Combining Google Analytics and JSON data through Apache Drill in Oracle Data Visualization Desktop

I've been talking a lot about Oracle's Data Visualization Desktop (DVD) recently, explaining DVD 12.2.2.0 new features and the details of Data Flow component via a fantasy football use case.
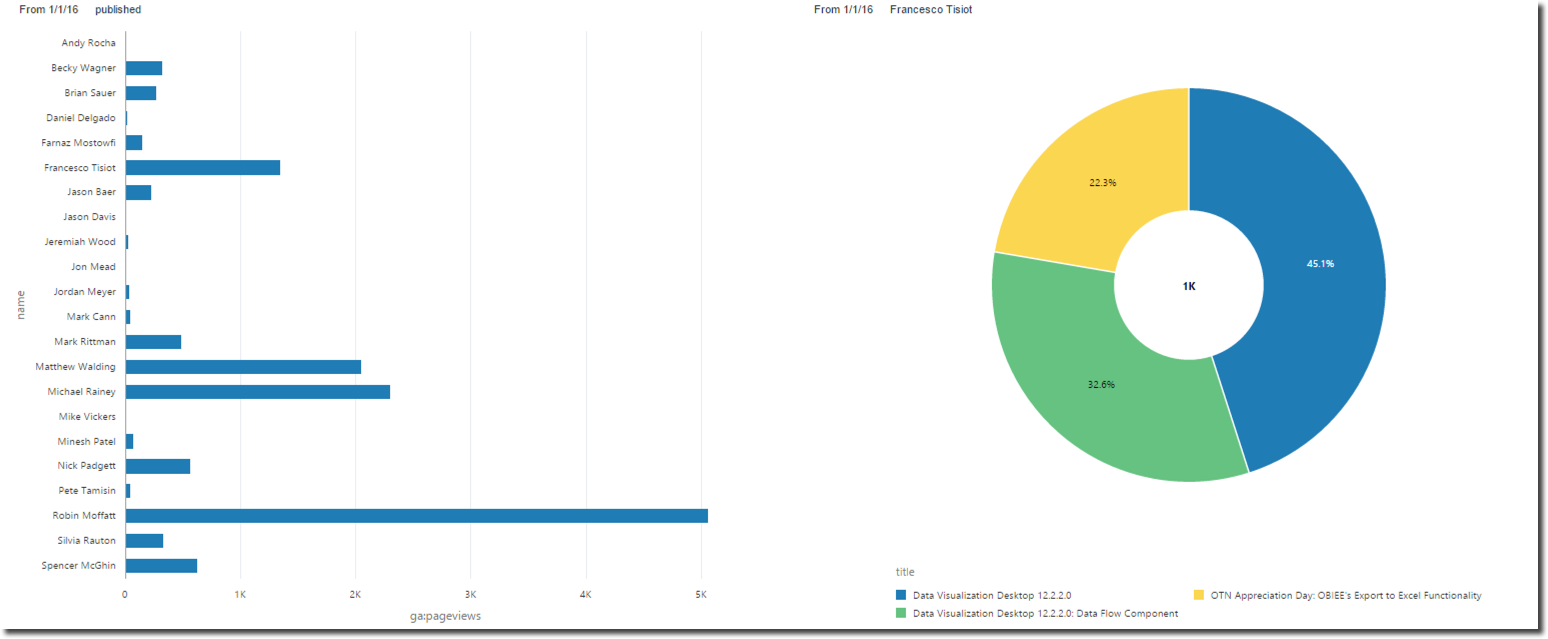
Yesterday a new requirement was raised within Rittman Mead: we wanted to analyse our blog stats and specifically understand the number of page views per author of blog posts published in 2016. The two sources of our data were:
- Google Analytics: a web analytics service provided by Google that tracks and reports website traffic.
- Ghost: our blogging platform, the data extracted from Ghost contains author and post information in JSON format.
My colleague Robin Moffatt already explained in his post how to connect DVD to Google Analytics and how to query JSON files with Apache Drill. Both sources are compatible with DVD, and in this blog post I'll explain my journey in the analysis with the tool to combine both sources.
