Concurrent RPD Development in OBIEE

OBIEE is a well established product, having been around in various incarnations for well over a decade. The latest version, OBIEE 11g, was released 3.5 years ago, and there are mutterings of OBIEE 12c already. In all of this time however, one thing it has never quite nailed is the ability for multiple developers to work with the core metadata model - the repository, known as the RPD - concurrently and in isolation. Without this, development is doomed to be serialised - with the associated bottlenecks and inability to scale in line with the number of developers available.
My former colleague Stewart Bryson wrote a series of posts back in 2013 in which he outlines the criteria for a successful OBIEE SDLC (Software Development LifeCycle) method. The key points were :
- There should be a source control tool (a.k.a version control system, VCS) that enables us to store all artefacts of the BI environment, including RPD, Presentation Catalog, etc etc. From here we can tag snapshots of the environment at a given point as being ready for release, and as markers for rollback if we take a wrong turn during development.
- Developers should be able to do concurrent development in isolation.
- To do this, source control is mandatory in order to enable branch-based development, also known as feature-driven development, which is a central tenet of an Agile method.
Oracle’s only answer to the SDLC question for OBIEE has always been MUDE. But MUDE falls short in several respects:
- It only manages the RPD - there is no handling of the Presentation Catalog etc
- It does not natively integrate with any source control
- It puts the onus of conflict resolution on the developer rather than the “source master” who is better placed to decide the outcome.
Whilst it wasn’t great, it wasn't bad, and MUDE was all we had. Either that, or manual integration into source control (1, 2) tools, which was clunky to say the least. The RPD remained a single object that could not be merged or managed except through the Administration Tool itself, so any kind of automatic merge strategies that the rest of the software world were adopting with source control tools were inapplicable to OBIEE. The merge would always require the manual launching of the Administration Tool, figuring out the merge candidates, before slowly dying in despair at having to repeat such a tortuous and error-prone process on a regular basis…
Then back in early 2012 Oracle introduced a new storage format for the RPD. Instead of storing it as a single binary file, closed to prying eyes, it was instead burst into a set of individual files in MDS XML format.
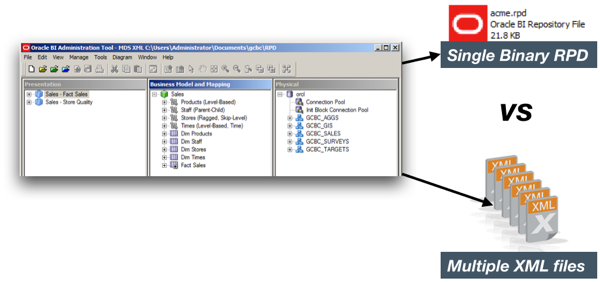
For example, one Logical Table was now one XML files on disk, made up of entities such as LogicalColumn, ExprText, LogicalKey and so on:

It even came with a set of configuration screens for integration with source control. It looked like the answer to all our SDLC prayers - now us OBIEE developers could truly join in with the big boys at their game. The reasoning went something like:
- An RPD stored in MDS XML is no longer binary
- git can merge code that is plain text from multiple branches
- Let’s merge MDS XML with git!
But how viable is MDS XML as a storage format for the RPD used in conjunction with a source control tool such as git? As we will see, it comes down to the Good, the Bad, and the Ugly…

The Good
As described here, concurrent and unrelated developments on an RPD in MDS XML format can be merged successfully by a source control tool such as git. Each logical object is an file, so git just munges (that’s the technical term) the files modified in each branch together to come up with a resulting MDS XML structure with the changes from each development in it.
The Bad
This is where the wheels start to come off. See, our automagic merging fairy dust is based on the idea that individually changed files can be spliced together, and that since MDS XML is not binary, we can trust a source control tool such as git to also work well with changes within the files themselves too.
Unfortunately this is a fallacy, and by using MDS XML we expose ourselves to greater complications than we would if we just stuck to a simple binary RPD merged through the OBIEE toolset. The problem is that whilst MDS XML is not binary, is not unstructured either. It is structured, and it has application logic within it (mdsid, of which see below).
