SQL-on-Hadoop: Impala vs Drill

I recently wrote a blog post about Oracle's Analytic Views and how those can be used in order to provide a simple SQL interface to end users with data stored in a relational database. In today's post I'm expanding a little bit on my horizons by looking at how to effectively query data in Hadoop using SQL. The SQL-on-Hadoop interface is key for many organizations - it allows querying the Big Data world using existing tools (like OBIEE,Tableau, DVD) and skills (SQL).
Analytic Views, together with Oracle's Big Data SQL provide what we are looking for and have the benefit of unifying the data dictionary and the SQL dialect in use. It should be noted that Oracle Big Data SQL is licensed separately on top of the database and it's available for Exadata, SuperCluster, and 12c Linux Intel Oracle Databases machines only.
Nowadays there is a multitude of open-source projects covering the SQL-on-Hadoop problem. In this post I'll look in detail at two of the most relevant: Cloudera Impala and Apache Drill. We'll see details of each technology, define the similarities, and spot the differences. Finally we'll show that Drill is most suited for exploration with tools like Oracle Data Visualization or Tableau while Impala fits in the explanation area with tools like OBIEE.
As we'll see later, both the tools are inspired by Dremel, a paper published by Google in 2010 that defines a scalable, interactive ad-hoc query system for the analysis of read-only nested data that is the base of Google's BigQuery. Dremel defines two aspects of big data analytics:
- A columnar storage format representation for nested data
- A query engine
The first point inspired Apache Parquet, the columnar storage format available in Hadoop. The second point provides the basis for both Impala and Drill.
Cloudera Impala
We started blogging about Impala a while ago, as soon as it was officially supported by OBIEE, testing it for reporting on top of big data Hadoop platforms. However, we never went into the details of the tool, which is the purpose of the current post.
Impala is an open source project inspired by Google's Dremel and one of the massively parallel processing (MPP) SQL engines running natively on Hadoop. And as per Cloudera definition is a tool that:
provides high-performance, low-latency SQL queries on data stored in popular Apache Hadoop file formats.
Two important bits to notice:
- High performance and low latency SQL queries: Impala was created to overcome the slowness of Hive, which relied on MapReduce jobs to execute the queries. Impala uses its own set of daemons running on each of the datanodes saving time by:
- Avoiding the MapReduce job startup latency
- Compiling the query code for optimal performance
- Streaming intermediate results in-memory while MapReduces always writing to disk
- Starting the aggregation as soon as the first fragment starts returning results
- Caching metadata definitions
- Gathering tables and columns statistics
- Data stored in popular Apache Hadoop file formats: Impala uses the Hive metastore database. Databases and tables are shared between both components. The list of supported file formats include Parquet, Avro, simple Text and SequenceFile amongst others. Choosing the right file format and the compression codec can have enormous impact on performance. Impala also supports, since CDH 5.8 / Impala 2.6, Amazon S3 filesystem for both writing and reading operations.
One of the performance improvements is related to "Streaming intermediate results": Impala works in memory as much as possible, writing on disk only if the data size is too big to fit in memory; as we'll see later this is called optimistic and pipelined query execution. This has immediate benefits compared to standard MapReduce jobs, which for reliability reasons always writes intermediate results to disk.
As per this Cloudera blog, the usage of Impala in combination with Parquet data format is able to achieve the performance benefits explained in the Dremel paper.
