OBIEE Data Modeling Tips #2: Fragmentation
Following on from yesterday's integration of a number of normalized tables into a simplified star schema, today I'm going to look at the fragmentation feature of Oracle BI Server, where a single logical table - sales, for example - can be sourced from two different physical tables, with one table holding historical data, and one table holding more recent data. I'm going to use the same base data set as yesterday, supplemented by a more or less identical data set that holds historic information. In my opinion, fragmentation is one of the most tricky BIEE features to set up and this is my first take on the process, so again if anyone's done this before and has got a better or more efficient way to do it, let me know in the comments.
Taking a look at the physical model, I have two physical source schemas; the SOADEMO one that I used yesterday that has "recent" data in it, and a new CUSTDW schema that contains my "historical" data.
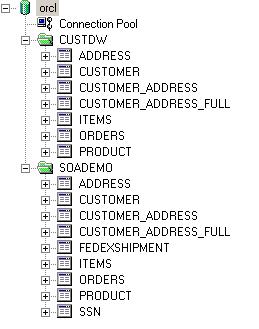
Looking at the data in more detail, it has these characteristics:
- the Orders and Items tables in the SOADEMO schema have two orders and three items in them, whilst the CUSTDW versions have nine orders and nineteen items and don't include those in the SOADEMO tables, i.e. the two sets of tables are mutually exclusive.
- the Customer table in SOADEMO contains details of three customers, the CUSTDW contains details of nine customers including the same three that are in the SOADEMO schema, i.e. we need to do a 'distinct' on the two data sets
- the Product table in both SOADEMO and CUSTDW contain exactly the same data, again we'll have to do a distinct on them.
Notice also a new table (it's a view, actually) called CUSTOMER_ADDRESS_FULL; I've used this to remove the intersection table between Customer and Address by copying across all the address information into one table keyed on Customer ID, I needed to this later on to get the dataset working properly with fragmentation. I'll get on to why later in the posting.
In practice, I found it easier to start afresh with a new logical model rather than add fragmentation into yesterday's logical model. I don't know if I was doing something wrong (I suspect so) or it's difficult to add fragmentation to existing models, but for me it worked best if I created a new model and added fragmentation in from the start. To start then, I created a new model and dropped in the Orders and Items tables from the SOADEMO schema, then joined the two tables just like yesterday.
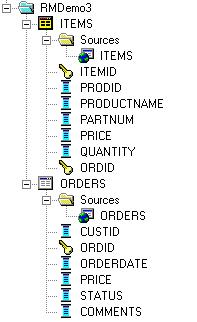
Note how Orders is linked, dimension-like to Items as Items contains multiple entries for orders, one for each item in the order.
Next, I drag and drop the Orders and Items tables from the CUSTDW schema right on top of the Orders and Items tables on the logical model, adding a second physical source for each logical table, like this:
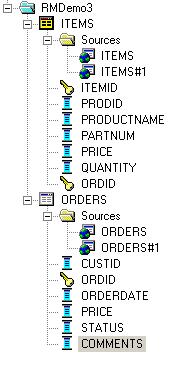
Now I need to tell BI Server that these data sources need to be combined, and what range of data they each provide. Starting first on the Items logical table and double-clicking on each data source, I first set the fragmentation condition for the SOADEMO-sourced table, like this:
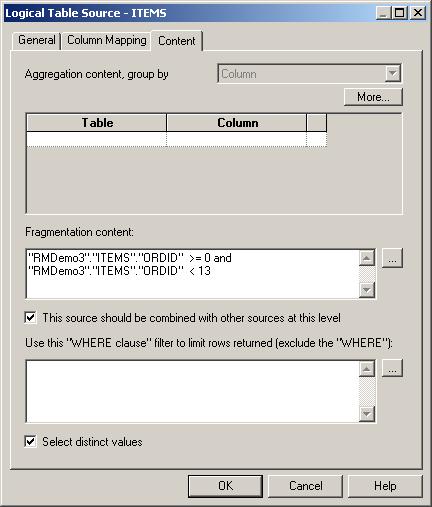
And do the same for the CUSTDW-sourced physical table, like this:
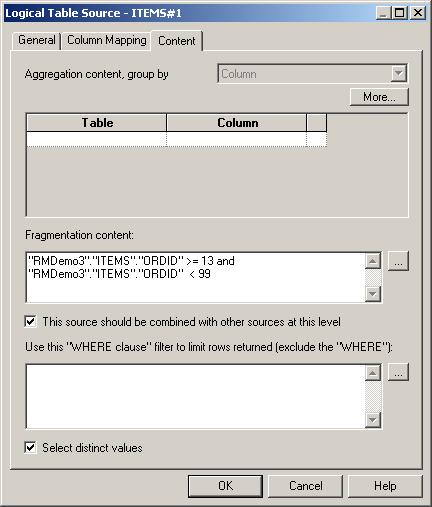
Then I do the same for the Orders tables, setting the Fragmentation content so the BI Server knows to combine the data and source from each table appropriately.