Within the MDS XML structure, individual first-class objects such as Logical Tables are individual files, and structured within them in the XML are child-objects such as Logical Columns:

Source control tools such as git cannot parse it, and therefore do not understand what is a real conflict versus an unrelated change within the same object. If you stop and think for a moment (or longer) quite what would be involved in accurately parsing XML (let alone MDS XML), you’ll realise that you basically need to reverse-engineer the Administration Tool to come up with an accurate engine.
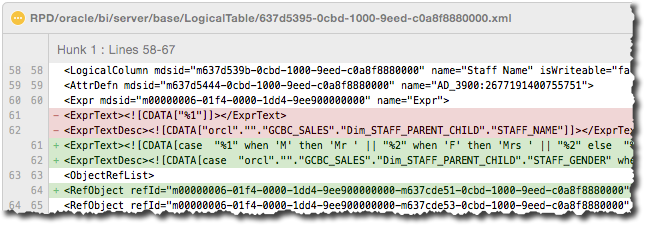
We kind of get away with merging when the file differences are within an element in the XML itself. For example, the expression for a logical column is changed in two branches, causing clashing values within ExprText and ExprTextDesc. When this happens git will throw a conflict and we can easily resolve it, because the difference is within the element(s) themselves:
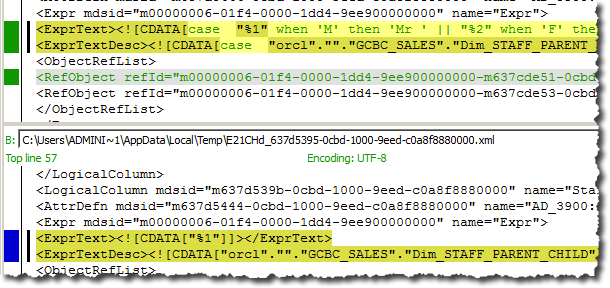
Easy enough, right?
But taking a similarly “simple” merge conflict where two independent developers add or modify different columns within the same Logical Table we see what a problem there is when we try to merge it back together relying on source control alone.
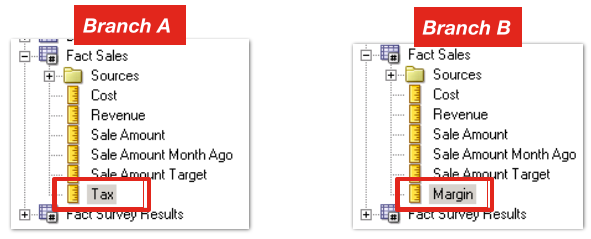
Obvious to a human, and obvious to the Administration Tool is that these two new columns are unrelated and can be merged into a single Logical Table without problem. In a paraphrased version of MDS XML the two versions of the file look something like this, and the merge resolution is obvious:
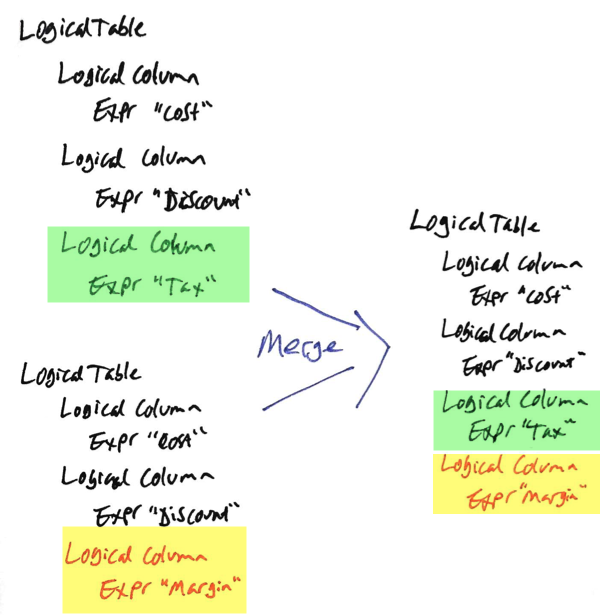
But a source control tool such as git looks as the MDS XML as a plaintext file, not understanding the concept of an XML tree and sibling nodes, and throws its toys out of the pram with a big scary merge conflict:
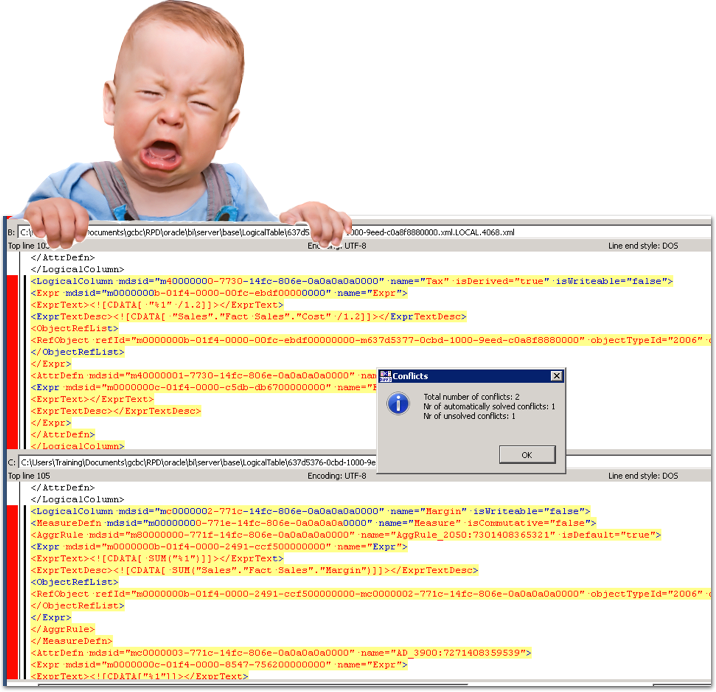
Now the developer has to roll up his or her sleeves and try to reconcile two XML files – with no GUI to support or validate the change made except loading it back into the Administration Tool each time.