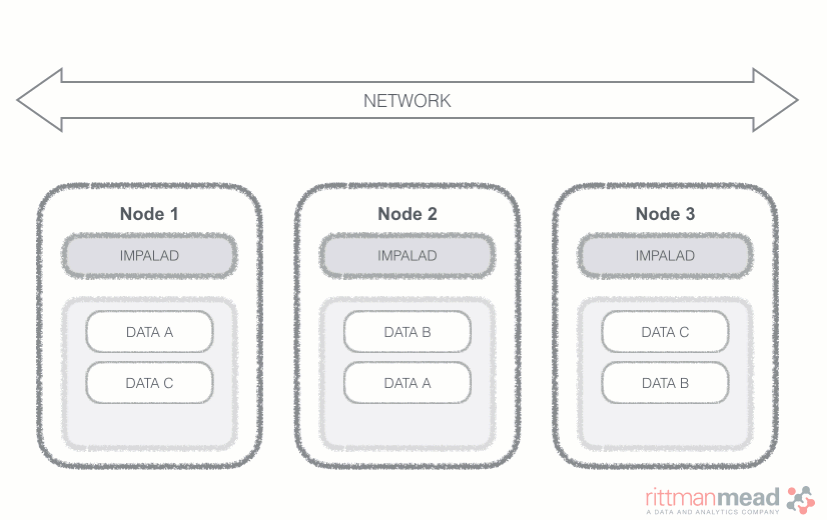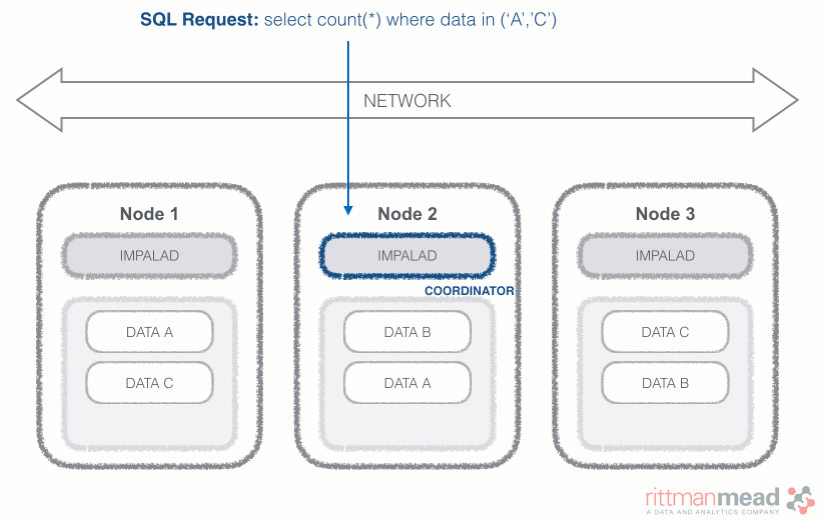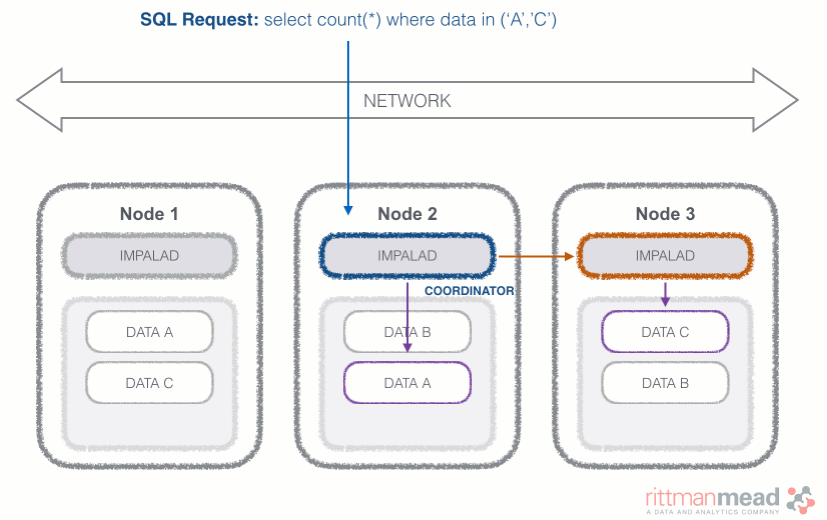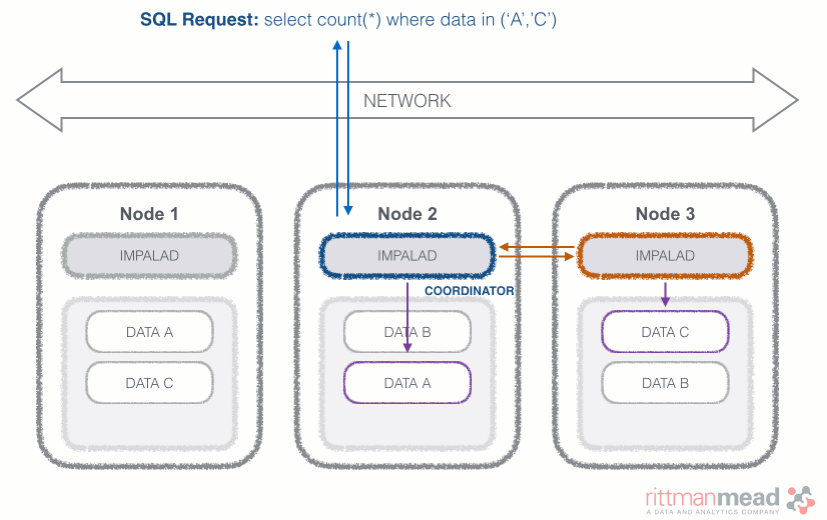
Impala Query Process
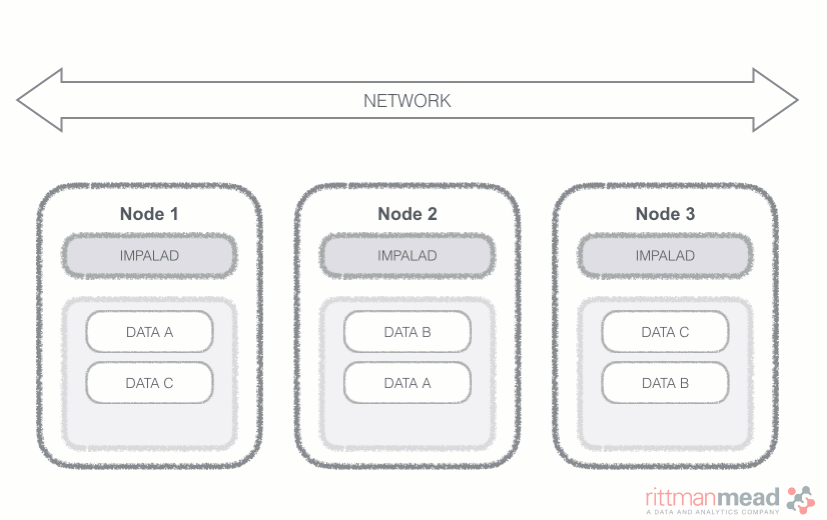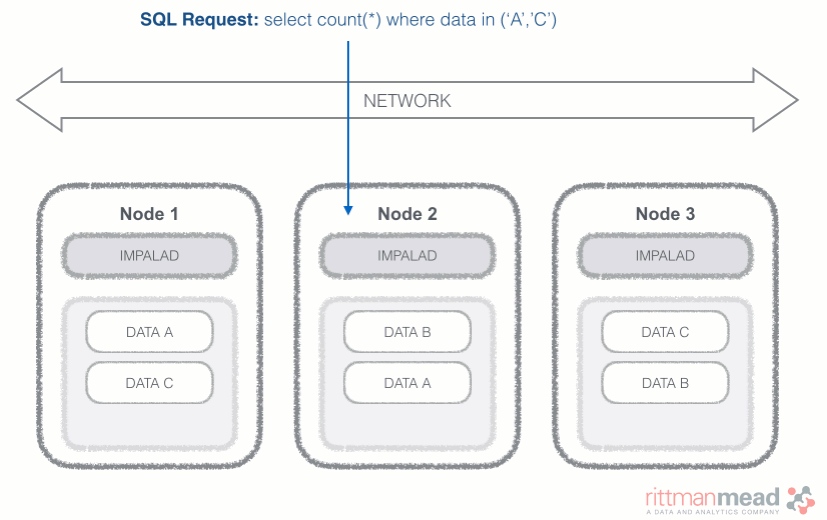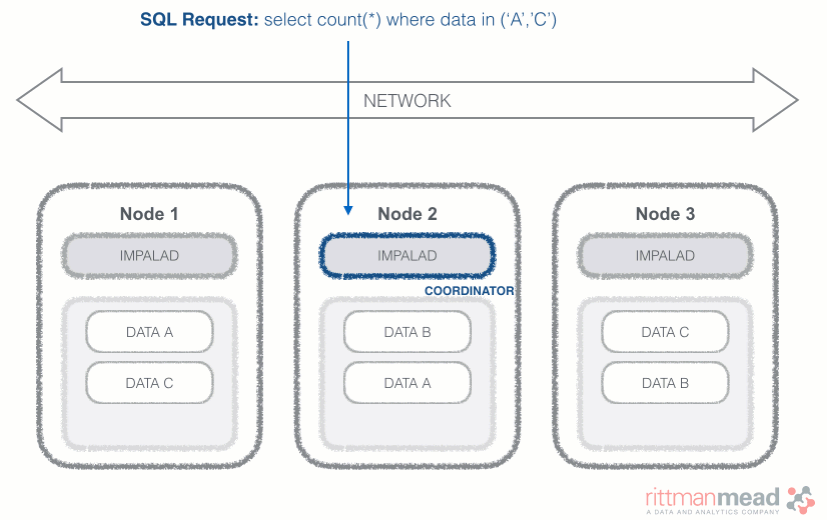
Impala runs a daemon, called impalad on each Datanode (a node storing data in the Hadoop cluster). The query can be submitted to any daemon in the cluster which will act as coordinator node for the query. Impala daemons are always connected to the statestore, which is a process keeping a central inventory of all available daemons and related health and pushes back the information to all daemons. A third component called catalog service checks for metadata changes driven by Impala SQL in order to invalidate related cache entries. Metadata are cached in Impala for performance reasons: accessing metadata from the cache is much faster than checking against the Hive metastore. The catalog service process is in charge of keeping Impala's metadata cache in sync with the Hive metastore.
