Setting up Security and Access Control on a Big Data Appliance

Like all Oracle Engineered Systems, Oracle’s field servicing and Advanced Customer Services (ACS) teams go on-site once a BDA has been sold to a customer and do the racking, installation and initial setup. They will usually ask the customer a set of questions such as “do you want to enable Kerberos authentication”, “what’s the range of IP addresses you want to use for each of the network interfaces”, “what password do you want to use” and so on. It’s usually enough to get a customer going, but in-practice we’ve found most customers need a number of other things set-up and configured before they use the BDA in development and production; for example:
- Integrating Cloudera Manager, Hue and other tools with the corporate LDAP directory
- Setting up HDFS and SSH access for the development and production support team, so they can log in with their usual corporate credentials
- Come up with a directory layout and file placement strategy for loading data into the BDA, and then moving it around as data gets processed
- Configuring some sort of access control to the Hive tables (and sometimes HDFS directories) that users use to get access to the Hadoop data
- Devising a backup and recovery strategy, and thinking about DR (disaster recovery)
- Linking the BDA to other tools and products in the Oracle Big Data and Engineered Systems family; Exalytics, for example, or setting up ODI and OBIEE to access data in the BDA
The first task we’re usually asked to do is integrate Cloudera Manager, the web-based admin console for the Hadoop parts of the BDA, with the corporate LDAP server. By doing this we can enable users to log into Cloudera Manager with their usual corporate login (and restrict access to just certain LDAP groups, and further segregate users into admin ones and stop/start/restart services-type ones), and similarly allow users to log into Hue using their regular LDAP credentials. In my experience Cloudera Manager is easier to set up than Hue, but let’s look at a high-level at what’s involved.
LDAP Integration for Hue, Cloudera Manager, Hive etc
In our Rittman Mead development lab, we have OpenLDAP running on a dedicated appliance VM and a number of our team setup as LDAP users. We’ve defined four LDAP groups, two for Cloudera Manager and two for Hue, with varying degrees of access for each product.

Setting up Cloudera Manager is pretty straightforward, using the Administration > Settings menu in the Cloudera Manager web UI (note this option is only available for the paid, Cloudera Enterprise version, not the free Cloudera Express version). Hue security integration is configured through the Hue service menu, and again you can configure the LDAP search credentials, any LDAPS or certificate setup, and then within Hue itself you can define groups to determine what Hue features each set of users can use.

Where Hue is a bit more fiddly (last time I looked) is in controlling access to the tool itself; Cloudera Manager lets you explicitly define which LDAP groups can access the tool with other users then locked-out, but Hue either allows all authenticated LDAP users to login to the tool or makes you manually import each authorised user to grant them access (you can then either have Hue check-back to the LDAP server for their password each login, or make a copy of the password and store it within Hue for later use, potentially getting out-of-sync with their LDAP directory password version). In practice what I do is use the manual authorisation method but then have Hue link back to the LDAP server to check the users’ password, and then map their LDAP groups into Hue groups for further role-based access control. There’s a similar process for Hive and Impala too, where you can configure the services to authenticate against LDAP, and also have Hive use user impersonation so their LDAP username is passed-through the ODBC or JDBC connection and queries run as that particular user.
Configuring SSH and HDFS Access and Setting-up Kerberos Authentication
Most developers working with Hadoop and the BDA will either SSH (Secure Shell) into the cluster and work directly on one of the nodes, or connect into their workstation which has been configured as a Hadoop client for the BDA. If they SSH in directly to the cluster they’ll need Linux user accounts there, and if they go in via their workstation the Hadoop client installed there will grant them access as the user they’re logged-into the workstation as. On the BDA you can either set-up user accounts on each BDA node separately, or more likely configure user authentication to connect to the corporate LDAP and check credentials there.

One thing you should definitely do, either when your BDA is initially setup by Oracle or later on post-install, is configure your Hadoop cluster as a secure cluster using Kerberos authentication. Hadoop normally trusts that each user accessing Hadoop services via the Hadoop Filesystem API (FS API) is who they say they are, but using the example above I could easily setup an “oracle” user on my workstation and then access all Hadoop services on the main cluster without the Hadoop FS API actually checking that I am who I say I am - in other words the Hadoop FS API shell doesn’t check your password, it merely runs a “whoami” Linux command to determine my username and grants me access as them.