So if we want to use MDS XML as the basis for merging, we need to restrict our concurrent developments to completely independent objects. But, that kind of hampers the ideal of more rapid delivery through an Agile method if we’re imposing rules and restrictions like this.
The Ugly
This is where is gets a bit grim. Above we saw that MDS XML can cause unnecessary (and painful) merge conflicts. But what about if two developers inadvertently create the same object concurrently? The behaviour we’d expect to see is a single resulting object. But what we actually get is both versions of the object, and a dodgy RPD. Uh Oh.
Here are the two concurrently developed RPDs, produced in separate branches isolated from each other:
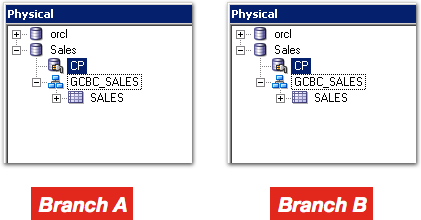
And here’s what happens when you leave it to git to merge the MDS XML:
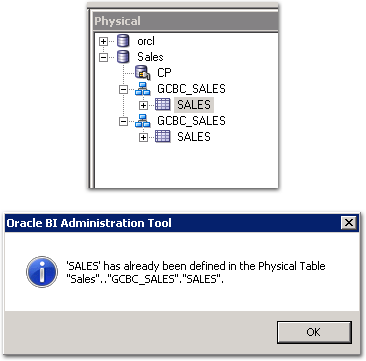
The duplicated objects now cannot be edited in the Administration Tool in the resulting merged RPD - any attempt to save them throws the above error.
Why does it do this? Because the MDS XML files are named after a globally unique identifier known as the mdsid, and not their corresponding RPD qualified name. And because the mdsid is unique across developments, two concurrent creations of the same object end up with different mdsid values, and thus different filenames.

Two files from separate branches with different names are going to be seen by source control as being unrelated, and so both are brought through in the resulting merge.
As with the unnecessary merge conflict above, we could define process around same object creation, or add in a manual equalise step. The issue really here is that the duplicates can arise without us being aware because there is no conflict seen by the source control tool. It’s not like merging an un-equalised repository in the Administration Tool where we’d get #1 suffixes on the duplicate object so that at least (a) we spot the duplication and (b) the repository remains valid and the duplicate objects available to edit.