Once the query is received, the coordinator verifies if the query is valid against the Hive metastore, then information about data location is retrieved from the Namenode (the node in charge of storing the list of blocks and related location in the datanodes), it fragments the query and distribute the fragments to other impalad daemons to execute the query. All the daemons read the needed data blocks, process the query, and stream partial result to the coordinator (avoiding the write to disk), which collects all the results and delivers it back to the requester. The result is returned as soon as it's available: certain SQL operations like aggregations or order by require all the input to be available before Impala can return the end result, while others, like a select of pre-existing columns without a order by can be returned with only partial results.
 # Apache Drill
Defining [Apache Drill](https://drill.apache.org) as SQL-on-Hadoop is limiting: also inspired by [Google's Dremel](https://research.google.com/pubs/pub36632.html) is a distributed **datasource agnostic** query engine. The datasource agnostic part is very relevant: Drill is not closely coupled with Hadoop, in fact it can query a variety of sources like MongoDB, Azure Blob Storage, or Google Cloud Storage amongst others.
# Apache Drill
Defining [Apache Drill](https://drill.apache.org) as SQL-on-Hadoop is limiting: also inspired by [Google's Dremel](https://research.google.com/pubs/pub36632.html) is a distributed **datasource agnostic** query engine. The datasource agnostic part is very relevant: Drill is not closely coupled with Hadoop, in fact it can query a variety of sources like MongoDB, Azure Blob Storage, or Google Cloud Storage amongst others.
One of the most important features is that data can be queried schema-free: there is no need of defining the data structure or schema upfront - users can simply point the query to a file directory, MongoDB collection or Amazon S3 bucket and Drill will take care of the rest. For more details, check our overview of the tool. One of Apache Drill's objectives is cutting down the data modeling and transformation effort providing a zero-day analysis as explained in this MapR video.
Drill is designed for high performance on large datasets, with the following core components:
- Distributed engine: Drill processes, called Drillbits, can be installed in many nodes and are the execution engine of the query. Nodes can be added/reduced manually to adjust the performances. Queries can be sent to any Drillbit in the cluster that will act as Foreman for the query.