The way to address this is to configure the cluster for Kerberos authentication, so that users have to have a valid Kerberos ticket before accessing any secured services (Hive, HDFS etc) on the cluster. I covered this as part of an article on configuring OBIEE11g to connect to Kerberos-secured Hadoop clusters last Christmas and you can either do it as part of the BDA install, or later on using a wizard in more recent versions of CDH5, the Cloudera Hadoop distribution that the BDA uses.

The complication with Kerberos authentication is that your organization needs to have a Kerberos KDC (Key Distribution Center) server setup already, which will then link to your corporate LDAP or Active Directory service to check user credentials when they request a Kerberos ticket. The BDA installation routine gives you the option of creating a KDC as part of the BDA setup, but that’s only really useful for securing inter-cluster connections between services as it won’t be checking back to your corporate directory. Ideally you’d set up a connection to an existing, well-tested and well-understood Kerberos KDC server and secure things that way - but beware that not all Oracle and other tools that run on the BDA are setup for Kerberos authentication - OBIEE and ODI are, for example, but the current 1.0 version of Big Data Discovery doesn’t yet support Kerberos-secured clusters.
Coming-up with the HDFS Directory Layout
It’s tempting with Hadoop to just have a free-for-all with the Hadoop HDFS filesystem setup, maybe restricting users to their own home directory but otherwise letting them put files anywhere. HDFS file data for Hive tables typically goes in Hive’s own filesystem area /user/hive/warehouse, but users can of course create Hive tables over external data files stored in their own part of the filesystem.
What we tend to do (inspired by Gwen Shapira’a “Scaling ETL with Hadoop” presentation) is create separate areas for incoming data, ETL processing data and process output data, with developers then told to put shared datasets in these directories rather than their own. I generally create additional Linux users for each of these directories so that these can own the HDFS files and directories rather than individual users, and then I can control access to these directories using HDFS’s POSIX permissions. A typical user setup script might look like this:
[oracle@bigdatalite ~]$ cat create_mclass_users.sh sudo groupadd bigdatarm sudo groupadd rm_website_analysis_grp useradd mrittman -g bigdatarm useradd ryeardley -g bigdatarm useradd mpatel -g bigdatarm useradd bsteingrimsson -g bigdatarm useradd spoitnis -g bigdatarm useradd rm_website_analysis -g rm_website_analysis_grp echo mrittman:welcome1 | chpasswd echo ryeardley:welcome1 | chpasswd echo mpatel:welcome1 | chpasswd echo bsteingrimsson:welcome1 | chpasswd echo spoitnis:welcome1 | chpasswd echo rm_website_analysis:welcome1 | chpasswd
whilst a script to setup the directories for these users, and the application user, might look like this:
[oracle@bigdatalite ~]$ cat create_hdfs_directories.sh set echo on #setup individual user HDFS directories, and scratchpad areas sudo -u hdfs hadoop fs -mkdir /user/mrittman sudo -u hdfs hadoop fs -mkdir /user/mrittman/scratchpad sudo -u hdfs hadoop fs -mkdir /user/ryeardley sudo -u hdfs hadoop fs -mkdir /user/ryeardley/scratchpad sudo -u hdfs hadoop fs -mkdir /user/mpatel sudo -u hdfs hadoop fs -mkdir /user/mpatel/scratchpad sudo -u hdfs hadoop fs -mkdir /user/bsteingrimsson sudo -u hdfs hadoop fs -mkdir /user/bsteingrimsson/scratchpad sudo -u hdfs hadoop fs -mkdir /user/spoitnis sudo -u hdfs hadoop fs -mkdir /user/spoitnis/scratchpad #setup etl directories sudo -u hdfs hadoop fs -mkdir -p /data/rm_website_analysis/logfiles/incoming sudo -u hdfs hadoop fs -mkdir /data/rm_website_analysis/logfiles/archive/ sudo -u hdfs hadoop fs -mkdir -p /data/rm_website_analysis/tweets/incoming sudo -u hdfs hadoop fs -mkdir /data/rm_website_analysis/tweets/archive #change ownership of user directories sudo -u hdfs hadoop fs -chown -R mrittman /user/mrittman sudo -u hdfs hadoop fs -chown -R ryeardley /user/ryeardley sudo -u hdfs hadoop fs -chown -R mpatel /user/mpatel sudo -u hdfs hadoop fs -chown -R bsteingrimsson /user/bsteingrimsson sudo -u hdfs hadoop fs -chown -R spoitnis /user/spoitnis sudo -u hdfs hadoop fs -chgrp -R bigdatarm /user/mrittman sudo -u hdfs hadoop fs -chgrp -R bigdatarm /user/ryeardley sudo -u hdfs hadoop fs -chgrp -R bigdatarm /user/mpatel sudo -u hdfs hadoop fs -chgrp -R bigdatarm /user/bsteingrimsson sudo -u hdfs hadoop fs -chgrp -R bigdatarm /user/spoitnis #change ownership of shared directories sudo -u hdfs hadoop fs -chown -R rm_website_analysis /data/rm_website_analysis sudo -u hdfs hadoop fs -chgrp -R rm_website_analysis_grp /data/rm_website_analysis