Ghost JSON data preparation
Following Robin's blog I created two Apache Drill views on top of Ghost Data:
- vw_fact_post: containing the post information
create or replace view vw_fact_posts as
select
po.post.id id,
po.post.uuid uuid,
po.post.title title,
po.post.slug slug,
po.post.markdown markdown,
po.post.published_by published_by,
cast(po.post.published_at as date) published_at,
po.post.updated_at updated_at,
po.post.created_by created_by,
cast(po.post.created_at as date) created_at,
po.post.author_id author_id,
po.post.meta_description meta_description,
po.post.visibility visibility,
po.post.`language` lan,
po.post.status status from
(select flatten(ghost.db.data.posts) post from dfs.tmp.ghost) po;
- vw_dim_author: containing author data.
select author.u.id id,
author.u.name name,
author.u.slug slug,
author.u.password pwd,
author.u.email email,
author.u.image image,
author.u.status status,
author.u.`language` lan,
author.u.visibility visibility,
author.u.last_login last_login,
author.u.created_at created_at,
author.u.updated_at updated_at,
author.u.updated_by updated_by
from (select flatten(ghost.db.data.`users`) u from dfs.tmp.ghost) author;
The views are not strictly required for the purpose of the analysis since Drill SQL can be directly injected in DVD however creating them has two advantages:
- the interface between DVD and Drill is cleaner, no complex sql has to be entered and debugged
- the views can be reused for other projects outside DVD if needed
DVD Data Source Settings
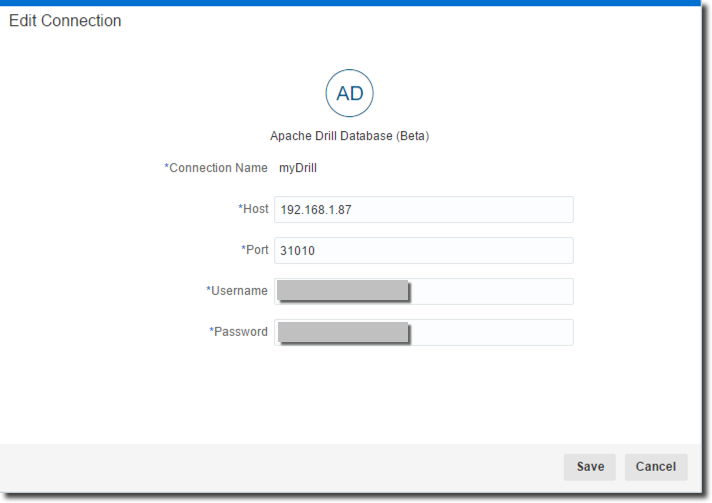
Robin's post provided all the details needed to connect to Google Analytics, no need to add anything there. Apache Drill datasource setting is pretty easy - we just need to specify hostname and port where Drill is running along with the connection username and password.
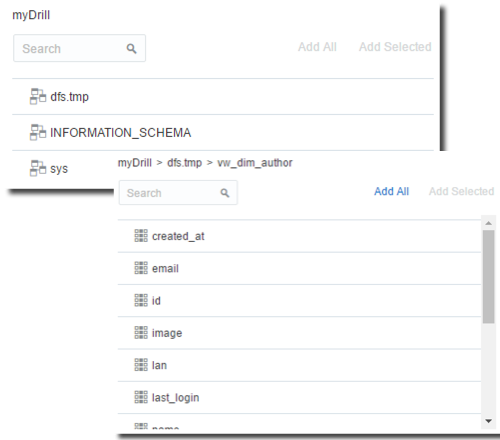
Once the Drill connection is working I can start importing the views. I do it by selecting the myDrill connection, choosing the dfs.tmp database, selecting the view I want to import and clicking on Add All or selecting the columns.
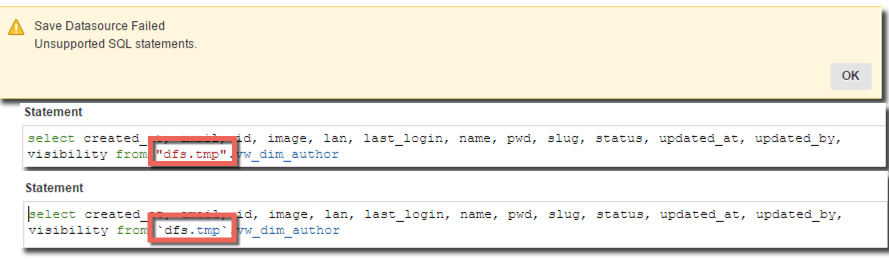
When clicking on OK an "Unsupported SQL statements" error may be raised. This is due to the wrong usage of double quotation marks (") instead of the backtick (`) needed by Drill. I amended the error by clicking on Enter SQL and changing the Drill SQL as in image below.
