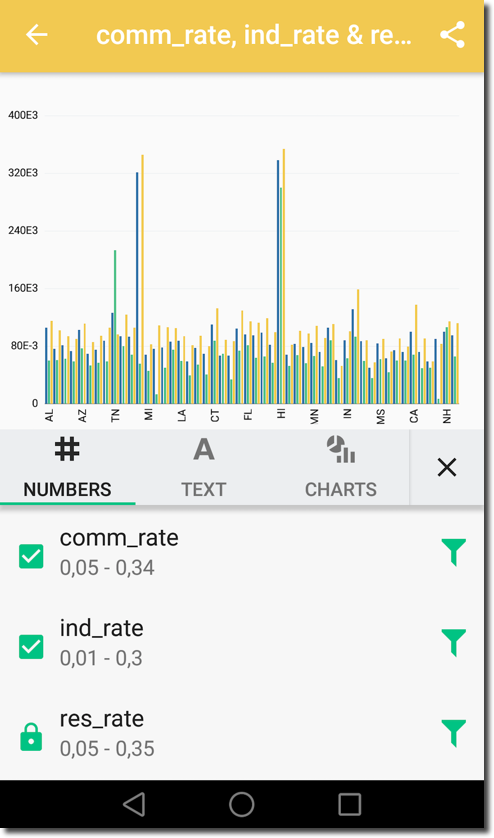
On and off over the last year, I have spent some time developing a customisable
framework for building visualisations and dashboards, using OBIEE as the
back-end. The result is Insights, a JavaScript web application that offers a
modern alternative to OBIEE Answers. As of today, we have officially open
sourced