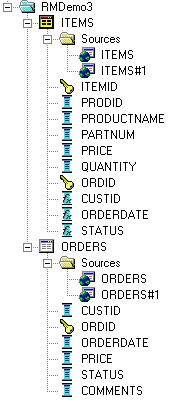
Next, as I want to remove the Orders table from the presentation layer and put all the order-related data in the items table, I create new Customer ID, Order Date and Status logical columns in the Items table, and base the values on the corresponding Orders logical columns, as I did yesterday, leaving me with a logical model looking like this:
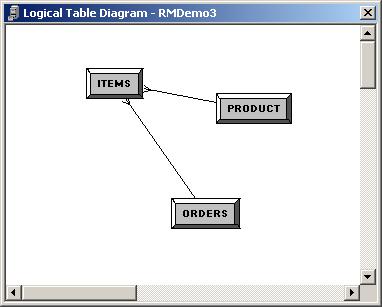
Now I add the product table in, firstly from the SOADEMO schema and then create a foreign key link between it and the logical Items table, so that I end up with a logical model diagram looking like this:
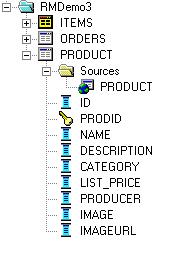
and a logical layer looking like this:
Next, I drop the CUSTDW Products table on top of the existing logical products table, to add another logical table source for each item within it, and then go to the logical table source properties to set the fragmentation content. In this case, I don't set a fragmentation condition, just tell BI Server to combine and distinct the values, as both sets of source tables contain the same data.
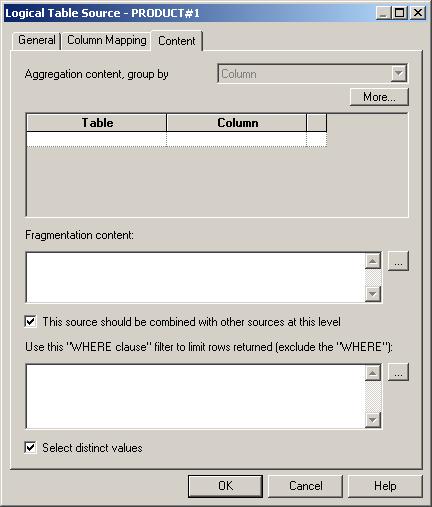
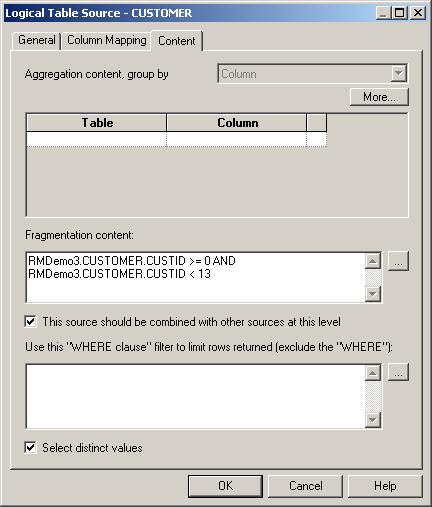
After running a quick Answers report to check that all is ok, I then drop the SOADEMO Customer table on to the logical area, join it to the Orders logical table, and then drop the CUSTDW version on top of it. I then set the fragmentation condition for the SOADEMO version, this time using the CUSTID column to define what data each fragment contains.