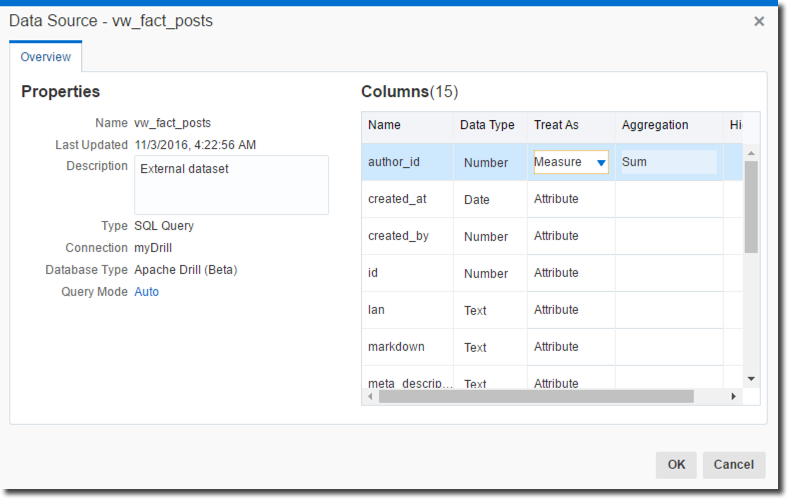
Having imported the two sources I can review the Measure/Attribute definitions as well as the aggregation methods. This is a crucial point since the associations are made automatically and could be wrong. In my case author_id column was automatically declared as a Measure, which prevented me from using it in joins. I can fix the definitions by right clicking on the source, select Inspect and amend the Measure/Attribute definition.
Wrangling Google Analytics Data
DVD's Google Analytics connector exposes a set of pre-aggregated views of the tracking data. The Page Tracking view contains a summary of page views, entrances, exit rates and other KPIs at page level - exactly the information I was looking for.
![]()
I then started analysing Page Tracking data within DVD, and found some discrepancies within the data.
- we recently moved our blog from Wordpress to Ghost: all pages accessed since rittmanmead.com website is on Ghost have the
/blog/prefix, the same was not happening when we were still in Wordpress. - the page name could contain a query string appendix like
/?..... - Ghost slug contains the pure page name, without folder prefix like
/blog/2014/and without starting and ending/
The following is an example of data retrieved from Google Analytics, all for one actual blog post.

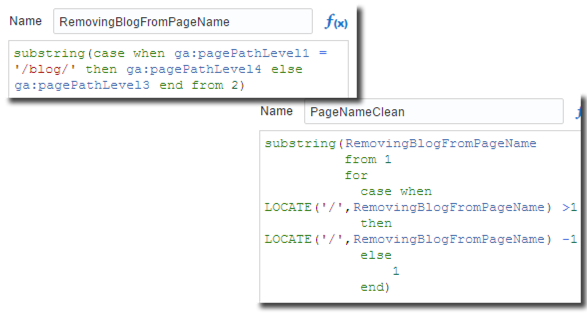
The wrangling of Google Analytics data was necessary and DVD's Data Flow component suited perfectly my needs. I started by importing Page Tracking data source, then by adding two columns:
-
RemovingBlogFromPageName in order to avoid the Ghost/Wordpress problem described above with a
case-whenand removing the initial/using thesubstring -
PageNameClean to remove extra appendix like
/?.....with asubstringfunction
I then added the Aggregate step to define the Measures/Attributes and aggregation types. Finally I saved the result locally.
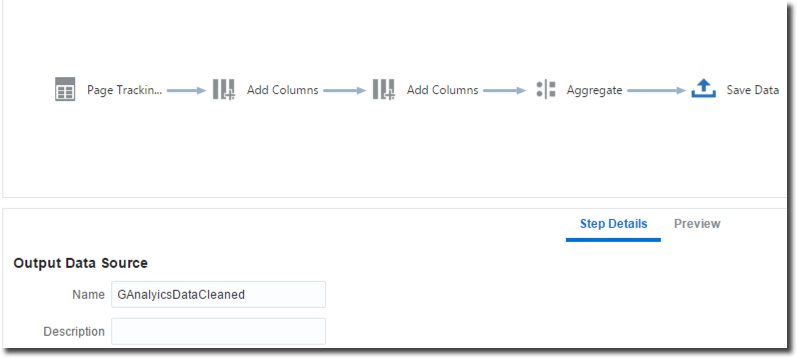
The two columns were added in two consecutive Add Columns steps since RemovingBlogFromPageName column is a dependency in the in PageNameClean formula. In a single Add Columns step several columns can be added if they are referencing columns already existing in the dataset.