Giving you a directory structure like this (with the directories for Hive, Impala, HBase etc removed for clarity)
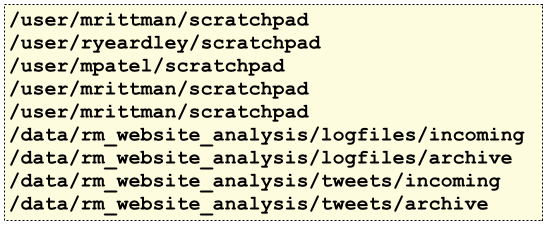
In terms of Hive and Impala data, there’s varying opinions on whether to create tables as EXTERNAL and store the data (including sub-directories for table partitions) in the /data/ HDFS area or let Hive store them in its own /user/hive/warehouse area - I tend to let Hive store them within its area as I use Apache Sentry to then control access to those Tables’s data.
Setting up Access Control for HDFS, Hive and Impala Data
At its simplest level, access control can be setup on the HDFS directory structure by using HDFS’s POSIX security model:
- Each HDFS file or directory has an owner, and a group
- You can add individual Linux users to a group, but an HDFS object can only have one group owning it
What this means in-practice though is you have to jump through quite a few hoops to set up finer-grained access control to these HDFS objects. What we tend to do is set RW access to the /data/ directory and subdirectories to the application user account (rm_website_analysis in this case), and RO access to that user’s associated group (rm_website_analysis_grp). If users then want access to that application’s data we add them to the relevant application group, and a user can belong to more than one group, making it possible to grant access to more than one application data area
[oracle@bigdatalite ~]$ cat ./set_hdfs_directory_permissions.sh sudo -u hdfs hadoop fs -chmod -R 750 /data/rm_website_analysis usermod -G rm_website_analysis_grp mrittman
making it possible for the main application owner to write data to the directory, but group members only have read access. What you can also now do with more recent versions of Hadoop (CDH5.3 onwards, for example) is define access control lists to go with individual HDFS objects, but this feature isn’t enabled by default as it consumes more namenode memory than the traditional POSIX approach. What I prefer to do though is control access by restricting users to only accessing Hive and Impala tables, and using Apache Sentry, or Oracle Big Data SQL, to provide role-based access control over them.
Apache Sentry is a project originally started by Cloudera and then adopted by the Apache Foundation as an incubating project. It aims to provide four main authorisation features over Hive, Impala (and more recently, the underlying HDFS directories and datafiles):
- Secure authorisation, with LDAP integration and Kerberos prerequisites for Sentry enablement
- Fine-grained authorisation down to the column-level, with this feature provided by granting access to views containing subsets of columns at this point
- Role-based authorisation, with different Sentry roles having different permissions on individual Hive and Impala tables
- Multi-tenant administration, with a central point of administration for Sentry permissions
From this Cloudera presentation on Sentry on Slideshare, Sentry inserts itself into the query execution process and checks access rights before allowing the rest of the Hive query to execute. Sentry is configured through security policy files, or through a new web-based interface introduced with recent versions of CDH5, for example.

The other option for customers using Oracle Exadata,Oracle Big Data Appliance and Oracle Big Data SQL is to use the Oracle Database’s access control mechanisms to govern access to Hive (and Oracle) data, and also set-up fine-grained access control (VPD), data masking and redaction to create a more “enterprise” access control system.

So these are typically tasks we perform when on-boarding an Oracle BDA for a customer. If this is of interest to you and you can make it to either Brighton, UK next week or Atlanta, GA the week after, I’ll be covering this topic at the Rittman Mead BI Forum 2015 as part of the one-day masterclass with Jordan Meyer on the Wednesday of each week, along with topics such as creating ETL data flows using Oracle Data Integrator for Big Data, using Oracle Big Data Discovery for faceted search and cataloging of the data reservoir, and reporting on Hadoop and NoSQL data using Oracle Business Intelligence 11g. Spaces are still available so register now if you’d like to hear more on this topic.