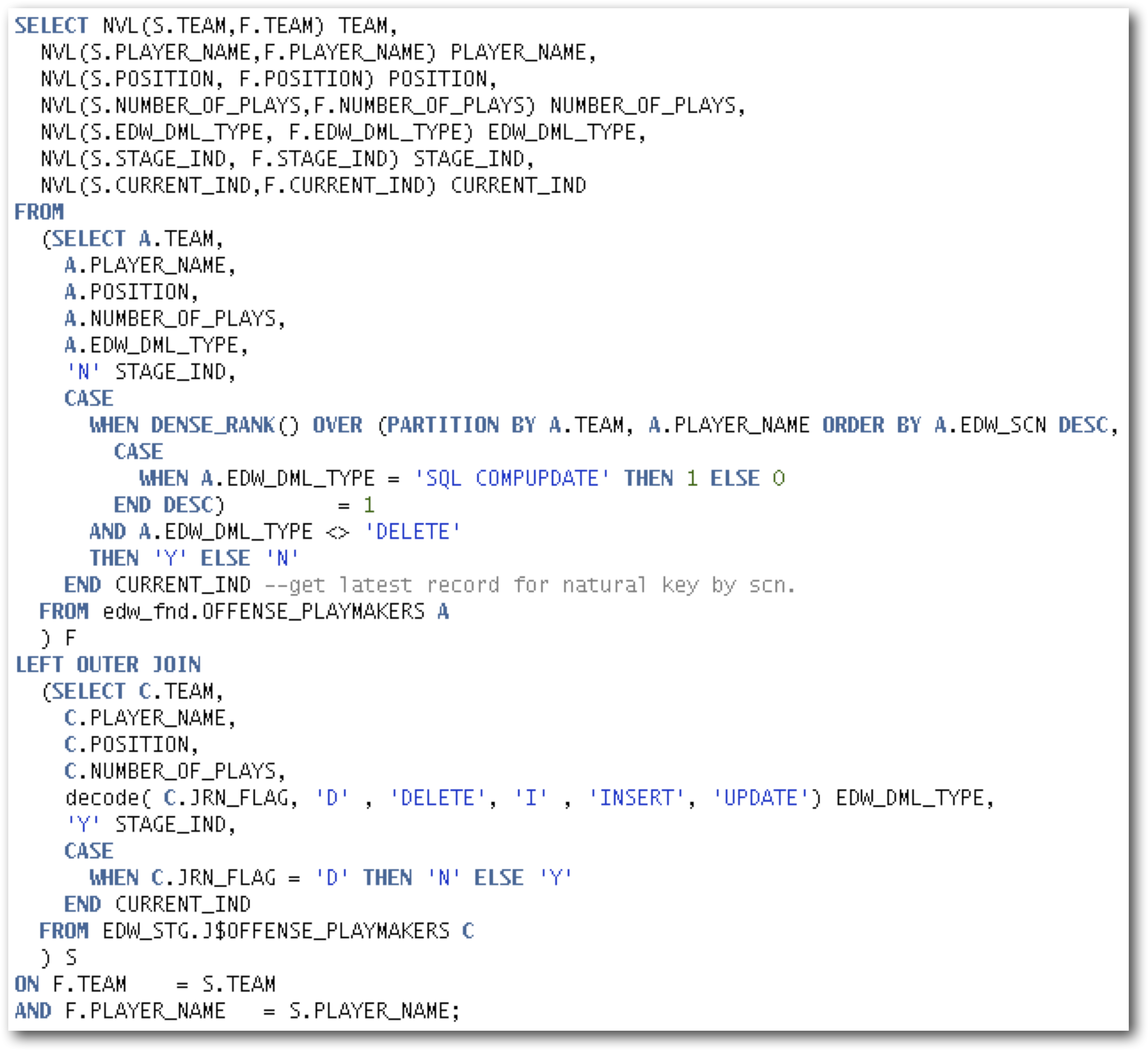
GoldenGate and Oracle Data Integrator - A Perfect Match...
1. Introduction
2. Replicate to Staging and Foundation
3. Real-time ETL Challenges
If you’re interested in learning more about GoldenGate and ODI, please drop us a line at info@rittmanmead.com. We offer our Oracle Data Integrator 11g “Bootcamp” course both as a publicly available class coming up in Atlanta (Oct 28 – Nov 1) and Brighton (Aug 12 – 16 & Oct 21 – 25) or we can always schedule a visit to your company site.