Creating the Project
In my previous post I linked several data sources with Data Flow, this is always possible but in this case I tried a different approach: the link between Google Analytics and Ghost data (through Drill) was defined directly in DVD Project itself.
First step was to include the Drill datasources: I added vw_fact_post initially and then vw_dim_author by right clicking and selecting Add Data Souce.
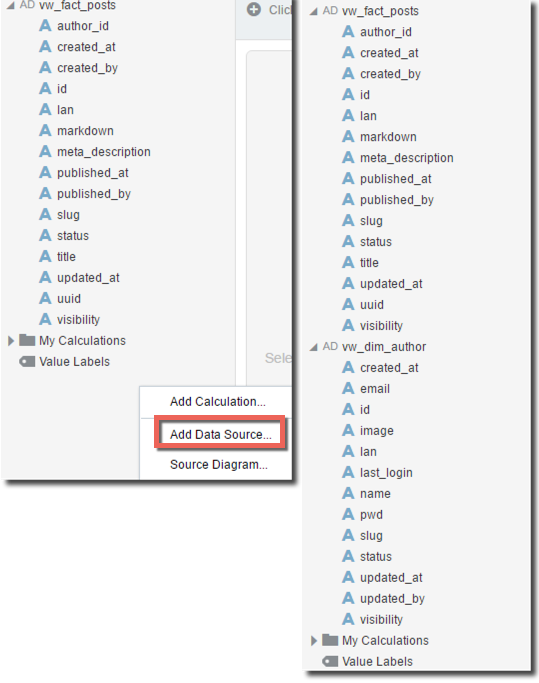
Both sources are now visible in my project and the join between them is auto-generated and based on column name matching. In my case this was wrong and I reviewed and changed it by right clicking, selecting Source Diagram and correcting the joning conditions.
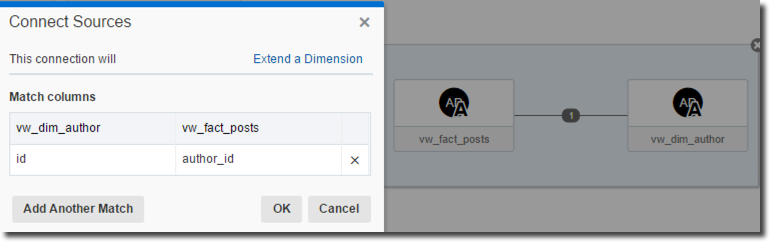
Note that I set the Parameter "This connection will" to "Extend a dimension" since the author data is adding attributes to my post data.
Next step was adding Google Analytics refined dataset that I stored locally with Data Flow. I can do it by right clicking, selecting Add Data Souce and then GAAnalyticsDataCleansed. The new source could not be visible immediately in my project, this was due to the lack of matching columns names for the automatic join to be working. I added the joining condition in the Source Diagram section.
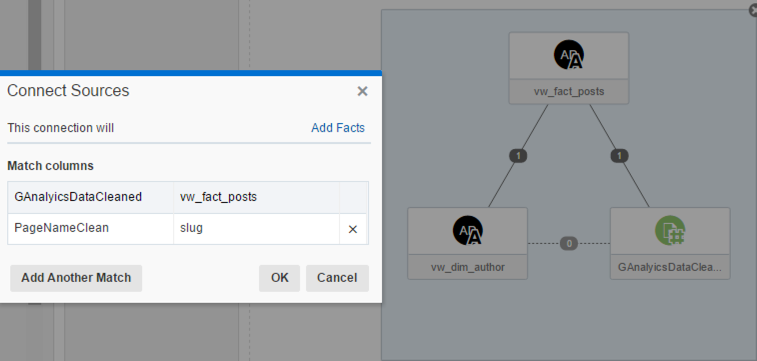
Note that in this case the "This connection will" parameter is set to "Add Facts" since Google Analytics data contains the number of page views and other metrics.
After amending the joining condition I'm finally able to include any columns from my datasource in my project. Here we’ve met the requirement to see post metrics by author, all in DVD and through a very intuitive and accessible interface.