My logical data model now looks like this:
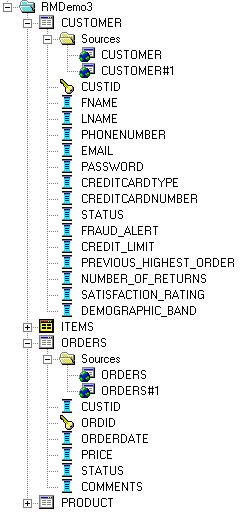
Note that some of the customer columns appeared when I dropped the CUSTDW version of the table on top of the SOADEMO version, as these columns only appear in the historical store of data.
Now, I've got a table within both SOADEMO and CUSTDW that contains address information and joins one-to-one to the Customer table in each schema. Starting with the SOADEMO schema, I therefore drag the CUSTID column from this new table on top of the existing logical Customer table, adding a new logical data source, and then do the same with the same table from the CUSTDW schema, and then drop on the address-related columns from this new table, first from the SOADEMO schema and then, on top of them, from the CUSTDW schema, and set the Fragmentation content for these new logical table sources to match the existing two Customer logical table sources, ending up with a logical model looking like this:
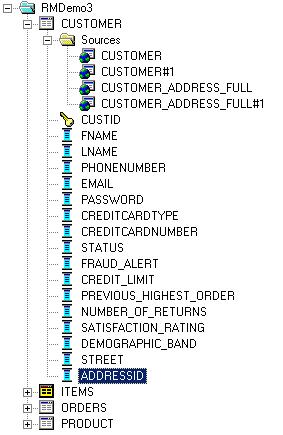
The more observant amongst you who read yesterday's article will have noticed that I collapsed the Customer_Address and Address tables into a single Customer_Address_All table - I just couldn't get fragmentation working with this more complex data model, that's not to say it's not possible, it's that for me it made more sense to simplify the source data a bit.
So, when the combined set of data is viewed in answers, the data from the SOADEMO schema representing new data, and the data from the CUSTDW schema representing historic data, is combined in the same report, like this:
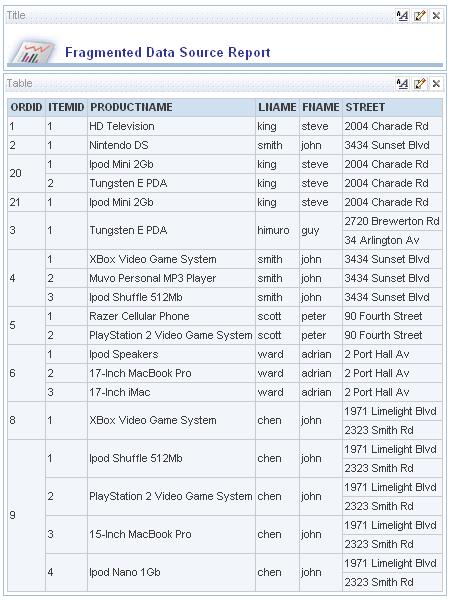
So, conclusions from this exercise? Well, it was quite tricky to set up (the docs don't make a lot of sense, it was pretty much trial and error) and the way you set your physical table joins up is very important, I spent a lot of time fiddling with this until it all lined up correctly. To be honest, if your data is all from an Oracle platform, you'd be better off just creating a view over the current and historic tables, using a UNION and getting the data out that way, but if your historic data is on one platform (say, an Oracle data warehouse) whilst your current data is on another, it's a good way of transparently combining the data. Tomorrow, if I get time, I'll take a look at ragged hierarchies.