Becky's BI Apps Corner: Incrementals and Future Dated Employee Records


During the last few posts, we have delved into a few of the many interesting aspects of a BI Apps installation. Today I wanted to change gears a bit and talk about what starts to happen when you are past installation and configuration and begin running load plans. On a client project, I recently worked through a unique constraint error on W_EMPLOYEE_D that I found really interesting related to how the incremental logic was working in the knowledge module (KM). Before I can really get into the workaround, we need to understand how incremental loads work in general for BI Apps.
High Level Overview
In the initial run, the load will grab a full set of data, i.e. all data from the source system, based on the data load parameters set during configuration. The same load plan will be used to load data incrementally, picking up only data that has changed since the most recent load plan has completed (Last Extract Date). The pre-built mappings have incremental change capture built into the knowledge module logic. When a load runs, it will extract records that have changed or been created since the Last Extract Date. The load plan determines which rows to extract by using the formula Source Last Updated Date >= (Last Extract Date - Prune Days).
In the Weeds
Is it an incremental load? How does that get decided? Actually, that isn’t decided at the load plan level. Each individual package (run as a scenario) starts with a step that refreshes a variable called #IS_INCREMENTAL.
This variable’s refresh logic, shown in the below screenshot, will determine if this package previously completed successfully. After every successful completion an entry gets made into W_ETL_LOAD_DATES with the package name and date timestamp, amongst other audit information.
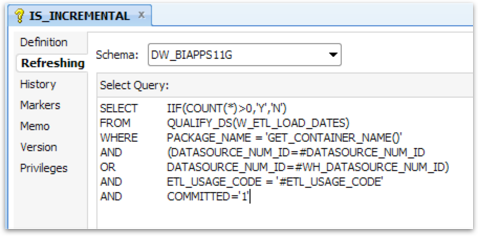
So we have a scenario running now with the #IS_INCREMENTAL be set to ‘Y’. What does the Knowledge Module (KM) do? Incremental runs normally have steps to load an I$ table (flow table) from the source logic and update the records in the target table based on the DETECTION_STRATEGY option in the KM. For Fact table loads, the option can accept the possible values (explanation given).
- OUTER: Outer join to target table when populating flow table in order to determine insert/update/useless records
- NOT_EXISTS: NOT EXISTS clause is used when populating flow table in order to exclude records, which identically exist in target.
- POST_FLOW: all records from source are loaded into flow table. After that an update statement is used to flag all rows in flow table, which identically exist in target.
- NONE: all records from source are loaded into flow table. All target records are updated even when a target record is identical to flow table record.
In most cases, the option OUTER is used for facts, which updates the records based on primary keys (PK’s). Incremental decisions are based on the values of the system date columns like CHANGED_ON_DT, AUX1_CHANGED_ON_DT, AUX2_CHANGED_ON_DT, AUX3_CHANGED_ON_DT and AUX4_CHANGED_ON_DT columns populated from the source. This is better performing than the NOT_EXISTS and POST_FLOW options that compares each and every column to identify the records present.
For Slowly Changing Dimensions (like W_EMPLOYEE_D), the DETECTION_STRATEGY option can take the possible values (explanation given).
- MINUS: MINUS clause is used when populating flow table in order to exclude records, which identically exist in target.
- NOT_EXISTS: NOT EXISTS clause is used when populating flow table in order to exclude records, which identically exist in target.
The default option is NOT_EXISTS and Incremental decisions are based on PK’s and the date columns.
Future Dated Rows
Imagine now that during a full load, all records from the source tables for EMPLOYEES are brought forward into the data warehouse table W_EMPLOYEE_D. One of those records is an entry with an effective start date 2 weeks in the future. For W_EMPLOYEE_D one of the columns in the primary key is the effective start date. Fast forward two weeks to the date when the future dated row’s effective start date is the current date. During the incremental load on that date, the incremental logic for this one record is comparing the primary keys and all of the change indicator columns, and sees that the effective start date is greater than the last extract date from last night. This incremental comparison incorrectly determines this is a record that needs to be added to the fact table, even though the record is already in the fact table. Now we have an ERROR! The familiar unique constraint on the _U1 unique index rears its ugly head. On top of that, troubleshooting this duplicate is not coming up with any duplicate records in the usual places (I$, DS, source tables, nada!). Isolating the two identical records and tracking them back to the source tables however, there is the one record. The only clue is that the effective start date is today’s date. After a second occurrence, discussions and back and forth on an SR, a workaround is now available.
Workaround
Step 1. Remove any Future dated rows in W_EMPLOYEE_D
Step 2. Add a filter on the interface to prevent future dated rows from loading into W_EMPLOYEE_DS until they are <= current date.
At our client, this mapping continues to run without any additional errors. The steps here are most likely version specific, and this issue is a known bug to Oracle, so please don’t hesitate to open an SR if you are getting this specific issue, as a quick turn around is very likely.
There are some other odds and ends about how incremental load plans work and I plan to gather them up and have another post about those in the coming weeks. If you want to learn more ins and outs of incrementals and more, join me for the upcoming remote ODI for BIApps course on March 14th-16th. We have only a few spots left so sign up here.