MDS XML Repository opening times
Whether a development strategy based on MDS XML is for you or not, another issue to be aware of is that for anything beyond a medium sized RPD opening times of an MDS XML repository are considerable. As in, a minute from binary RPD, and 20 minutes from MDS XML. And to be fair, after 20 minutes I gave up on the basis that no sane developer would write off that amount of their day simply waiting for the repository to open before they can even do any work on it. This rules out working with any big repositories such as that from BI Apps in MDS XML format.
So is MDS XML viable as a Repository storage format?
MDS XML does have two redeeming features :
- It reduces the size of your source control repository, because on each commit you will be storing just a delta of the overall repository change, rather than the whole binary RPD each time.
- For tracking granular development progress and changes you can identify what was modified through the source control tool alone - because the new & modified objects will be shown as changes:
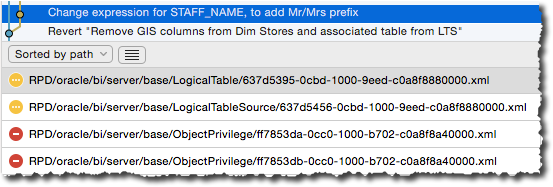
But the above screenshots both give a hint of the trouble in store. The mdsid unique identifier is used not only in filenames - causing object duplication and strange RPD behaviour- but also within the MDS XML itself, referencing other files and objects. This means that as a RPD developer, or RPD source control overseer, you need to be confident that each time you perform a merge of branches you are correctly putting Humpty Dumpty back together in a valid manner.
If you want to use MDS XML with source control you need to view it as part of a larger solution, involving clear process and almost certainly a hybrid approach with the binary RPD still playing a part -- and whatever you do, the Administration Tool within short reach. You need to be aware of the issues detailed above, decide on a process that will avoid them, and make sure you have dedicated resource that understands how it all fits together.
If not MDS XML, then what?…
Source control (e.g. git) is mandatory for any kind of SDLC, concurrent development included. But instead of storing the RPD in MDS XML, we store it as a binary RPD.
Wait wait wait, don’t go yet ! … it gets better
By following the git-flow method, which dictates how feature-driven development is done in source control (git), we can write a simple script that determines when merging branches what the candidates are for an OBIEE three-way RPD merge.
In this simple example we have two concurrent developments - coded “RM–1” and “RM–2”. First off, we create two branches which take the code from our “mainline”. Development is done on the two separate features in each branch independently, and committed frequently per good source control practice. The circles represent commit points:
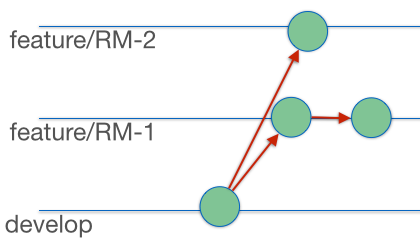
The first feature to be completed is “RM–1”, so it is merged back into “develop”, the mainline. Because nothing has changed in develop since RM–1 was created from it, the binary RPD file and all other artefacts can simply ‘overwrite’ what is there in develop:
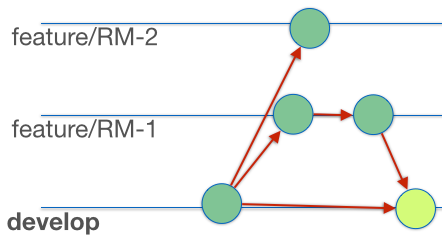
Now at this point we could take “develop” and start its deployment into System Test etc, but the second feature we were working on, RM–2, is also tested and ready to go. Here comes the fancy bit! Git recognises that both RM–1 and RM–2 have made changes to the binary RPD, and as a binary RPD git cannot try to merge it. But now instead of just collapsing in a heap and leaving it for the user to figure out, it makes use of git and the git-flow method we have followed to work out the merge candidates for the OBIEE Administration Tool:
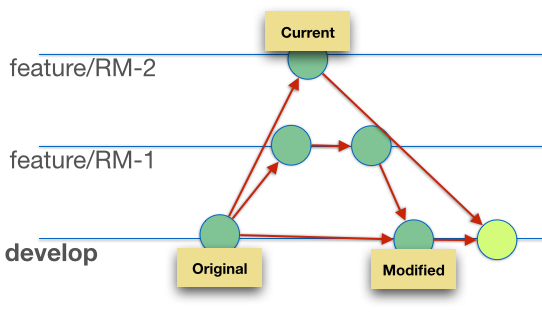
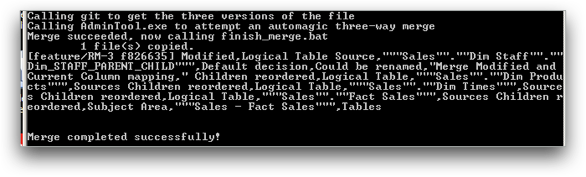
Even better, it invokes the Administration Tool (which can be run from the command line, or alternatively use command line tools comparerpd/patchrpd) to automatically perform the merge. If the merge is successful, it goes ahead with the commit in git of the merge into the “develop” branch. The developer has not had to do any kind of interaction to complete the merge and commit.