- Columnar execution: Drill is optimized for columnar storage (e.g. Parquet) and execution using the hierarchical and columnar in-memory data model.
- Vectorization: Drill take advantage of the modern CPU's design - operating on record batches rather than iterating on single values.
- Runtime compilation: Compiled code is faster than interpreted code and is generated ad-hoc for each query.
- Optimistic and pipelined query execution: Drill assumes that none of the processes will fail and thus does all the pipeline operation in memory rather than writing to disk - writing on disk only when memory isn't sufficient.
Drill Query Process
Like Impala's impalad, Drill's main component is the Drillbit: a process running on each active Drill node that is capable of coordinating, planning, executing and distributing queries. Installing Drillbit on all of Hadoop's data nodes is not compulsory, however if done gives Drill the ability to achieve the data locality: execute the queries where the data resides without the need of moving it via network.
When a query is submitted against Drill, a client/application is sending a SQL statement to a Drillbit in the cluster (any Drillbit can be chosen), which will act as Foreman (coordinator in Impala terminology) that will parse the SQL and convert it into a logical plan composed by operators. The next step is the cost-based optimizer which, based on optimizations like rule/cost based, data locality and storage engine options, rearranges operations to generate the optimal physical plan. The Foreman then divides the physical plan in phases, called fragments, which are organised in a tree and executed in parallel against the data sources. The results are then sent back to the client/application. The following image taken from drill.apache.org explains the full process:

Similarities and Differences
As we saw above, Drill and Impala have a similar structure - both take advantage of always on daemons (faster compared to the start of a MapReduce job) and assume an optimistic query execution passing results in cache. The code compilation and the distributed engine are also common to both, which are optimized for columnar storage types like Parquet.
There are, however, several differences. Impala works only on top of the Hive metastore while Drill supports a larger variety of data sources and can link them together on the fly in the same query. For example, implicit schema-defined files like JSON and XML, which are not supported natively by Impala, can be read immediately by Drill.
Drill usually doesn't require a metadata definition done upfront, while for Impala, a view or external table has to be declared before querying. Following this point there is no concept of a central and persistent metastore, and there is no metadata repository to manage just for Drill. In OBIEE's world, both Impala and Drill are supported data sources. The same applies to Data Visualization Desktop.
The aim of this article isn't a performance-wise comparison since those depends on a huge amount of factors including data types, file format, configurations, and query types. A comparison dated back in 2015 can be found here. Please be aware that there are newer versions of the tools since this comparison, which bring a lot of changes and improvements for both projects in terms of performance.
Conclusion
Impala and Drill share a similar structure - both inspired by Google's Dremel - relying on always active daemons deployed on cluster nodes to provide the best query performances on top of Big Data data structures. So which one to choose and when?
As described, the capability of Apache Drill to query a raw data-source without requiring an upfront metadata definition makes the tool perfect for insights discovery on top of raw data. The capacity of joining data coming from one or more storage plugins in a unique query makes the mash-up of disparate data sources easy and immediate. Data science and prototyping before the design of a reporting schema are perfect use cases of Drill. However, as part of the discovery phase, a metadata definition layer is usually added on top of the data sources. This makes Impala a good candidate for reporting queries.
Summarizing, if all the data points are already modeled in the Hive metastore, then Impala is your perfect choice. If instead, you need a mashup with external sources, or need work directly with raw data formats (e.g. JSON), then Drill's auto-exploration and openness capabilities are what you're looking for.
Even though both tools are fully compatible with Oracle BIEE and Data Visualization (DV), due to Drill's data exploration nature, it could be considered more in line with DV use cases, while Impala is more suitable for standard reporting like OBIEE. The decision on tooling highly depends on the specific use case - source data types, file formats and configurations have deep impact on the agility of the business analytics process and query performance.
If you want to know more about Apache Drill, Impala and the use cases we have experienced, don't hesitate to contact us!