If the merge is not a slam-dunk, then we can launch the Administration Tool and graphically figure out the correct resolution – but using the already-identified merge candidates in order to shorten the process.
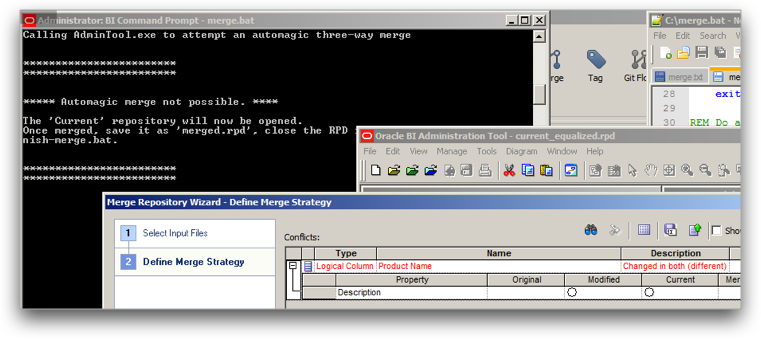
This is not perfect, but there is no perfect solution. It is the closest thing that there is to perfection though, because it will handle merges of :
- Unique objects
- Same objects, different modifications (c.f. two new columns on same table example above)
- Duplicate objects – by equalisation
Conclusion
There is no single right answer here, nor are any of the options overly appealing.
If you want to work with OBIEE in an Agile method, using feature-driven development, you will have to adopt and learn specific processes for working with OBIEE. The decision you have to make is on how you store the RPD (binary or multiple MDS XML files, or maybe both) and how you handle merging it (git vs Administration Tool).
My personal view is that taking advantage of git-flow logic, combined with the OBIEE toolset to perform three-way merges, is sufficiently practical to warrant leaving the RPD in binary format. The MDS XML format is a lovely idea but there are too few safeguards against dodgy/corrupt RPD (and too many unnecessary merge conflicts) for me to see it as a viable option.
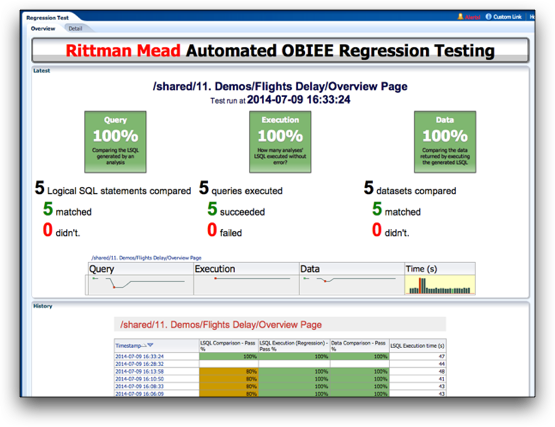
Whatever option you go for, make sure you are using regression testing to test the RPD after you merge changes together, and ideally automate the testing too. Here at Rittman Mead we’ve written our own suite of tools that do just this - get in touch to find out more.